[Github]
[arXiv](Current version v1)
Abstract
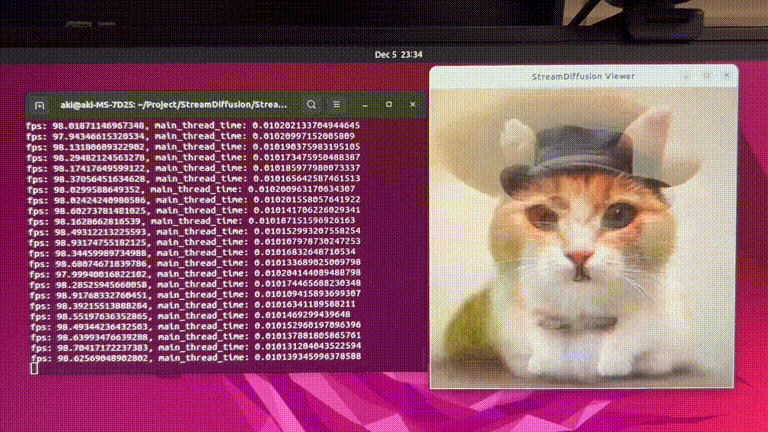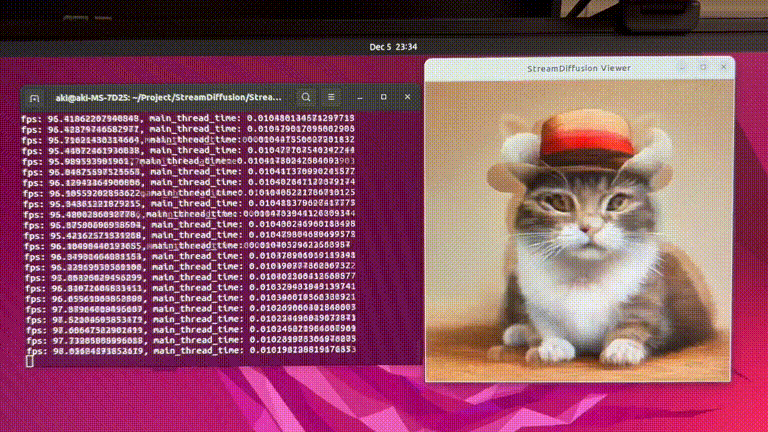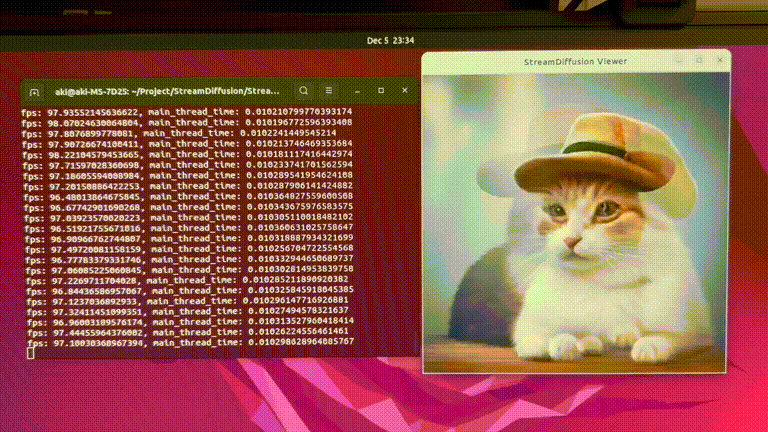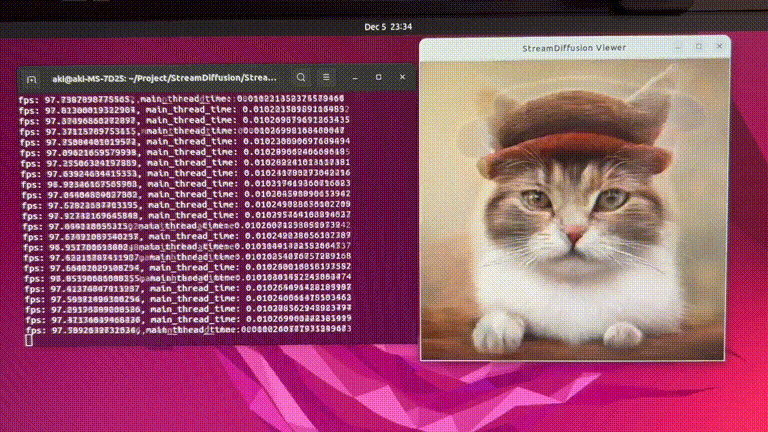
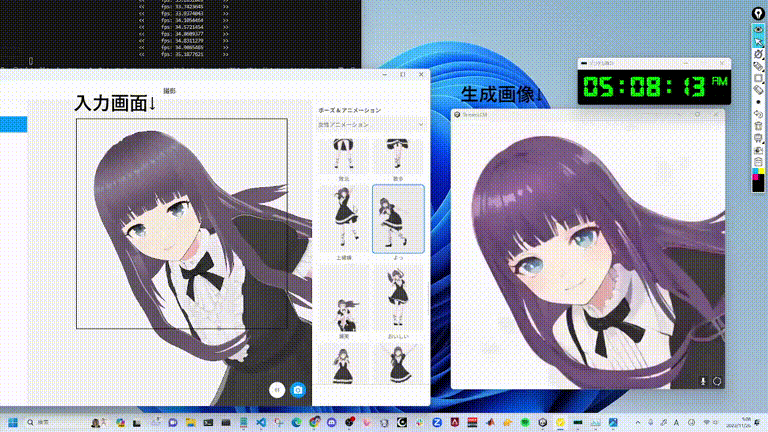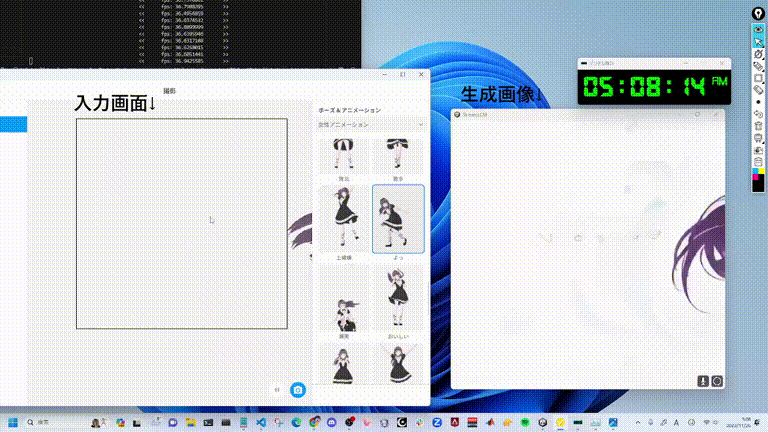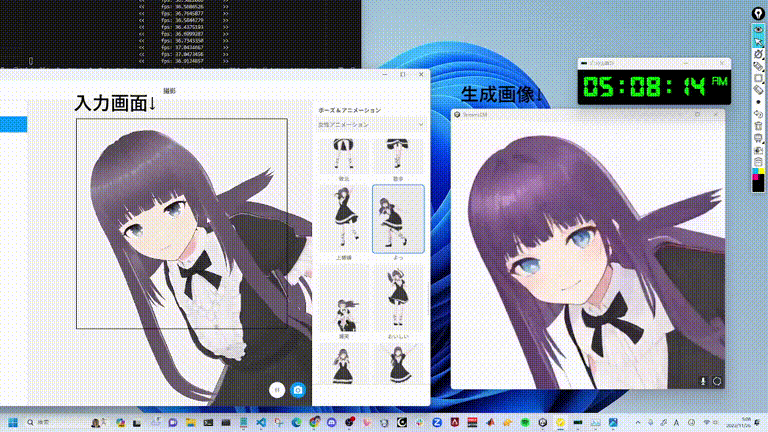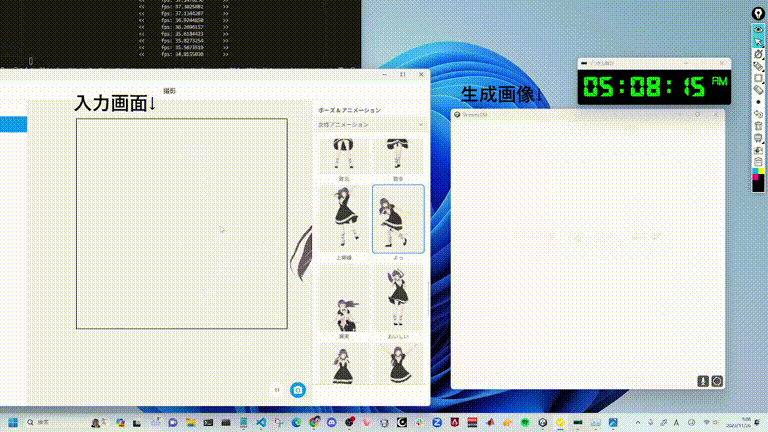
RTX 4090 GPU에서 최대 91.07 fps로 이미지를 생성할 수 있는 StreamDiffusion 제안
StreamDiffusion Pipeline
- Stream Batch
- Residual Classifier-Free Guidance
- Input-Output Queue
- Stochastic Similarity Filter
- Pre-Computation
- Model Acceleration Tools with a Tiny-Autoencoder
Batching the denoise step
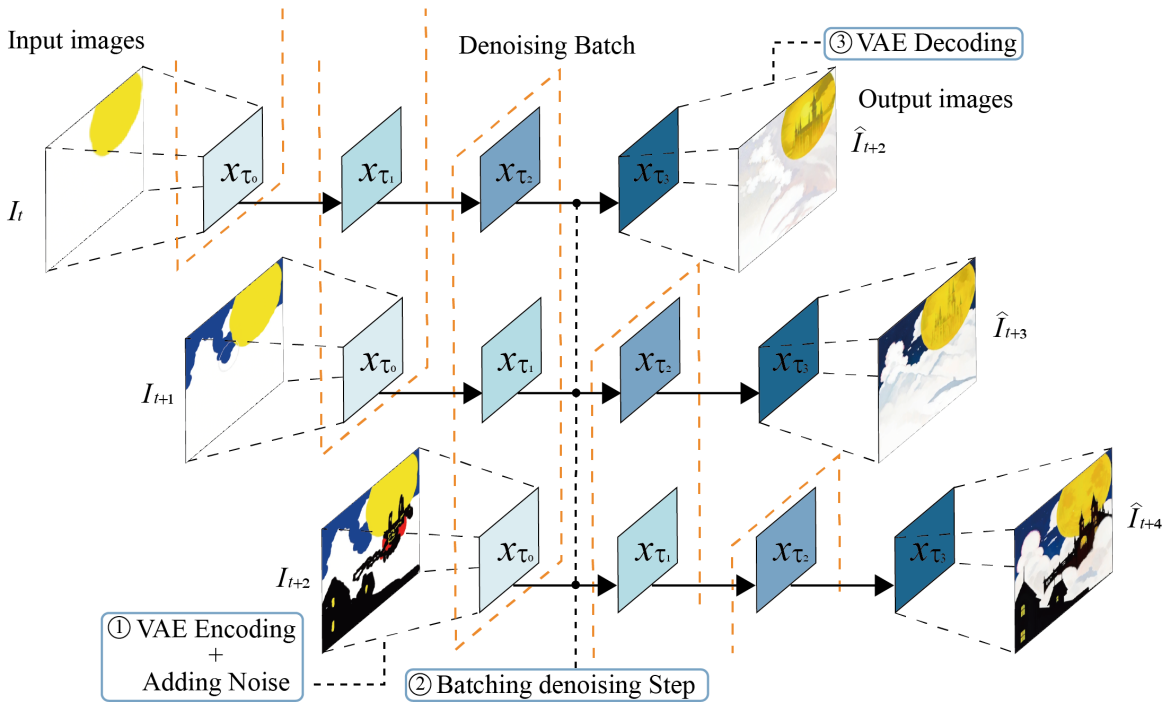
위 그림과 같이 stream batch를 사용하여 이전 이미지의 생성이 끝날 때까지 기다리지 않고 새로운 이미지 생성을 시작할 수 있다. 추론 시간-품질의 trade-off에서 VRAM 용량-품질의 trade-off로 전환.
Residual Classifier-Free Guidance
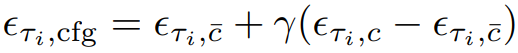
Negative conditioning c̄의 계산 비용을 크게 줄이는 Residual Classifier-Free Guidance(RCFG)를 제안한다.
먼저, 인코딩된 input latent x0는 noise distribution xτ0로 전달될 수 있고
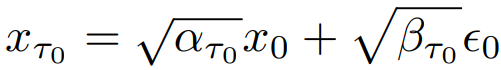
latent consistency model(LCM)을 통해 xτi-1에서 x̂0,τi-1을 예측하고 xτi를 생성할 수 있다.
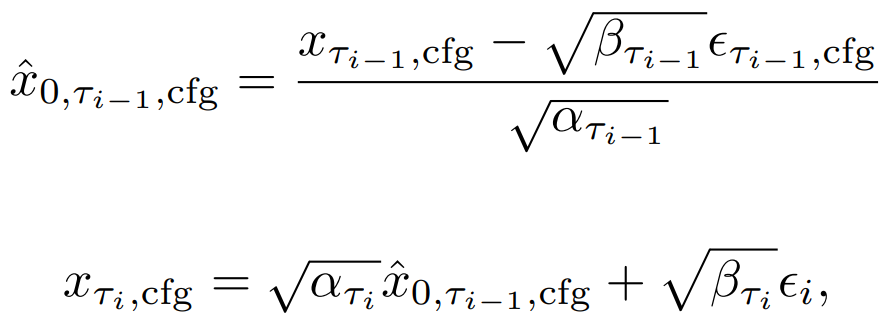
이때, 중복성이 높고 추가 U-Net계산이 필요한 CFG의 negative conditioning c̄를 계산하는 대신에, 다음과 같이 가상의 잔차 노이즈 ϵτi,c̄'과 xτi,cfg에서 x0를 예측할 수 있는 가상의 negative condition embedding c̄'을 가정한다.
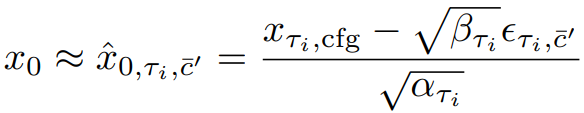
다음과 같이 정리할 수 있고
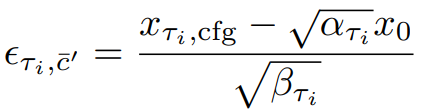
다음과 같이 Self-Negative RCFG를 정의한다.
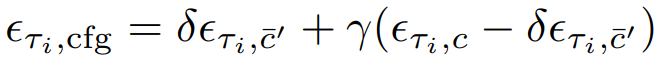
정리하자면 x0가 주어질 때, U-Net을 2번 계산하는 대신 쉽게 구할 수 있는 x0와 xτ의 잔차인 c̄'을 negative condition으로 사용하는 방법이다.
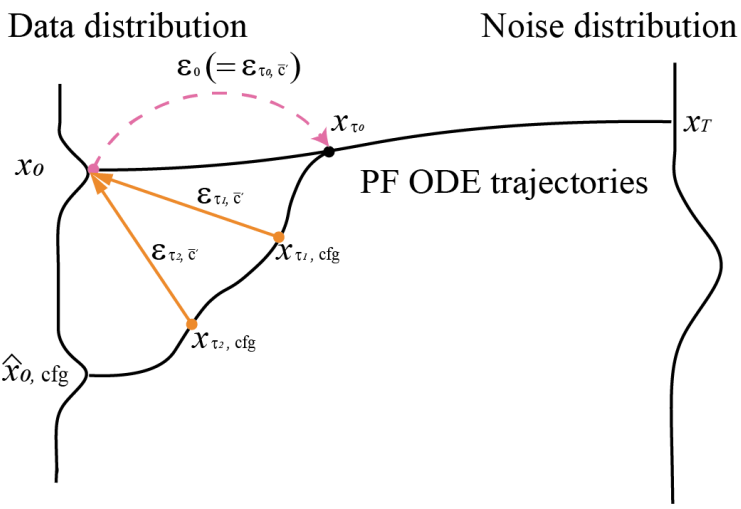
Onetime-Negative RCFG: x0 뿐만 아니라 진짜 negative condition의 분포와도 멀어지기 위해 denoising의 첫 step에서만 negative condition residual noise ϵτ0,c̄를 계산한다.
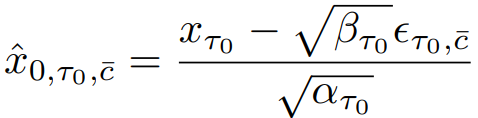
Self-Negative RCFG + Onetime-Negative RCFG:
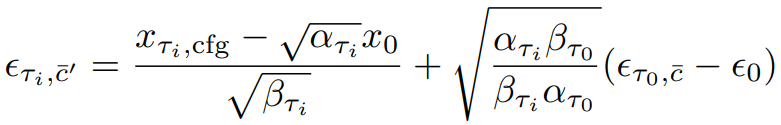
Onetime-negative residual을 timestep마다 negative noise에 더하는 듯.
Residual(xτi,cfg ↔ x0) + Residual (x0 ↔ negative condition)은 결국 residual(xτi,cfg ↔ negative condition)과 같기 때문에 작동하는 것으로 보인다.
CFG의 2n 계산이 n+1로 줄었다.
Input-Output Queue
사람의 입력과 모델 처리량의 빈도 차이를 해결하기 위해 이미지 전처리, 후처리를 pipeline 외부로 이동하여 병렬로 처리한다.

크기 조정, 텐서 변환, 정규화 등의 전처리를 마친 텐서는 입력 Queue에 대기하고, 출력은 출력 Queue에 대기하여 병렬로 처리됨.
Stochastic Similarity Filter
연속 입력과 관련된 정적인 시나리오에서 거의 동일한 이미지가 반복적으로 입력될 때, 불필요한 resource 소모를 방지하기 위해 SSF 제안.
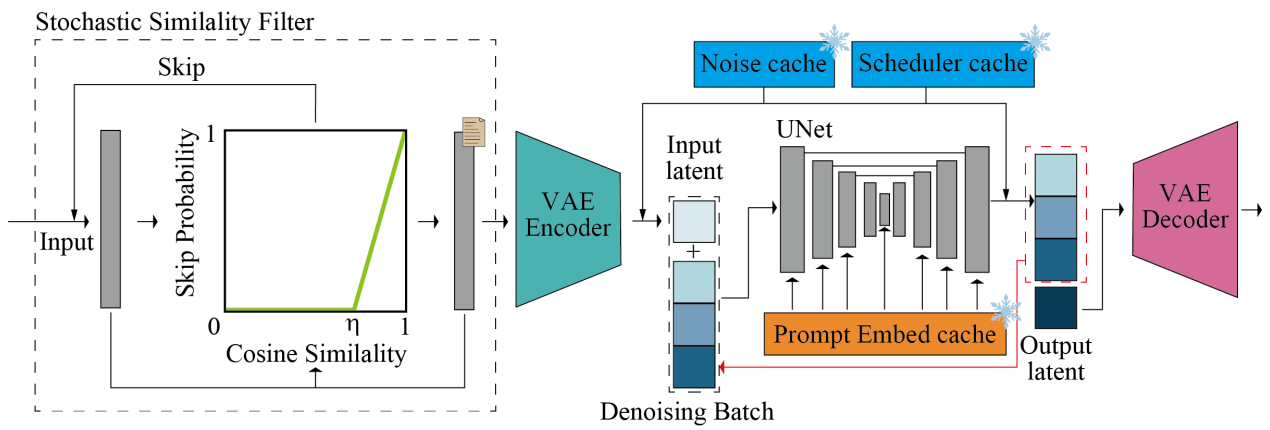
현재 입력과 과거 참조와의 코사인 유사도를 계산하여 process를 skip 할 확률을 결정한다.
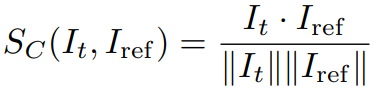
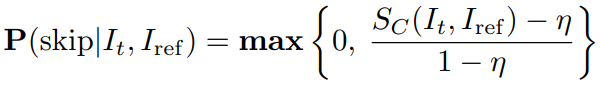
이 방법은 hard threshold에 비해 훨씬 부드러운 비디오를 생성하면서 GPU를 절약할 수 있다.
Pre-computation
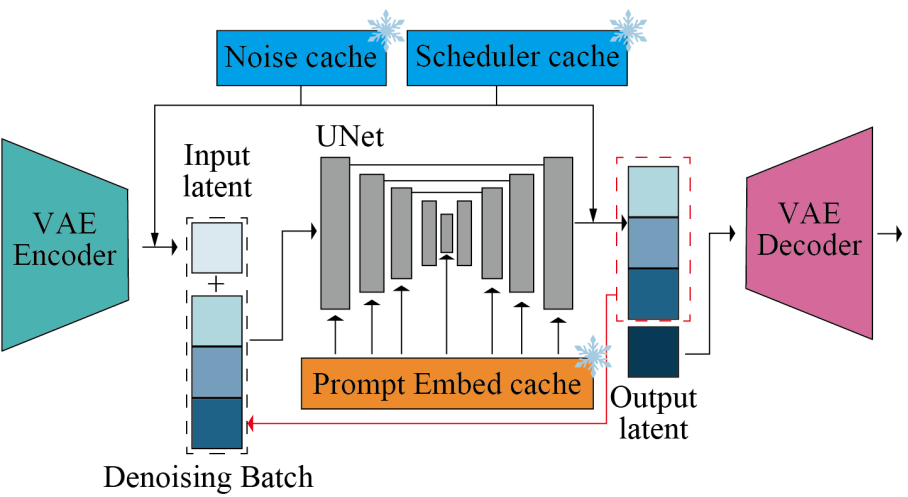
각 timestep에서 쓰일 노이즈를 미리 생성하고 캐시에 저장. 다른 프레임의 모든 같은 timestep에서 같은 노이즈를 사용한다.
Prompt embedding과 noise schedule 미리 계산하고 캐시에 저장.
Model Acceleration and Tiny AutoEncoder
NVIDIA의 toolkit인 TensorRT를 사용하여 추론 속도 가속화.
기존의 Stable diffusion encoder 대신 경량 autoencoder 사용.
Experiments