[arXiv](Current version v1)
 |
 |
 |
 |
 |
 |
Abstract
Human feedback을 통해 text-to-video 확산 모델을 fine-tuning 하는 InstructVideo 제안
InstructVideo

Reward Fine-tuning as Editing
우리의 목표는 출력을 크게 변경하는 것이 아니라 인간의 선호에 따라 미묘하게 조정하는 것이다.
입력 video-text pair (x, c)에 대해 x를 잠재 latent z로 추출하고 적당한 노이즈를 더한 다음(SDEdit) DDIM sampling step D의 일부(τ) 만큼 denoising 하여 z0을 얻은 후 x0g로 디코딩한다.
Reward Fine-tuning with Image Reward Models
인간 선호도 데이터셋을 제작하는 것은 매우 비용이 높기 때문에 기성 이미지 보상 모델을 활용한다.
생성된 비디오 x0g를 각 segment로 나누고 프레임을 균일하게 샘플링하여 보상 r을 집계한다.

하지만 평균 집계는 artifact를 유발한다. 따라서 중심 프레임에서 멀어질수록 보상을 감소시키는 계수를 도입한다.


보상과 최적화 목표 정의:

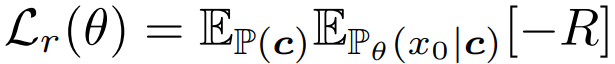
Reward Fine-tuning and Inferenc
Reward fine-tuning
Baseline: ModelScopeT2V
Reward model: HPSv2
LoRA 사용
Classifier-free guidance
Gradient checkpointing을 통해 마지막 DDIM step만 역전파하여 훈련을 가속화함.
Experiments
Comparison with the base model ModelScopeT2V

Generalization to unseen text prompts
Fine-tuning dataset에 존재하지 않는 prompt에 대한 결과도 좋아졌다.

The evolution of generated videos during fine-tuning




