Text encoder를 설계하여 텍스트 합성에 특화
[Github]
[arXiv](Current version v1)

Abstract
사전 훈련된 확산 모델과 경량 텍스트 인코더를 통해 높은 정확도로 텍스트를 합성할 수 있는 UDiffText 제안
Method
Character-level Text Encoder
CLIP, T5와 같은 텍스트 인코더는 개별 문자의 구조를 인식하지 못한다.
새로운 텍스트 인코더는 다음과 같다.

해당 단어는 인덱스에 매핑된 다음 코드북을 통해 임베딩으로 변환되고 transformer를 거쳐 최종 출력을 생성한다.
Multi-label classification head HMLC는 텍스트 임베딩에서 text index Id를 예측하도록 cross-entropy를 통해 훈련된다.
Visual feature를 얻기 위해 텍스트 인식기 ViTSTR을 이미지 인코더로 활용하고 코사인 유사도를 통해 cross-modal feature를 정렬한다.

Training Strategy
Stable Diffusion 2.0의 Inpainting 변형을 기반으로 구축한다.

확산 모델은 노이즈가 추가된 이미지 x0 + n,
마스크 M,
마스크의 반전 영역으로 마스킹된 이미지 XM,
텍스트 T를 입력으로 받는다.
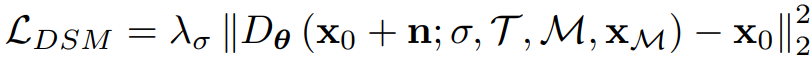
L2 거리가 문자 표현의 정확성이 아닌 픽셀 간의 거리에서 기인하기 때문에 DSM 손실로는 부족하다.
먼저 cross-attention에서 attention map Ai를 얻고

Attention map에서 각 문자의 관심 영역과 dataset의 character segmentation map S의 supervision을 활용하여 local attention loss를 계산할 수 있다.

(C = cross-attention blocks, G = 관심 영역의 과도한 변화를 제한하는 Gaussian blur, J = all ones matrix)
사전 훈련된 텍스트 인식 모델을 사용하여 렌더링 된 단어의 정확성을 측정.

Cross-attention의 피라미터를 제외하고 나머지 가중치는 동결한 Stable Diffusion에서 훈련한다.

Refinement of Noised Latent
이 모든 과정에도 불구하고 여전히 모델은 일부 문자를 누락시킨다.
각 문자의 attention map의 값을 최대화하기 위한 추가 손실 함수:
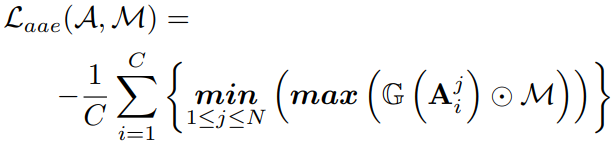
먼저 Gaussian noise를 N번 샘플링하고 denoising을 진행한 뒤 마지막 timestep에서 Laae를 계산한다.
가장 낮은 손실 값을 가지는 노이즈를 초기 노이즈로 선택하고 각 timestep t에서 Laae를 기반으로 Euler’s method를 이용해 denoising 한다.

Experiments

UDiffText | Home
Text-to-Image (T2I) generation methods based on diffusion model have garnered significant attention in the last few years. Although these image synthesis methods produce visually appealing results, they frequently exhibit spelling errors when rendering tex
udifftext.github.io



