[Github]
[arXiv](Current version v1)

Abstract
Decoupled cross-attention을 통해 image feature를 분리하여 prompting 하는 IP-adapter 제안
Method
Image Prompt Adapter
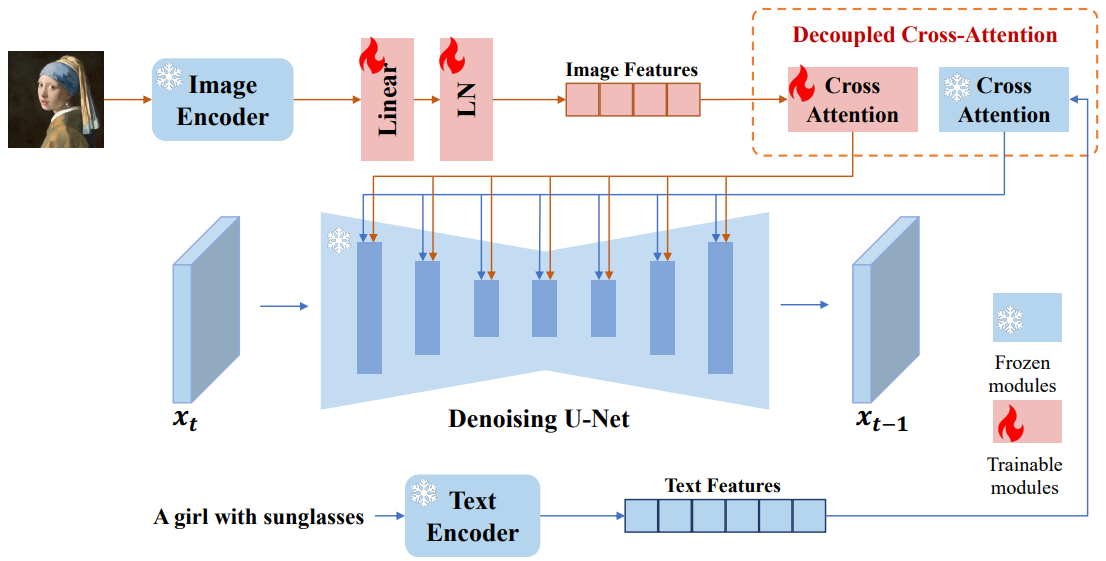
Image Encoder
CLIP image encoder의 출력을 projection layer를 통해 길이 N, 텍스트 임베딩과 같은 차원을 가진 feature로 투영.
Decoupled Cross-Attention
Text embedding과 image embedding을 통합하는 대신 새로운 cross-attention layer를 추가하고 같은 Query에 대해 수행된 각각의 cross-attention layer의 출력을 더한다.

U-Net에서 훈련 가능한 가중치는 W'k, W'v.
Training and Inference
Simple loss:

Classifier-free guidance:

추론 시 image condition의 가중치를 조절할 수 있다.
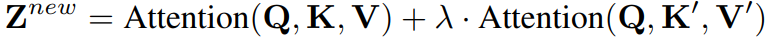
Experiments
Results
IP-Adapter
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models Hu Ye Jun Zhang Sibo Liu Xiao Han Wei Yang Tencent AI Lab Various image synthesis with our proposed IP-Adapter applied on the pretrained text-to-image diffusion model and a
ip-adapter.github.io
Comparison of Fine-grained Features and Global Features
CLIP의 global feature는 세부 사항을 포착하지 못하기 때문에 fine-grained IP-adapter를 설계한다.
CLIP image encoder의 끝에서 두 번째 layer에서 feature를 추출하여 16개의 학습 가능한 토큰이 있는 경량 transformer인 query network를 훈련한다.
Fine-grained IP-adapter는 image prompt의 구조를 더 잘 보존하지만 다양성이 떨어지는 경향이 있다.




