Sparse Condition Encoder를 통해 sparse signal로 제어 가능한 비디오 생성
[Github]
[arXiv](Current version v1)
 |
 |
|
 |
 |
 |
Abstract
최근 Text-to-Video 분야는 크게 발전했다. 하지만 text prompt에만 의존하면 제어가 힘들고, dense signal은 추론 비용에 부담이 된다. 이러한 문제를 해결하기 위해 sparse signal을 통해 유연한 제어를 가능하게 하는 SparseCtrl을 제안한다.
SparseCtrl
- T2V Diffusion Model
- Sparse Condition Encoder
- Application
Text-to-Video Diffusion Models
일반적인 최근의 T2V 모델은 공간 계층 뒤에 시간 계층을 추가하여 사전 훈련된 T2I 모델을 확장한다.

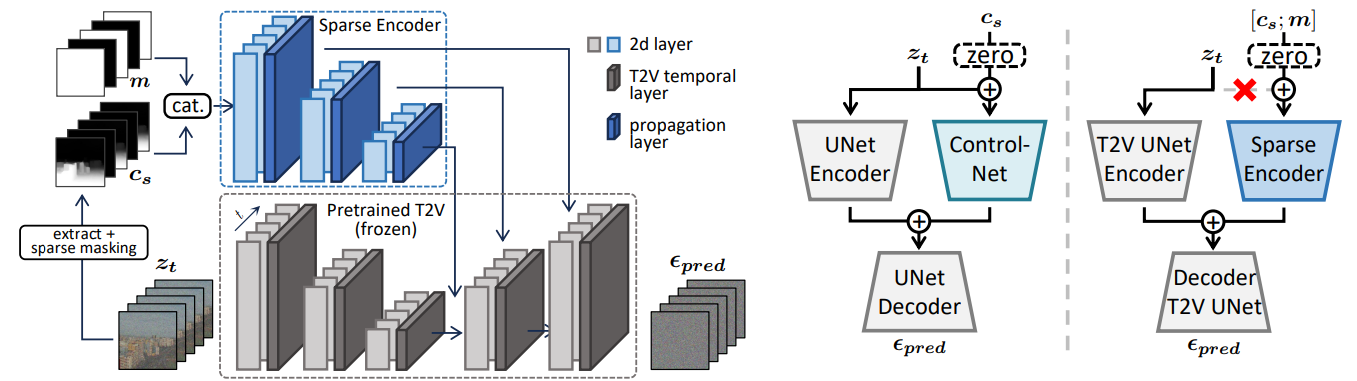
Sparse Condition Encoder
ControlNet에서 영감을 받아 비슷한 구조의 Sparse Condition Encoder 설계.
Condition propagation across frames
ControlNet에 시간 계층을 추가한 유사한 구조.
Quality degradation caused by manually noised latents
ContorlNet은 zt와 condition을 입력으로 받으며, ControlNet의 출력은 원본 모델의 잔차로써 작용한다.
하지만 이러한 방법을 Sparse Encoder에 적용할 경우 문제가 발생한다. zt는 높은 시간 단계에서 순수한 노이즈에 가까우며, 조건화되지 않은 프레임에서는 오히려 인코더의 예측을 방해만 할 뿐이다. 따라서 Sparse Encoder에서는 zt를 입력으로 받지 않음.
Unifying sparsity via masking
또한 위 그림의 맨 왼쪽에서 보이듯이 마스크 m을 추가적으로 입력해 조건화된 프레임과 그렇지 않은 프레임을 구분한다.
Multiple Modalities and Applications
Sketch-to-video generation

Depth guided generation

Image animation and transition; video prediction and interpolation

Experiments
개인화된 Stable Diffusion에서 비디오를 생성할 수 있는 AnimateDiff 위에 SparseCtrl을 구현한다.
SparseCtrl
SparseCtrl: Adding Sparse Controls to Text-to-Video Diffusion Models Yuwei Guo1 Ceyuan Yang2† Anyi Rao3 Maneesh Agrawala3 Dahua Lin1,2 Bo Dai2 †Corresponding Author. 1The Chinese University of Hong Kong 2Shanghai Artificial Intellgence Laboratory 3Stan
guoyww.github.io



