[Github]
[arXiv](Current version v1)
 |
A winged dog flying over the city.
|
 |
A cute kitten in the grass, 3D cartoon.
|
 |
 |
||
 |
A paper craft art depicting a girl giving her cat a gentle hug. Both sit amidst potted plants, with the cat purring contentedly while the girl... |  |
In a rice field , a girl walks toward the eye of the storm with her back to the camera.
|
 |
 |
||
Abstract
의미론과 질적 향상을 분리한 cascade 구조로 비디오를 생성하는 I2VGen-XL 제안
I2VGen-XL
Preliminaries
잠재 인코더는 VideoComposer의 VQGAN을 활용한다.
VideoComposer와 같은 3D U-Net을 사용.

I2VGen-XL
I2VGen-XL의 목적은 정적 이미지에서 비디오를 생성하는 것이다. 이를 달성하기 위해 2-stage 전략을 사용한다.
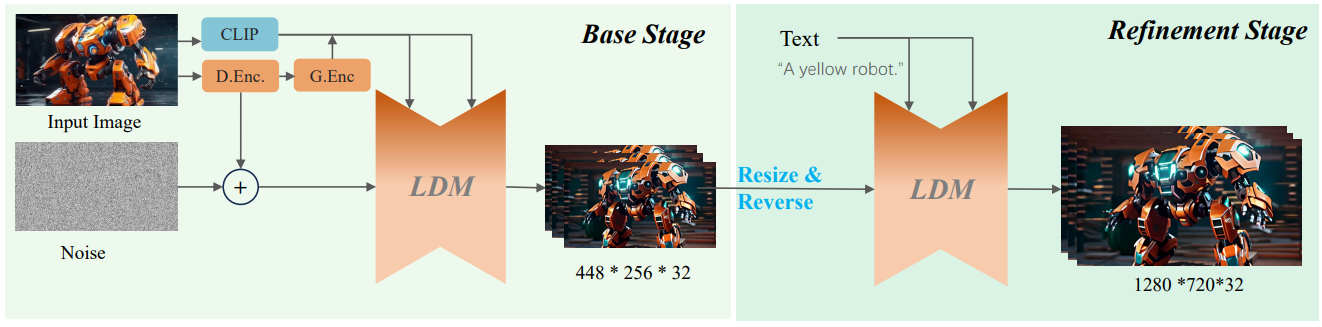
Base stage
Stage 1은 저해상도(448x256)에서 입력 이미지의 content와 세부 정보를 포함한 특징을 추출하는 데 중점을 둔다.
- High-level semantics learning : CLIP은 세부사항 포착이 부족하기 때문에 추가적인 Global Encoder G.Enc를 채택하고 cross-attention을 통해 3D U-Net에 주입.
- Low-level details : VQGAN(D.Enc)에서 추출한 feature를 첫 번째 프레임의 노이즈에 직접 추가. (+인듯?)
Semantic encoder 대신 VQGAN과 같은 local encoder를 사용하면 content는 더 잘 보존되지만 비디오가 재생됨에 따라 눈에 띄는 왜곡이 나타난다고 한다.
Refinement stage
Stage 2의 목적은 해상도를 향상(→ 1280x720)하고 시간적 연속성과 품질 향상, 왜곡을 제거하는 것이다.
Stage 1의 출력을 resizing&noising 하고 CLIP text embedding과 함께 고해상도 모델의 입력으로 사용한다.
Training and Inference
Training
기본 모델의 경우 SD-2.1로 공간 계층을 초기화한 후 공간 계층에 낮은 학습률을 적용하여 전체를 훈련한다.
고해상도 모델의 경우 훈련된 기본 모델을 통해 초기화하고 같은 방법 사용.
세부 사항 생성을 위해 Tr noise scale에 대해서 훈련한다.
고해상도 모델은 고품질 비디오에 대해 훈련된 뒤 엄선한 부분집합 데이터셋에서 추가로 fine-tuning 함.
Inference
기본 모델에서 생성 후 Tr noise를 추가하고 고해상도 모델을 통해 최종 비디오 생성.
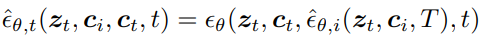
Experiments
I2VGen-XL
I2VGen-XL: High-Quality Image-to-Video Synthesis via Cascaded Diffusion Models Shiwei Zhang*, Jiayu Wang*, Yingya Zhang*, Kang Zhao, Hangjie Yuan, Zhiwu Qing, Xiang Wang, Deli Zhao, Jingren Zhou Alibaba Group Video synthesis has recently made remarkable st
i2vgen-xl.github.io



