DreamBooth + Subject Encoder + Self Subject Attention
[arXiv](Current version v1)

Abstract
Subject-driven image generation을 효과적으로 달성하기 위해 coarse∙fine 정보를 주입하는 DreamTuner 제안
Method
- Subject-Encoder
- Self-Subject-Attention
- Subject-Driven Fine-Tuning

Subject-Encoder
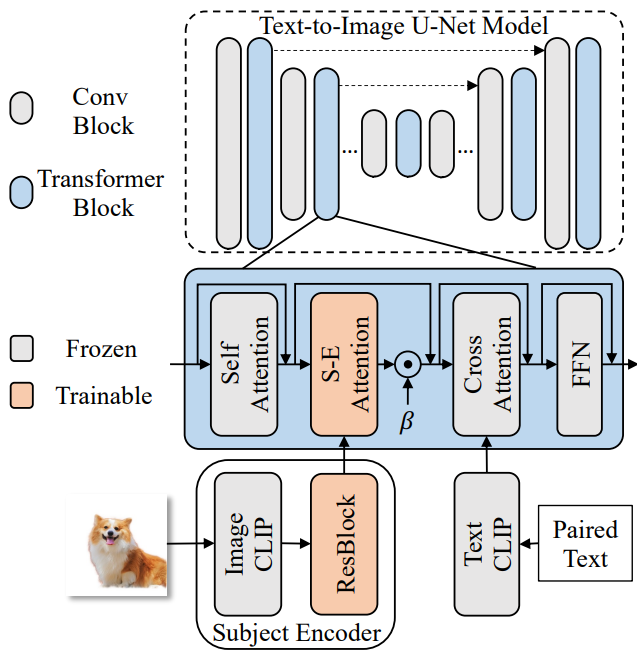
분할 모델을 통해 참조 이미지에서 배경을 분리하고 CLIP image encoder에 projection을 위한 ResBlocks 추가.
U-Net의 transformer block에 Subject-Encoder Attention 추가. S-E Attention은 cross-attention과 동일하고 0으로 초기화된다.
또한 overview의 stage-1과 같이 동결된 ControlNet으로 layout을 제공하여 subject encoder가 layout 보다는 content에 더 집중할 수 있도록 훈련한다.
Self-Subject-Attention

Forward diffusion process를 통해 참조 이미지를 노이즈화하고 같은 U-Net 해상도로 추출하여 self-attention의 K, V에 더한다.
분할 모델은 참조 이미지의 배경을 제거하고 전경, 배경 마스크를 생성하는 데 사용된다.
SelfSubject-Attention의 공식화:

DreamTuner에는 둘 이상의 조건이 있으므로 classifier-free guidance를 interleaved version으로 수정한다.

(r = 참조 이미지, ∆t = 참조 이미지의 노이즈 조정을 위한 작은 timestep, uc = undesired condition)
Subject Driven Fine-tuning
DreamBooth와 유사한 fine-tuning을 진행한다. LoRA를 사용할 수도 있다.

먼저 정규 이미지를 생성하고 페어링 데이터 {Rerference image, "A class word [S*]"}, {Regular image, "A class word"}를 구축하여 fine-tuning에 사용한다.
이 단계에서는 DreamBooth와 같이 CLIP encoder를 포함한 모든 피라미터를 학습할 수 있으며 다음과 같은 개선사항이 있다.
- 참조 이미지의 배경은 흰색으로 대체.
- [S*]는 고정된 단어가 아니라 훈련 가능한 임베딩이다.
- The subject-encoder is trained with the text-to-image generation model for better subject identity preservation.
- 세부 사항을 학습하기 위해 subject-encoder, self-subject-attention, 참조 이미지의 세부 캡션을 사용하여 참조 이미지와 더 유사한 정규 이미지를 생성한다.
Experiments
Stable Diffusion.
Subject-encoder는 {25, 4, 8, 12, 16} layer의 feature를 선택하여 residual blocks에 입력하는 듯?
일부 데이터 증강을 활용하여 참조 이미지와 생성 이미지 간의 차이를 강화.
pr = 0.9, wref = 3.0(자연 이미지) or 2.5(애니메이션 이미지), fine-tuning step = 800~1200.
캡션 모델 BLIP-2, deepdanbooru







