[Github]
[arXiv](Current version v2)

Abstract
인접한 denoising stage에서 feature를 캐시하여 속도를 향상하는 DeepCache 제안
Methodology
Feature Redundancy in Sequential Denoising
Observation: Denoising process의 인접한 step은 high-level feature에서 상당한 시간적 유사성을 보여준다.

Deep Cache For Diffusion Models
Cacheable Features in denosing

이전 업샘플링 블록의 feature를 다음과 같이 캐시하고
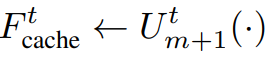
다음 t-1 단계에서는 skip branch에 필요한 것들만 계산하고 main brance의 계산은 캐시 검색으로 대체한다.

Extending to 1:N Inference
또한 한 단계에만 국한되지 않고 연속적인 N-1 단계에서 재사용하여 전체 timestep을 다음과 같이 줄일 수 있다.

Non-uniform 1:N Inference
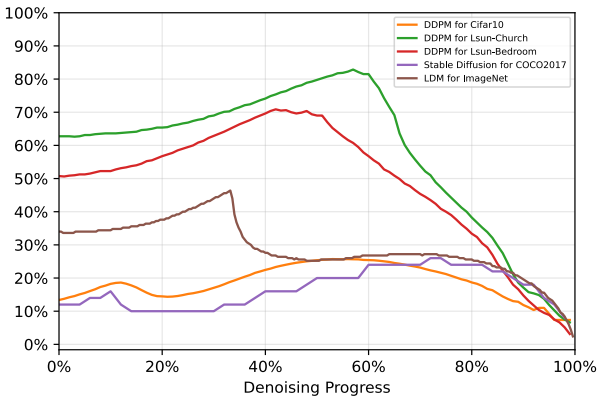
하지만 다음 그림과 같이 모든 단계에서 feature의 유사성이 높은 것은 아니며, 그렇지 않은 단계에서는 더 자주 샘플을 추출해야 한다.
전체 timestep을 다음과 같이 정의한다.
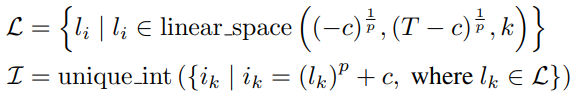
수식이 이해가 안돼서 GPT한테 T=1000 일 때 적절한 하이퍼피라미터를 설정하고 예시를 출력해 달라고 했더니

근데 식이 약간 이상함 ㅇㅇ; 그냥 중간값에서 멀어질수록 더 많은 샘플링을 하는 갑다~ 하면 됩니다.
사실 식 자체는 중요한 게 아니고, 얼마든지 다른 timestep을 정의할 수 있다.
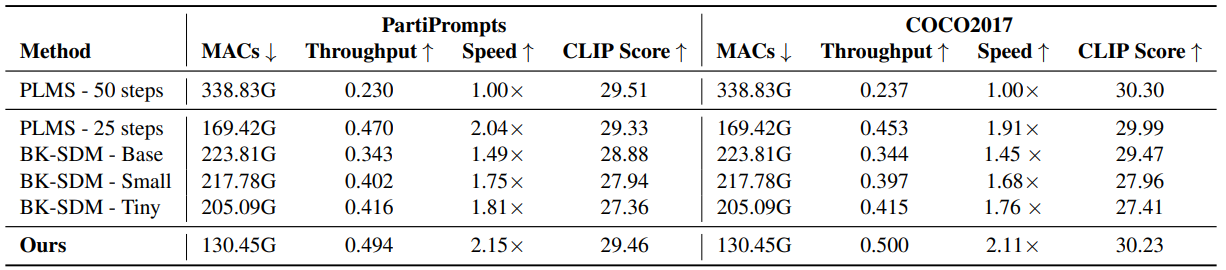
Experiment

'논문 리뷰 > Diffusion Model' 카테고리의 다른 글
| MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model (0) | 2023.12.13 |
|---|---|
| SyncDiffusion: Coherent Montage via Synchronized Joint Diffusions (1) | 2023.12.13 |
| Style Aligned Image Generation via Shared Attention (1) | 2023.12.13 |
| X-Adapter: Adding Universal Compatibility of Plugins for Upgraded Diffusion Model (1) | 2023.12.12 |
| Generative Powers of Ten (3) | 2023.12.12 |
| Diffusion Model Alignment Using Direct Preference Optimization (Diffusion-DPO) (2) | 2023.12.11 |



