[Github]
[arXiv](Current version v1)

Abstract
모션 시퀀스에 따른 비디오를 생성할 수 있는 MagicAnimate 제안
Method
참조 이미지 Iref, K 프레임의 모션 시퀀스 p1:K이 주어질 때 비디오 I1:K을 생성하는 것이 목표이다.

Temporal Consistency Modeling
Temporal attention layer가 추가된 U-Net FT.
Appearance Encoder
Iref의 feature를 추출하는 encoder.

추출된 feature는 zt에 concat 하여 spatial self-attention에 사용됨.
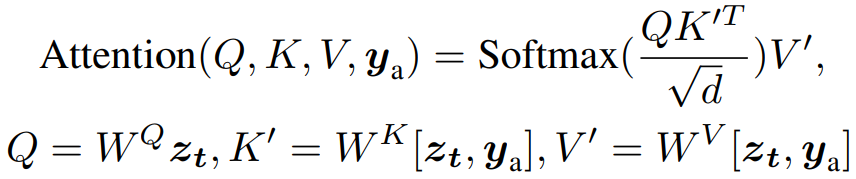
Animation Pipeline
Motion transfer
OpenPose 대신 특정 모션에 더 강건한 DensePose ControlNet 사용.

 |
 |
Denoising process

Long video animation
프레임 장거리 일관성을 개선하기 위해 시퀀스를 일부가 겹치는 K 길이의 여러 segment로 나눈다.
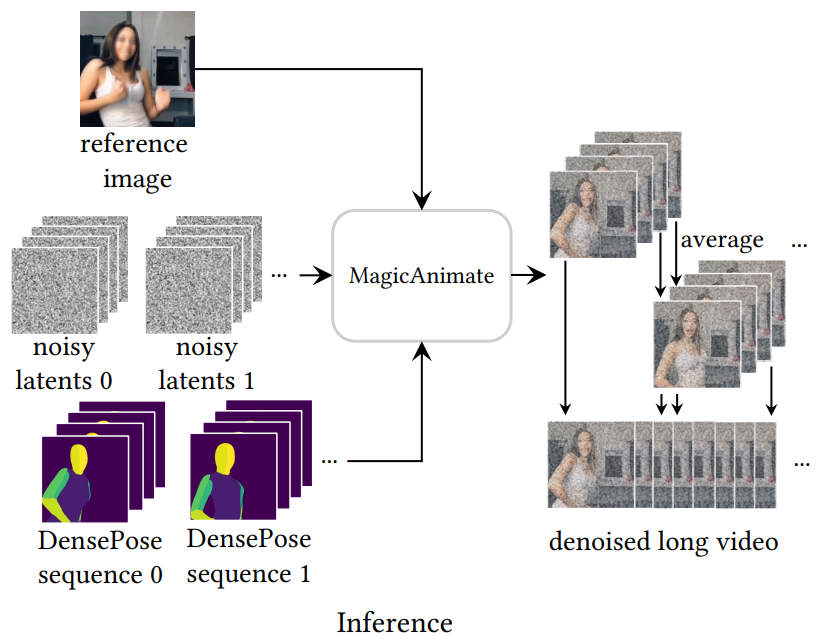
Timestep t에 대해 각 segment에서 노이즈를 예측하고 겹치는 프레임은 평균화하여 병합한다.
모든 segment에 동일한 초기 노이즈 z1:K를 공유하면 비디오 품질이 향상되었다.
Training
Learning objectives
1-stage에서는 temporal attention layer 없이 appearance encoder와 ControlNet만 훈련.

2-stage에서는 temporal attention layer만 훈련.

Image-video joint training
Video dataset은 image dataset에 비해 규모가 작고 포즈가 다양하지 않으므로 video-image 공동 훈련 전략 사용.
1-stage에서 일정 확률로 비디오 프레임 대신 이미지와 해당 이미지에서 추정된 포즈를 입력으로 사용하고 모델은 해당 이미지를 재구성하도록 훈련된다.
2-stage에서 temporal attention에 의해 공간적 품질이 저하된다.
임계값 τ1, τ2를 지정하고 r의 값에 따라 각각 다른 조건에서 훈련됨.
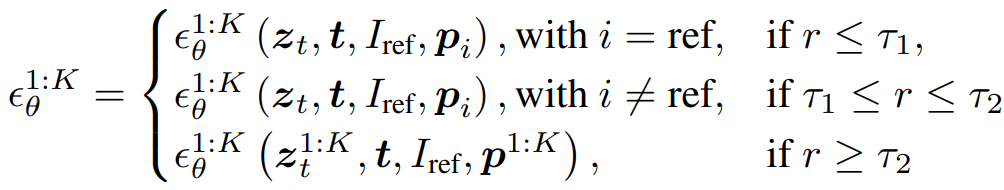
Experiment
https://showlab.github.io/magicanimate/
MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model
TL;DR: We propose MagicAnimate, a diffusion-based human image animation framework that aims at enhancing temporal consistency, preserving reference image faithfully, and improving animation fidelity.
showlab.github.io
'논문 리뷰 > Diffusion Model' 카테고리의 다른 글
| VideoLCM: Video Latent Consistency Model (1) | 2023.12.18 |
|---|---|
| AnimateZero: Video Diffusion Models are Zero-Shot Image Animators (0) | 2023.12.17 |
| PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding (1) | 2023.12.17 |
| SyncDiffusion: Coherent Montage via Synchronized Joint Diffusions (1) | 2023.12.13 |
| Style Aligned Image Generation via Shared Attention (1) | 2023.12.13 |
| DeepCache: Accelerating Diffusion Models for Free (0) | 2023.12.13 |



