합성되는 이미지의 identity를 지정하고 제어할 수 있는 T2I 모델
이론보다는 실용에 가까운 논문인 듯?
[Github]
[arXiv](Current version v1)

Abstract
Identity(ID) 충실도와 text 제어 가능성을 충족하는 T2I 생성 방법인 PhotoMaker 제안
Method
Overview

Stacked ID Embedding
Encoders
신체부위를 제외한 영역을 노이즈로 채워 배경의 영향을 제거한 뒤 CLIP-ViT 이미지 인코더를 사용하여 사용자가 제공한 N개의 이미지에 대해 이미지 임베딩 {ei}를 추출한다.
CLIP 인코더는 대부분 자연 이미지로 훈련되었기 때문에 ID 임베딩을 더 잘 추출할 수 있도록 일부 계층을 fine-tuning 하고, 텍스트 임베딩과 동일한 차원으로 주입하기 위해 추가 projection 계층을 도입한다.
Stacking
입력 캡션의 해당 class word(e.g. man, woman)를 식별하고 텍스트 임베딩에서 해당 위치의 feature vector를 추출한다.
이 feature vector는 MLP를 통해 이미지 임베딩과 융합된다. '대체'하지 않고 '융합'하는 이유는 class word를 통한 제어 가능성 때문이다. (e.g. man → woman)
다른 모델 개인화 방법들처럼 여러 장의 사용자 제공 이미지를 하나의 임베딩으로 통합하는 것이 아니라 임베딩 스택을 유지하여 모델로 보낸다.
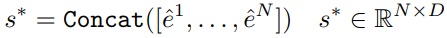
이로 인해 추론 시 다른 사람이나 캐릭터의 ID를 섞어 혼합하는 것 또한 가능하다.
Merging
융합 임베딩은 cross-attention을 통해 U-Net에 주입된다.
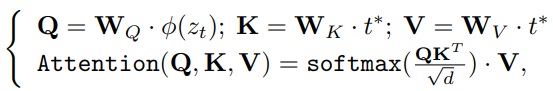
Prompt weighting을 통해 각 ID의 기여도를 조절할 수 있으며 LoRA를 사용하여 사전 훈련된 U-Net의 attention layer를 훈련한다.
ID-Oriented Human Data Construction
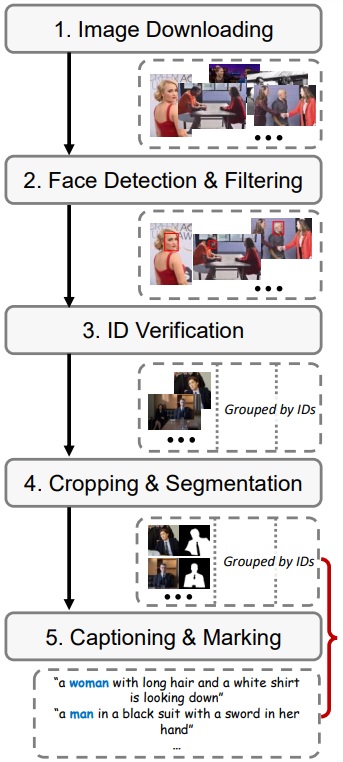
Image downloading
검색 엔진을 통해 각 인물 별로 100개의 이미지 다운로드.
Face detection and filtering
RetinaNet을 통해 얼굴 경계 상자를 식별하고 너무 작거나 식별이 되지 않는 이미지를 필터링.
ID verification
이미지에 여러 사람의 얼굴이 있을 수 있으므로 ArcFace를 통해 유사한 ID 임베딩의 얼굴이 포함된 이미지들을 선별.
Cropping and segmentation
Mask2Former를 사용하여 'person' class에 대한 분할을 수행하고 목표 ID에 해당하는 마스크를 선택.
Captioning and marking
BLIP2를 사용하여 class word(정해진 게 아님)가 나타날 때까지 무작위 캡션을 생성한다. 이후 class word의 위치를 표시해야 하는데 캡션에서 가장 많이 등장한 단어를 class word로 정하고 해당 단어가 등장하지 않은 캡션은 구문 분석 모델을 통해 캡션을 분할한 후 서브 캡션과 이미지의 ID 영역 사이의 CLIP score를 계산하여 가장 높은 단어를 class word로 표시한다.
Experiments
PhotoMaker
PhotoMaker: Customizing Realistic Human Photos via Stacked ID Embedding Zhen Li1,2* Mingdeng Cao2,3* Xintao Wang2✉ Zhongang Qi2 Ming-Ming Cheng1✉ Ying Shan2 1Nankai University 2ARC Lab, Tencent PCG 3University of Tokyo * Interns in AR
photo-maker.github.io
'논문 리뷰 > Diffusion Model' 카테고리의 다른 글
| FreeInit: Bridging Initialization Gap in Video Diffusion Models (1) | 2023.12.18 |
|---|---|
| VideoLCM: Video Latent Consistency Model (0) | 2023.12.18 |
| AnimateZero: Video Diffusion Models are Zero-Shot Image Animators (0) | 2023.12.17 |
| MagicAnimate: Temporally Consistent Human Image Animation using Diffusion Model (0) | 2023.12.13 |
| SyncDiffusion: Coherent Montage via Synchronized Joint Diffusions (0) | 2023.12.13 |
| Style Aligned Image Generation via Shared Attention (1) | 2023.12.13 |



