[arXiv](Current version v1)

Abstract
효과적으로 multi-scale content를 생성할 수 있는 joint multi-scale diffusion sampling 제안
영화 Powers of Ten (1977). 은하계에서 세포까지의 연속적인 줌을 보여줌.
Method
Zoom level i에서 각 prompt yi를 통해 일관된 xi 이미지 시퀀스를 생성하는 것이 목표이다.
Zoom Stack Representation
각 zoom level i에 따른 L과 x:
Image rendering
Rendering operator Π는 정해진 zoom level의 이미지를 반환한다.
Di(x)는 x를 확대/축소 정도 pi에 따라 x를 축소한다.
Mi는 center가 1이고 나머지가 0인 마스크. Center의 크기는 H/pi * W/pi.
연산 Di는 pi stride의 pi * pi gaussian kernel로 다운샘플링한다.
Π의 알고리즘을 보면 큰 이미지부터 center가 대체되는 방식으로 진행됨.
Noise rendering
서로 다른 zoom level에서 겹치는 영역은 동일한 노이즈 구조를 공유한다.
따라서 독립적인 노이즈 세트 ξ = (E0,..., EN-1)를 단일 zoom consist noise εi = Πnoise(ξ;i)로 변환하는 렌더링 연산자 도입.
렌더링 방식은 이미지 렌더링과 똑같지만 다운샘플링 연산자 D에 prefiltering이 포함되기 때문에 분산을 유지하기 위하여 노이즈를 상향 조정함.
Multi-resolution blending
예를 들어, L2를 업데이트하기 위해 x0,1,2에서 L2와 같은 부분을 잘라내고 Laplacian pyramid로 각 주파수 대역의 평균을 생성한다. 이렇게 수집된 이미지는 image blending을 위해 사용된다.
Multi-scale consistent sampling

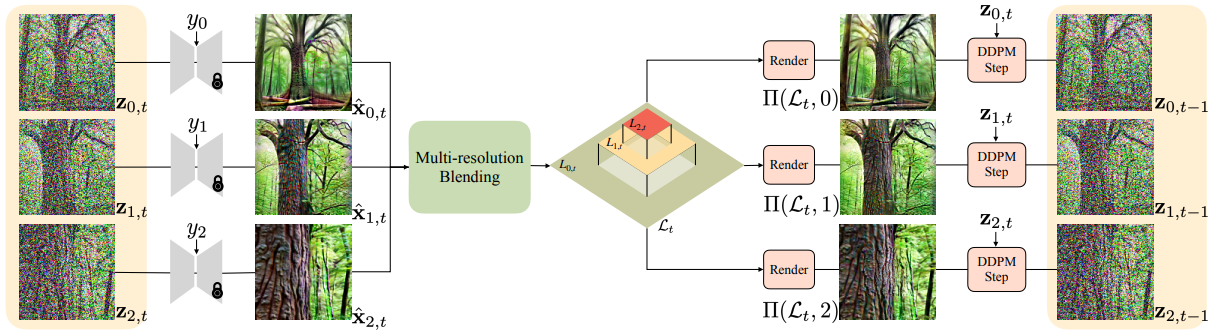
살짝 헷갈릴 수 있는데, 확산 모델이 사용되는 곳은 zt에서 zt-1을 계산할 때, 그리고 x̂t를 계산할 때 총 2곳이다.
알고리즘에서 보면 line7과 8~9. Line 8~9는 Classifer-free Guidance의 공식으로, 확산 모델이 사용된다.
Π로 렌더링된 x는 zt-1을 계산하는 데 조건으로 사용되는 듯하다.
Photograph-based Zoom
일관성을 장려하기 위해 모든 blending 작업 전 각 zoom level의 이미지들이 가장 큰 레이어 이미지 ξ의 center와 같아지도록 하는 5번의 간단한 최적화 단계를 거친다.
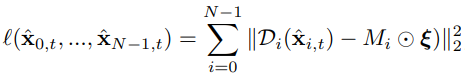
Implementation Details
계단식 확산 모델인 Imagen을 내부 데이터 소스로 훈련하여 사용하였다.
Experiments






