계산 집약적인 U-Net의 Up, Down Block 1을 수정하여 효율적인 초고해상도 생성
[arXiv](Current version v1)

Abstract
객체 중복이 발생하지 않고 4096x4096 이미지를 생성할 수 있는 HiDiffusion
Introduction
Stable Diffusion은 초고해상도 이미지를 생성하는 데 시간이 매우 오래 걸리며 객체 중복이 발생한다.
고해상도 이미지의 feature map 크기와 컨볼루션 수용 필드 간의 불일치를 해결하기 위해 Resolution-Aware U-Net (RAU-Net) 제안.
시간이 많이 소요되는 global self-attention 대신 Modified Shifted Window Multi-head SelfAttention (MSW-MSA) 제안.
HiDiffusion framework는 SDXL의 출력을 최대 4096x4096까지 확장하며 추론 시간을 약 50% 단축.
Preliminaries
Stable Diffusion U-Net의 Down blocks, Up blocks:
(Prompt p, timestep t, down factor α, up factor β)
Convolution kernel Ck,p,s,d (kernel, padding, stride, dilation)
HiDiffusion
Resolution-Aware U-Net
각 끝 계층을 Resolution-Aware Downsapler, Resolution-Aware Upsampler로 교체.
RAD, RAU는 입출력 치수를 맞추기 위한 계층으로 e.g. 1024x1024 생성의 경우 α, β = 4이고 p, d = 2로 dilation을 포함한다.
RAU-Net을 적용하면 객체 중복을 해결할 수 있지만 세부 사항은 vanilla U-Net이 더 잘 생성한다.
따라서 임계 timestep T1을 설정하여 t > T1일 때는 RAU-Net을, T1 > t일 때는 U-Net을 사용한다. (T1 = 20~40)
Modified Shifted Window Attention
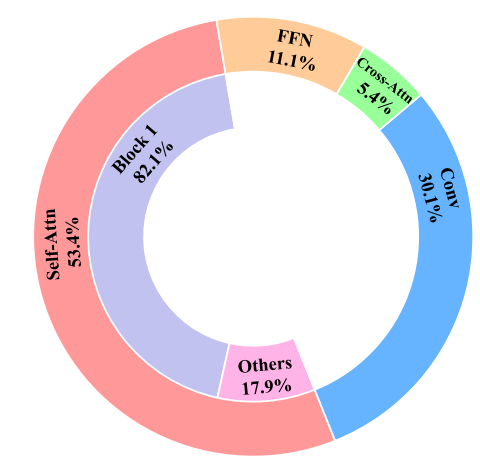
고해상도 블록의 self-attention에서 압도적으로 많은 시간이 소요된다.
또한 고해상도 블록은 self-attention에서 뚜렷한 locality를 보여줌.
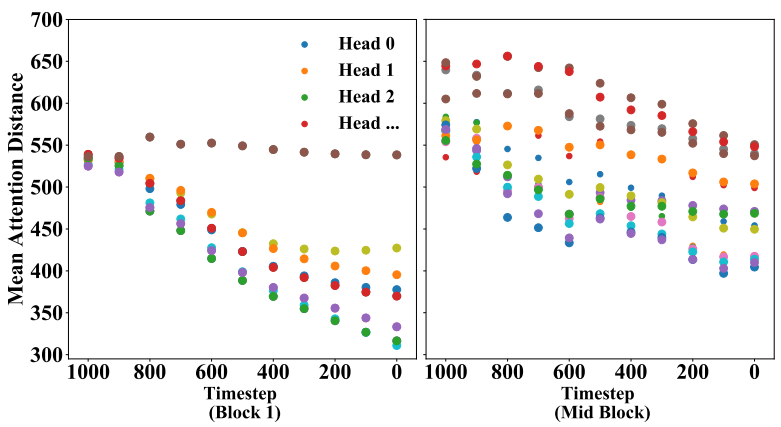
이러한 관찰에 따라 Block 1(up, down)에 window attention을 도입한다.
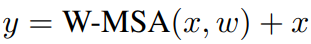
하지만 Stable Diffusion의 transformer block은 하나의 self-attention module만 가지고 있어 Swin transformer의 window shifting과 호환되지 않는다. 따라서 timestep에 따라 무작위로 window stride를 선택하는 방법을 사용한다.

Experiments

'논문 리뷰 > Diffusion Model' 카테고리의 다른 글
| X-Adapter: Adding Universal Compatibility of Plugins for Upgraded Diffusion Model (1) | 2023.12.12 |
|---|---|
| Generative Powers of Ten (2) | 2023.12.12 |
| Diffusion Model Alignment Using Direct Preference Optimization (Diffusion-DPO) (1) | 2023.12.11 |
| Animate Anyone: Consistent and Controllable Image-to-Video Synthesis for Character Animation (2) | 2023.12.05 |
| Noise-Free Score Distillation (1) | 2023.12.04 |
| Adversarial Diffusion Distillation (0) | 2023.12.01 |



