AnimateDiff + ReferenceNet + Pose Guide
[arXiv](Current version v1)

Abstract
확산 모델을 활용해 정지 영상에서 애니메이션을 생성할 수 있는 Animate Anyone 제안
Introduction
사전 훈련된 stable diffusion의 가중치를 상속하고 일관성을 유지하기 위해 대칭 U-Net 구조로 설계된 temporal attention이 있는 ReferenceNet을 사용한다.
포즈 제어를 위한 경량 pose guider 고안.
Methods
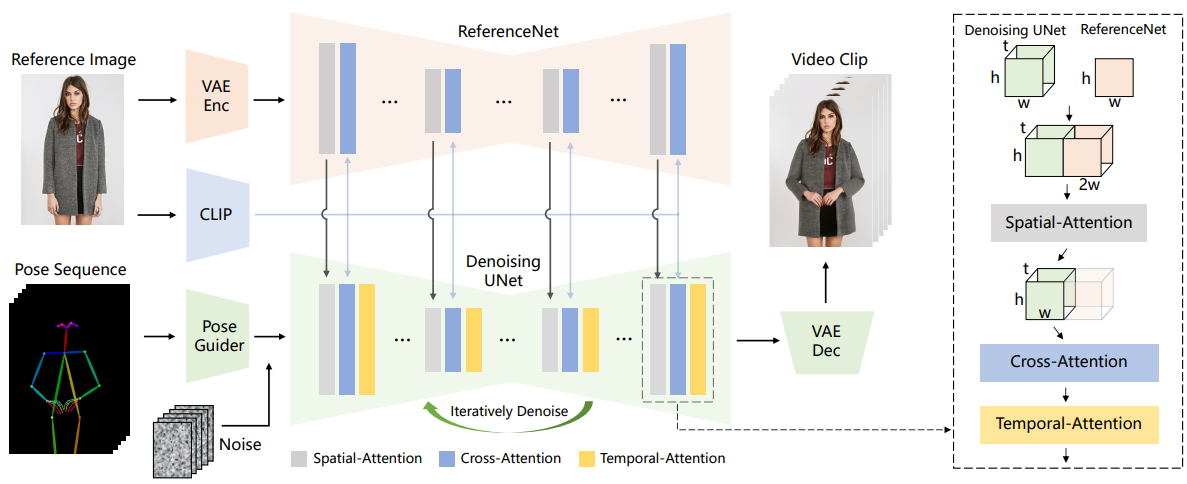
Network Architecture
Overview
Stable Diffusion + ReferenceNet + Pose Guider + Temporal Attention
ReferenceNet
대부분의 프레임워크에서 이미지 인코더로 사용하는 CLIP은 세부사항을 포착할 수 없기 때문에 ReferenceNet 고안.
구체적으로 Denoising Net의 x1 ∈ Rt×h×w×c, ReferenceNet의 x2 ∈ Rh×w×c 가 주어지면 x2를 t배 복사하여 x1에 연결하고 self-attention을 수행한 뒤 전반부만 다음 단계로 출력한다. + CLIP cross attention
추론 중에 모든 비디오 프레임이 여러 번 노이즈 제거를 거치는 동안 ReferenceNet은 한 번만 feature를 추출하면 되므로 오버헤드가 크게 증가하지 않는다.
Pose Guider
계산 복잡성이 증가하는 것을 방지하기 위해 ControlNet은 사용하지 않고 잠재 노이즈와 같은 해상도의 출력을 가진 비슷한 구조의 경량 인코더를 사용한다.
Temporal Layer
시간 계층의 설계는 AnimateDiff를 따랐으며, 잔차 연결을 통해 원래 feature에 통합된다.
ReferenceNet은 참여하지 않는다.
Training Strategy
첫 번째로 단일 프레임을 입력으로 stable diffusion 가중치로 초기화된 시간 계층이 없는 DenoisingNet, ReferenceNet 그리고 pose guider를 훈련한다.
두 번째로 시간 계층을 도입하고 AnimateDiff 가중치로 초기화한 뒤 비디오를 입력으로 시간 계층만 훈련한다.
Experiments
Implementations
DWPose로 포즈 추정
DDIM 샘플러
긴 비디오를 생성하기 위해 EDGE 논문의 방법을 사용한다.
5초의 클립을 생성할 수 있는 EDGE. 다음 배치의 초반 2.5초와 이전 배치의 후반 2.5초가 같도록 제한하여 12.5초의 비디오 생성.

Video
https://www.youtube.com/watch?v=8PCn5hLKNu4
'논문 리뷰 > Diffusion Model' 카테고리의 다른 글
| Generative Powers of Ten (2) | 2023.12.12 |
|---|---|
| Diffusion Model Alignment Using Direct Preference Optimization (Diffusion-DPO) (1) | 2023.12.11 |
| HiDiffusion: Unlocking High-Resolution Creativity and Efficiency in Low-Resolution Trained Diffusion Models (3) | 2023.12.07 |
| Noise-Free Score Distillation (1) | 2023.12.04 |
| Adversarial Diffusion Distillation (0) | 2023.12.01 |
| Common Diffusion Noise Schedules and Sample Steps are Flawed (Zero Terminal SNR) (0) | 2023.11.30 |



