DM distillation + GAN loss
1초 만에 SDXL보다 더 좋은 성능 ㄷㄷ 미쳤다 미쳤어 ㄷㄷ
[Github](SDXL-Turbo)
[arXiv](Current version v1)

Abstract
1~4 steps 만으로 확산 모델을 효율적으로 샘플링하는 Adversarial Diffusion Distillation(ADD) 소개
Introduction
확산 모델(DM)의 우수한 샘플 품질과 GAN의 속도를 결합하기 위해 적대적 손실과 score distillation의 조합을 도입한다.
Classifier-free guidance를 사용하지 않아 메모리 요구사항이 줄어들고 SDXL-Base보다 성능이 뛰어나다.
Background
최근 모델 증류에 대한 연구가 늘어나고 있다(e.g. Latent Consistency Models, InstaFlow).하지만 그들의 공통적인 결함은 종종 흐릿함과 아티팩트가 발생한다는 것이다.
StyleGAN-T는 Text-to-Image 생성을 위한 단일 step 모델이지만 확산 기반 모델에 비해 품질이 떨어진다.
Method
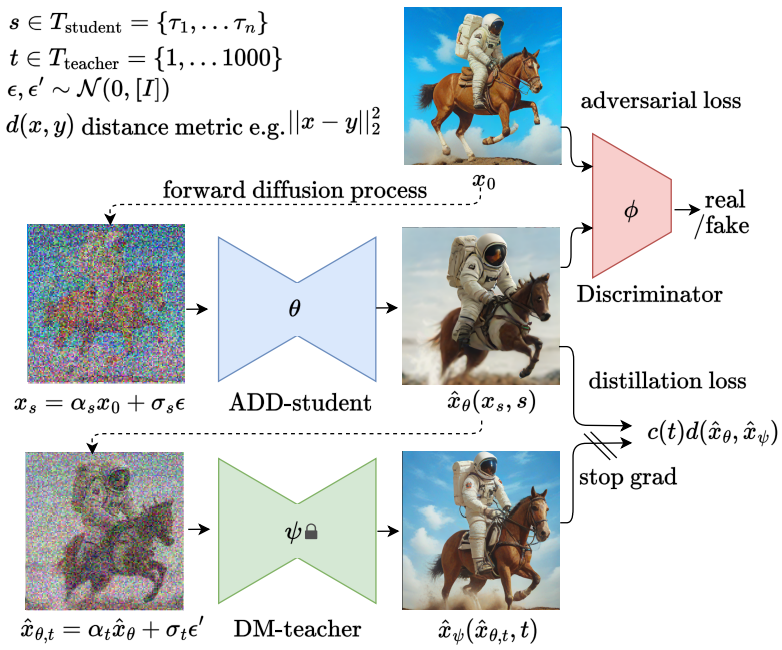
Training Procedure
실제 이미지를 확산시킨 후 사전 훈련된 DM으로 초기화된 학생 모델을 통해 샘플 생성.
xs는 N개의 timestep Tstudent에서 샘플링된 s에 대하여 생성된다.
Zero Terminal SNR에 따라 τn = 1000 이어야 한다. e.g. {100, 400, 700, 1000} of N = 4
전체 손실은 다음과 같다.
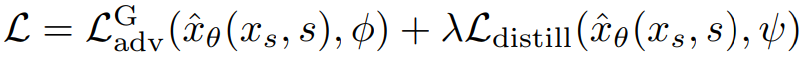
Latent diffusion model을 사용할 때도 더 안정적인 gradient를 생성하는 pixel space에서 증류 손실을 계산한다.
Adversarial Loss
판별기는 StyleGAN-T의 설계와 훈련 절차를 따름.

다른 점은 ctext 외에 추가로 x0을 cimg로 조건화한다는 것이다.
적대적 손실:
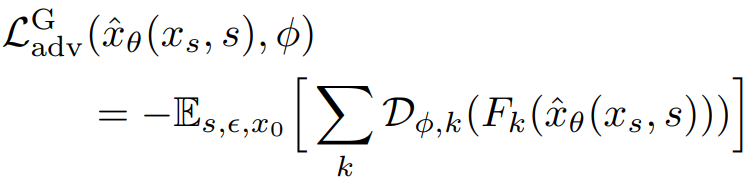
판별자는 별도로 훈련됨. (사전 훈련 모델 아님)
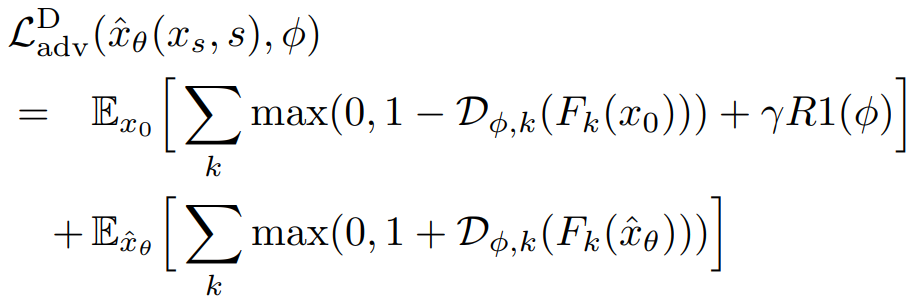
Score Distillation Loss
(sg = stop_gradient())

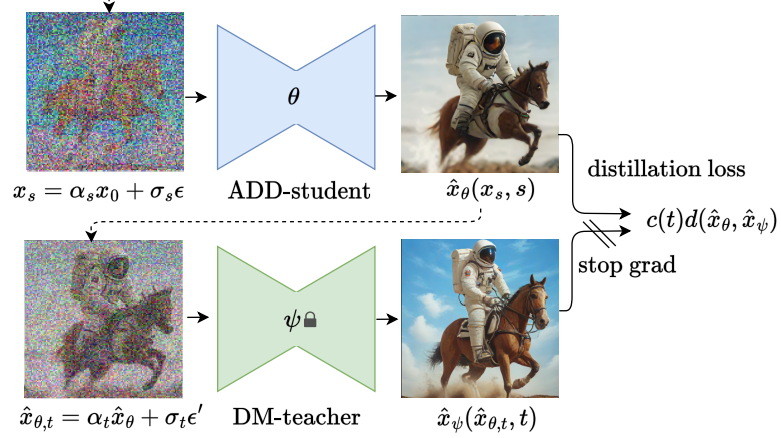
Metric d를 사용하여 교사와 학생의 출력을 비교.
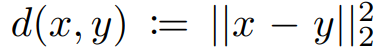
(t를 여러 개 샘플링하고 평균을 구하여 교사의 출력을 구성할 수도 있지만 비용에 비해 성능 향상이 없어서 사용하지 않은 것으로 보인다. Ablation 참고.)
가중치 c(t)에 대하여 세 가지 옵션을 고려:
- Exp : 높은 noise level이 더 적게 기여함.
- Score Distillation Sampling : c(t)를 다음과 같이 설정하면 SDS의 목적 함수와 같아짐. (부록 참고)

- SDS의 개선 버전인 Noise-Free Score Distillation (NFSD)
Experiments
ADD-M, ADD-XL 훈련.
Ablation Study
회색은 evaluation에서 default로 선택된 값이다.

Quantitative Comparison to State-of-the-Art
자동화된 metric의 사용은 자제했다.

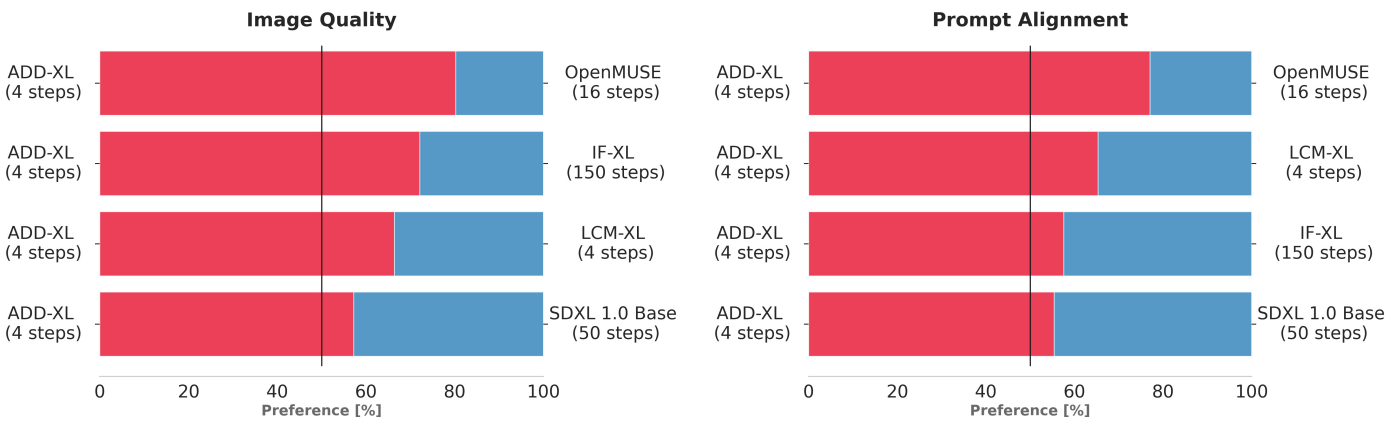


Qualitative Results






