Version이 다른 plug-in과 text-to-image model 호환되게 하기
[Github]
[arXiv](Current version v2)
Abstract
이전 text-to-image 확산 모델에서 사용된 다양한 plugin을 업그레이드된 모델에 활용할 수 있도록 하는 범용 어댑터인 X-Adapter 제안
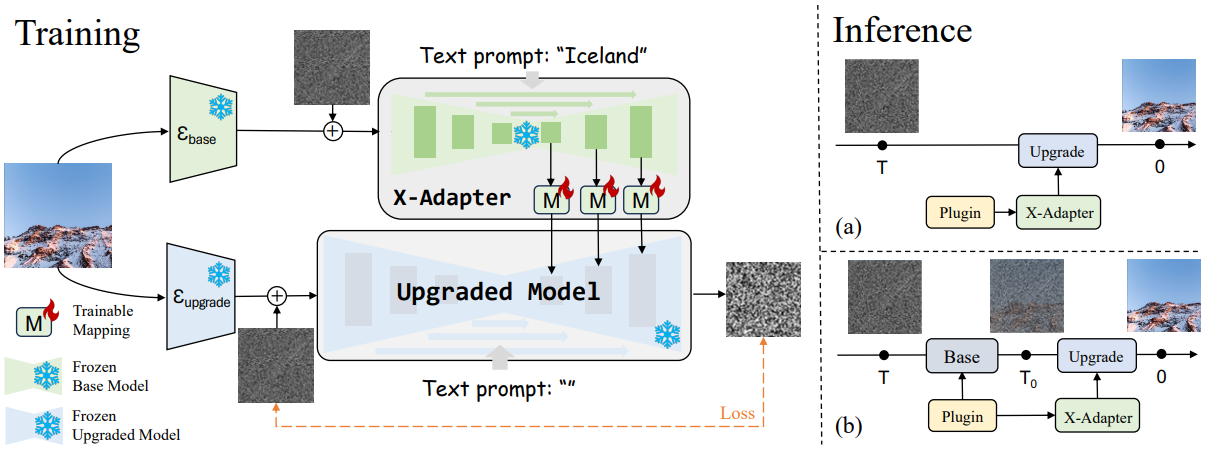
X-Adapter
Stable Diffusion 1.5v를 기반으로 구축. X-adapter는 기본 모델의 복사본을 그대로 가지고 있다.
Upgraded model은 SDXL가 기준이고 mapping layer는 마지막 3개의 decoding block에 배치한다.
기본 모델의 multi-scale feature map Fnbase, n번째 mapper Fn(), upgraded model의 feature map Fnup의 관계는 다음과 같다.
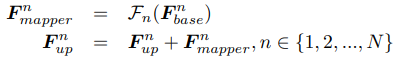
Training Strategy
훈련은 X-adapter의 plugin이 없는 상태에서 진행된다.
입력 이미지 I가 주어지면 timestep t 만큼의 노이즈를 인코딩 된 각각의 이미지 임베딩에 추가하고 X-adapter와 up model의 text prompt에 대해 up model에 입력된 임베딩에 추가된 노이즈를 예측하도록 훈련된다. 학습을 하는 것은 X-adapter의 mapping layer이다.

이때 up model의 text prompt는 비어 있는 상태에서 훈련되어 X-adapter가 condition offset을 학습할 수 있도록 한다.
추론 중에는 원하는 plugin을 사용하고, up model에 text prompt를 입력할 수도 있다.
Inference Strategy
위 그림의 (a)처럼 추론 중에 두 bypass의 latent가 따로 샘플링되면 정렬에 문제가 생길 수 있으므로 SDEdit에서 영감을 받은 2-stage 추론 전략을 사용한다.

먼저 무작위로 샘플링된 latent zT에 대해 plugin이 있는 base model에서 reverse process를 T0까지 진행한 뒤 zT0을 up model의 latenet로 입력하고 bypass를 수행한다. (D = base model의 latent decoder, E = up model의 latent encoder)
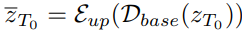
Ablative Study
Where to insert mapping layer?
디코더에만 사용하는 것이 가장 성능이 좋았다.

How do mapping layers guide the upgraded model?
그냥 더하는 게 성능이 제일 좋았다. Concat 아니고 그냥 더하는 거 인 듯?

Is using empty text important in the upgraded model?
Empty prompt가 X-adapter의 안내 효과를 극대화시켜 좋은 결과가 나오는 것 같다.

Is two-stage inference important?
ㅇㅇ

Experiments



'논문 리뷰 > Diffusion Model' 카테고리의 다른 글
| SyncDiffusion: Coherent Montage via Synchronized Joint Diffusions (1) | 2023.12.13 |
|---|---|
| Style Aligned Image Generation via Shared Attention (1) | 2023.12.13 |
| DeepCache: Accelerating Diffusion Models for Free (0) | 2023.12.13 |
| Generative Powers of Ten (3) | 2023.12.12 |
| Diffusion Model Alignment Using Direct Preference Optimization (Diffusion-DPO) (2) | 2023.12.11 |
| HiDiffusion: Unlocking High-Resolution Creativity and Efficiency in Low-Resolution Trained Diffusion Models (3) | 2023.12.07 |



