오디오 코덱 신경망

Abstract
신경망을 통한 오디오 코덱인 SoundStream 제안.
벡터 양자화와 적대적 훈련을 통하여 고품질 오디오 콘텐츠 생성 가능.
Introduction
- 적대적 및 재구성 손실로 end-to-end 훈련되는 신경망 오디오 코덱인 SoundStream 제안
- Residual vector quantizer, quantizer dropout 기술 제안
Model

Encoder architecture

나도 음향? 데이터를 잘 몰라서 직접 데이터 크기를 비교해 봤는데,
일단 인코더 입력 시 크기는 (1, 64000). (배치 크기 제외)

인코더의 각 블록을 통과한 후의 크기
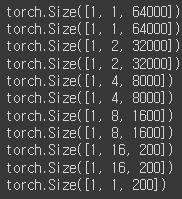
1D 컨볼루션으로 연산된다.
디코더의 출력은 당연히 그 반대

또한 입력 데이터에 추가로 음향 노이즈 제거를 수행할지 말지에 대한 신호를 보내고, FiLM conditioning 모듈에서 이를 반영하여 음향 노이즈를 선택적으로 제거한다.
이 논문은 읽는 계기가 벡터 양자화 부분 때문이라서, 인코더와 디코더의 자세한 사항에 대해서는 건너뜀.
Residual Vector Quantizer
Limitations of Vector Quantization
음향 이론(bit rate와 sampling rate, 레전드임... 말이 필요없다...)
Bitrate 6000bps, sampling rate 24000hz인 신호의 경우,
인코더에서 320배 압축했으므로(total stride = 2x4x5x8 = 320),
75hz의 신호가 되고(24000/320),
각 프레임 당 사용할 수 있는 비트는 80비트(6000/75),
이걸 하나의 코드북으로 표현하려면 280개의 코드북 벡터가 필요하지만 현실적으로 불가능한 수치다.
Residual Vector Quantizer
그래서 고안한 것이 잔차 벡터 양자화이다.
방법은 단순한데, 양자화 후의 잔차를 계속해서 다시 양자화함으로써 표현의 가짓수를 늘린다는 것이다.


본 논문에서는 1024개의 벡터가 있는 8개의 코드북을 사용하는데, 그렇게 하면 약 8000개의 벡터만으로 280가지의 표현이 가능하다.
코드북을 첫 배치의 k-평균으로 초기화하고 감쇠가 0.99인 EMA 업데이트, 사용되지 않는 코드북 벡터는 현재 배치의 후보로 교체.
Enabling bitrate scalability with quantizer dropout
Quantizer dropout을 통해 모든 bitrate에 적응할 수 있다.
높은 bitrate에는 많은 양자화 계층, 낮은 bitrate에는 적은 양자화 계층을 사용하면 된다.
Bitrate에 따라 각기 다른 모델을 훈련하거나 추가적인 조치가 필요하던 기존의 방법들과는 차별화된 방법이다.
훈련에는 각 코드북을 랜덤하게 선택하고,
낮은 bitrate의 오디오를 생성할 때는 적은 양자화 계층을, 높은 bitrate에는 많은 양자화 계층을 사용하기만 하면 된다.
Discriminator architecture
판별기는 두 종류의 판별기가 있는데,
하나는 MelGAN에서 제안한 multi-scale 판별기

다른 하나는 STFT(Short Time Fourier Transform) 판별기로, 1D 데이터를 STFT를 통해 2D로 변환하고 2D feature에서 판별을 진행한다.

이하생략...
다른 부분엔 별로 관심 없고, 피곤하기도 하고...
주의) 오디오 데이터는 익숙하지 않아서, bitrate, sampling rate와 같은 용어의 사용이 정확하지 않을 수 있음.



