아이들의 그림을 움직이게 하기

Abstract
아이들의 그림을 애니메이션화 하는 누구나 사용할 수 있을 만큼 간단하고 직관적인 시스템 제안.
또한 Amateur Drawings Dataset 소개.
Introduction
이 시스템은
- Figure detection
- Segmentation masking
- Pose estimation/rigging
- Animation
4단계로 구성된다.
기존 사진 모델과 펜 드로잉의 차이로 인해 모델을 fine tuning 해야 하고 훈련 세트 크기와 성공률 사이의 관계를 탐구하기 위한 일련의 실험과 지각 연구 수행.
+Amateur Drawings Dataset
Method
- 경계 상자 예측
- Segmentation mask를 통해 픽셀 분리
- 포즈 추정, 관절 식별
- 캐릭터 리깅 및 애니메이션화
Figure Detection
탐지를 위해 ResNet-50+FPN 백본의 Mask R-CNN 모델을 사용.
백본의 가중치는 고정하고 헤드를 human figure 단일 클래스만 예측하도록 fine tuning함.
Figure Segmentation
사진과 드로잉의 feature 차이 때문에 단순 fine tuning 만으로 부적합하다.
따라서 고전적인 이미지 처리 방법 사용.
(회색조 변환, 적응 임계값 적용, 노이즈 제거, 픽셀 연결, 침식 연산, 구멍 채우기, 가장 큰 영역만 선택)
이미지 처리 전후 비교
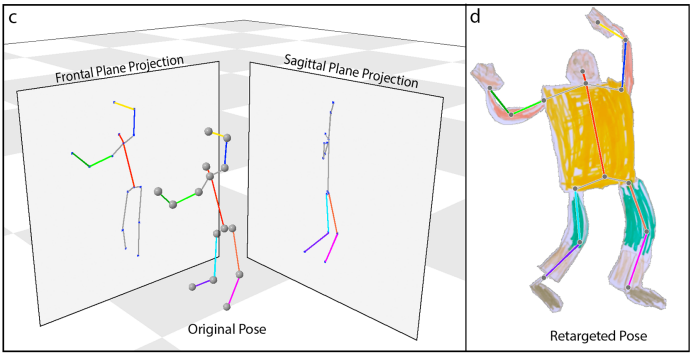
Pose Estimation
포즈를 추정하기 위해 ImageNet에서 사전 훈련된 ResNet-50 백본에 각 관절 위치에 대한 개별 히트맵을 예측하는 하향식 히트맵 키포인트 헤드가 있는 커스텀 모델을 MS-COCO의 키포인트에 대하여 훈련한다.

Animation
Segmentation mask에서 들로네 삼각분할로 2D mesh를 생성.
각 키포인트에서 캐릭터 골격을 구성하고

2D mesh의 각 삼각형마다 가장 가까운 신체 부위를 찾아 팔다리나 신체가 앞 또는 뒤에 있는 것처럼 렌더링 할 수 있다.
As-Rigid-As Possible 모양 조작을 사용하여 애니메이션화.
자세한 내용은 딥러닝과도 별로 관련 없고 너무 지엽적이고 복잡해서 궁금하면 그냥 논문을 보시길...
Evaluation and Analysis
Effect of Training Sample Size
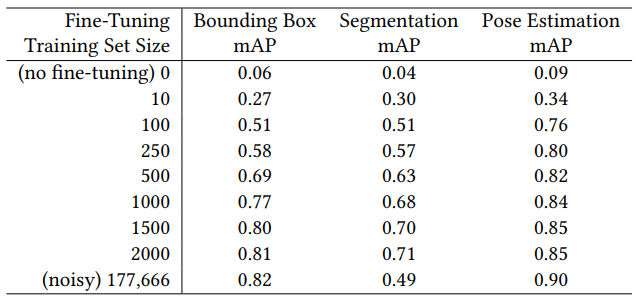
사진에서 훈련된 모델과 아이들의 그림은 feature가 매우 다르기 때문에 fine tuning을 해야 하는데, 이러한 과정에서 얼마나 많은 데이터가 필요한지에 대한 일련의 실험을 제시.
17만 개 이상의 이미지가 있는 Amateur Drawings Dataset.
하지만 일부 사용자 주석은 노이즈가 많고 부정확하기 때문에 해당 데이터셋에서 부정확하지 않은 '깨끗한' 이미지 2500개를 수동으로 선택한 소규모 데이터셋을 만들고 해당 데이터셋에서 10~2500의 다양한 크기의 train set을 만듦.
Results

Discussion
표 1에서, 1500 → 2000은 성능 향상 거의 없음.
노이즈가 있는 대규모 데이터셋에서는 segmentation 성능이 많이 떨어짐.
표 2는 애니메이션에 성공적으로 사용될 수 있는 모델 예측의 백분율이다.
이미지 처리 과정이 없으면 segmentation의 성공률이 매우 낮다. 대부분이 배경과 그림 내부의 질감이 같은 '속이 빈' 그림이기 때문으로 추정된다.
Experiments


'논문 리뷰 > etc.' 카테고리의 다른 글
| High Fidelity Neural Audio Compression (EnCodec) (0) | 2023.06.13 |
|---|---|
| SoundStream: An End-to-End Neural Audio Codec (0) | 2023.06.13 |
| ImageBind: One Embedding Space To Bind Them All (0) | 2023.06.10 |
| Reviving Iterative Training with Mask Guidance for Interactive Segmentation (0) | 2023.04.09 |
| Iteratively Trained Interactive Segmentation (1) | 2023.04.09 |
| Hard Prompts Made Easy: Gradient-Based Discrete Optimization for Prompt Tuning and Discovery (0) | 2023.02.11 |



