오디오 코덱 신경망. SoundStream 개선 버전.

Abstract
신경망을 활용한 최첨단 실시간, 고충실도 오디오 코덱인 EnCodec 소개.
Introduction
압축 모델의 주요 문제는 두 가지이다.
첫째, 모델은 일반적이고 광범위한 신호를 나타낼 수 있어야 한다.
-크고 다양한 훈련 세트, 판별기 네트워크를 사용하여 해결
둘째, 컴퓨팅 시간과 크기를 효율적으로 줄여야 한다.
-CPU 코어에서 실행 가능하도록 모델 제한, 잔차 벡터 양자화(SoundStream) 채택.
Model
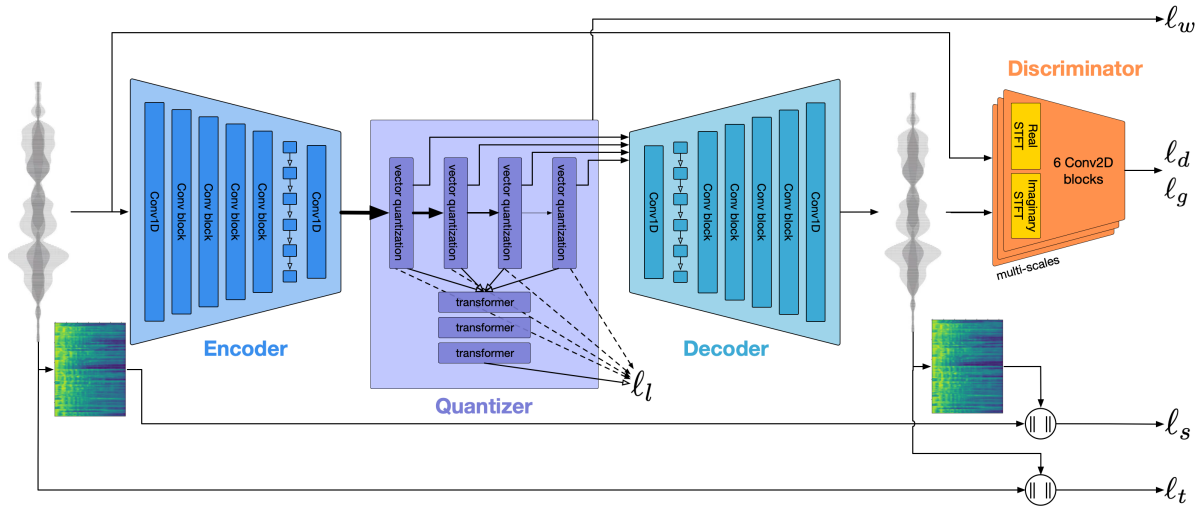
Encoder & Decoder Architecture
기본적으로 아키텍처는 시퀀스 모델링을 위해 최종 Conv1D 직전에 추가한 LSTM을 제외하면 SoundStream과 동일하고 고충실도의 non-streamable usage, 짧은 지연 시간의 streamable usage 두 가지 버전이 약간의 차이가 있음.
Residual Vector Quantization
SoundStream의 코드북과 Residual Vector Quantizer, Quantizer Dropout 기술 그대로 사용.
다른 점은 더 많은 코드북 사용함(최대 32개).
Language Modeling and Entropy Coding

단일 CPU 코어에서 빠른 속도를 유지하기 위해 Transformer 기반 언어 모델을 추가로 훈련.
해당 모델은 t-1 timestep의 이산 표현을 합산해 t step의 분포를 추정한다.
추정 분포를 이용하기 위해 10-6의 정밀도로 반올림한 다음 너비 2~224의 범위로 range based arithmetic coder 사용.
Training objective
Reconstruction Loss
대상과 재구성된 오디오 사이의 시간 영역에서의 L1 거리

STFT를 사용하는 64-bins mel-spectrogram에 대한 L1, L2 거리

Discriminative Loss

SoundStream에서는 multi-scale 판별기와 STFT 판별기를 따로 사용했지만 EnCodec에서는 둘을 합쳐 STFT 창 크기가 각각 다른 5개의 STFT 판별자를 사용한다.

또한 대상과 재구성된 오디오에 대한 판별기 내의 feature 차이인 feature matching loss 추가

판별자는 hinge adversarial loss를 최소화하도록 훈련됨.

Multi-bandwidth training
SoundStream의 Quantizer Dropout을 그대로 사용하고 각각의 대역폭에 대해 크기가 비슷한 대역폭별 전용 판별자를 지정해 놓는 것이 오디오 품질에 도움이 되었다고 한다.
VQ commitment los
각 단계의 잔차와 양자화된 값 사이의 손실


Balancer


뒷항을 보면 EMA로 나눴기 때문에 스케일링하기 전의 손실값이 항상 1에 가까울 것 같고, 거기에 전체 손실에 대한 각 손실의 비율을 곱해 줬으니 해당 비율이 (0.1 : 1 : 3 : 3) 으로 계~속 유지되게 하는 역할인 것으로 보인다.
Experiments


'논문 리뷰 > etc.' 카테고리의 다른 글
| Generative Image Inpainting with Contextual Attention (1) | 2023.10.10 |
|---|---|
| Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow (Rectified Flow) (0) | 2023.09.25 |
| Simple and Controllable Music Generation (MusicGen) (0) | 2023.06.15 |
| SoundStream: An End-to-End Neural Audio Codec (0) | 2023.06.13 |
| ImageBind: One Embedding Space To Bind Them All (0) | 2023.06.10 |
| A Method for Animating Children's Drawings of the Human Figure (1) | 2023.04.19 |



