주어진 코드북 패턴에 따라 단일 transformer로 음악 생성.
https://twitter.com/honualx/status/1668652005487779840(신기함)
트위터에서 즐기는 Alexandre Défossez
“Official MusicGen now also supports extended generation (different implem, same idea). Go to our colab to test it. And keep an eye on @camenduru for more cool stuff! Of course, I tested it with an Interstellar deep remix as lo-fi with organic samples :)
twitter.com
Abstract
복잡한 모델들의 연결이 아닌 단일 모델을 통해 음악을 생성하는 MusicGen 제안.
Introduction
- 효율적인 codebook interleaving 전략을 통해 single-stage language model로 일관된 음악을 생성하는 MusicGen
- 멜로디 컨디셔닝을 도입하여 멜로디 구조와 일치하는 음악을 생성할 수 있음
Method
Audio tokenization
EnCodec 사용.

EnCodec은 오디오 지속시간 d
Sampling rate fs
랜덤 변수 X ∈ Rd∙fs가 주어지면
프레임 속도가 fr < fs인 연속 텐서로 인코딩함.
그리고 해당 표현은 코드북을 통해 Q ∈ {1,...,N}K x d∙fr로 양자화됨.
(코드북 수 K, 코드북 크기 N)
잔차 양자화는 이전 양자화기의 오류를 다시 인코딩하므로 각 코드북 값은 독립적이지 않고 첫 번째 코드북이 가장 중요함.
Codebook interleaving patterns
Exact flattened autoregressive decomposition
자기 회귀 모델에는 이산 시퀀스 Q ∈ {1,...,N}S가 필요하며 특수 토큰인 U0을 시작으로 분포를 모델링한다.

재귀적으로 정의하면

이는 p의 완벽한 모델 p̂을 맞출 수 있다면 U를 정확히 모델링할 수 있다는 것을 의미함.
EnCodec의 문제는 각 timestep에 대해 K개의 코드북이 있다는 것.
한 가지 해결책은 자기 회귀적으로 다음 코드북을 예측하는 방식으로 Q를 평탄화한 S(=dfs∙K)를 취하는 것이다.

이는 복잡성이 증가하지만 이론적으로 Q의 정확한 분포에 도달할 수 있다.
e.g.) MusicLM
Inexact autoregressive decomposition
위의 방법은 한 단계에서 한 개의 코드북을 예측했다면, 또 다른 방법은 한 단계에서 다음 timestep의 모든 코드북을 병렬로 예측하는 것이다.
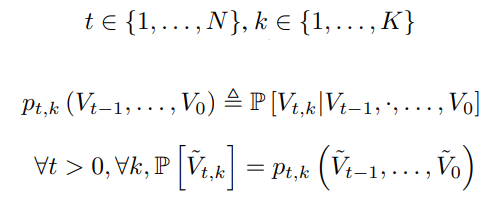

이 방법은 코드북이 서로 독립일 경우에만 정확한 분포를 추정할 수 있는 단점이 있지만, 추론 속도가 빠른 것이 장점이다.
e.g.) Vall-E

Arbitrary codebook interleaving patterns
다양한 분해를 실험하고 측정하기 위해 codebook interleaving pattern 도입.
모든 timestep과 codebook 쌍의 집합 Ω

에서 한 번에 병렬로 예측되는 부분집합을 P라고 하면 각 분해들을 쉽게 정의할 수 있다.

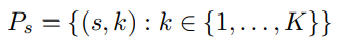

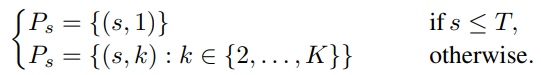
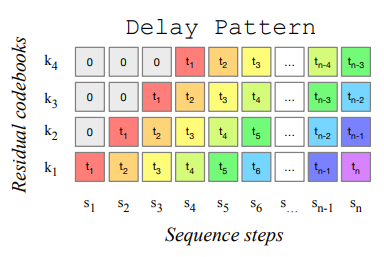

첫 번째 코드북이 가장 중요하다는 직관을 바탕으로, 나머지 코드북만 병렬로 예측하는 다음과 같은 패턴들도 있음.

이 챕터의 내용이 여기까진데, 다 읽고 그래서 어쩌란 거지...?라는 생각이 들었다.
Interleaving의 뜻은 다음과 같은데,

MusicGen은 자기 회귀적인 transformer 모델로, 패턴 Ps에 따라 Q의 각 부분집합을 예측해 끼워 넣는다.
MusicGen에서는 delay pattern 사용함.
Model conditioning
Text conditioning
T5 encoder, FLAN-T5, CLAP

Melody conditioning
Chromagram으로 추가 컨디셔닝.
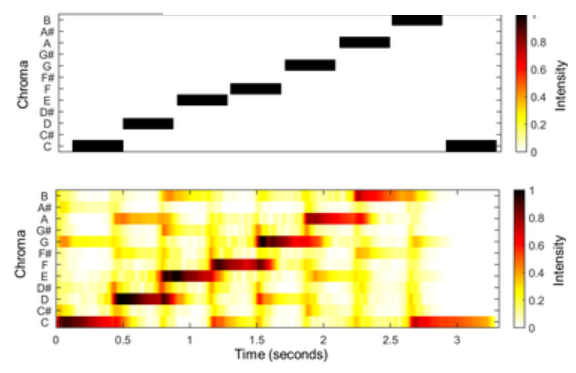
하지만 크로마그램은 종종 과적합을 초래해, 각 timestep에서 우세한 시간-주파수 bin을 선택하여 information bottleneck 도입.
i.e.) 크로마그램이 주로 드럼, 베이스와 같은 저주파 악기에 지배되는 경향을 발견하고 음악을 드럼, 베이스, 보컬, 기타로 분해한 뒤 드럼과 베이스(멜로디에 직접적으로 관여하지 않는)를 생략하여 멜로디 구조 복구, 크로마그램 생성.
Model architecture
EnCodec encoder를 tokenizer로 사용.
2048개의 벡터가 있는 4개의 코드북.
Codebook projection and positional embedding
코드북 패턴의 각 패턴 단계 Ps에는 일부 코드북만 존재하며, 최대 1번 존재하거나 존재하지 않는다.
따라서 Ps에 해당 코드북이 존재하는 경우 임베딩으로 관련 값을 나타내며, 존재하지 않는 경우 특수 토큰 사용.
Transformer decoder
Cross attention으로 컨디셔닝.
xFormers 패키지의 flash attention을 사용하여 속도와 메모리 개선.
Logits prediction
Ps에서의 디코더 출력을 logit 예측으로 변환.
구체적으로 Ps+1에 존재하는 코드북의 경우, 디코더 출력에 선형 계층을 적용하여 logits prediction을 얻는다.
Evaluation



'논문 리뷰 > etc.' 카테고리의 다른 글
| Deep Flow-Guided Video Inpainting (1) | 2023.10.10 |
|---|---|
| Generative Image Inpainting with Contextual Attention (1) | 2023.10.10 |
| Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow (Rectified Flow) (0) | 2023.09.25 |
| High Fidelity Neural Audio Compression (EnCodec) (0) | 2023.06.13 |
| SoundStream: An End-to-End Neural Audio Codec (0) | 2023.06.13 |
| ImageBind: One Embedding Space To Bind Them All (0) | 2023.06.10 |



