Hard prompt 최적화

Abstract
Hard prompt 최적화 및 자동 생성
Introduction
Hard prompt는 다른 모델에도 적용 가능하다는 이식성에서 장점이 있다.
Hard prompt의 최적화를 통해 hard prompt의 장점과 soft prompt의 장점인 용이성과 자동화를 결합한다.
- 텍스트 최적화를 위해 기존에 사용되던 gradient reprojection 체계를 기반으로 하여 hard prompt를 학습하기 위한 간단한 체계 제안
- 위 최적화 방법을 hard prompt 학습에 사용하여 prompt를 생성하는 일반적인 도구를 제공
- 학습된 prompt 체계가 해석 가능성을 향상하며 다른 텍스트 최적화 체계를 능가한다는 것을 보임
Prompt 최적화란 다음과 같은 작업을 의미함. (더 적은 임베딩 토큰으로 같은 의미론을 가진 텍스트 만들기)

Methodology
Learning Hard Prompts
사전 훈련되고 고정된 모델 θ,
일련의 학습 가능한 임베딩 P(=[ei, ..., eM]) (M은 최적화할 벡터의 토큰 수),
배치 차원에서 prompt 임베딩을 반복하는 broadcast 함수 B
토큰 공간의 이산성은 prompt에서 ei를 가져와 Eㅣvㅣ에서 가장 가까운 이웃에 투영하는 함수 ProjE를 사용하여 실현됨.
(Eㅣvㅣ = 모델의 어휘 크기, P' = ProjE(P))
Hard prompt를 학습하기 위해서 다음을 최소화:

(P를 X에 근사하도록 투영하여 더 적은 텍스트로 같은 의미론을 가진 Y로 만드는 게 목적)
Our Method
P를 P'에 투영하고 P'의 gradient를 이용하여 P를 반복적으로 업데이트하는 PEZ라고 부르는 체계 제안.

Prompt Inversion with CLIP
CLIP에는 자체 이미지 인코더가 있으므로 이를 손실 함수로 사용할 수 있다.
Gradient를 CLIP 이미지 인코더와의 코사인 유사성으로 대체한다.
텍스트 인코더 f, 이미지 인코더 g에 대해:
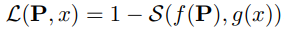
Experimental Setting
Dataset : LAION, MS COCO, Celeb-A, Lexica.art
Model : Stable Diffusion-v2(Guiding - s=9,t=25), OpenCLIP-ViT/H
원본 이미지와 학습된 hard prompt를 사용하여 생성된 이미지와의 유사성을 통해 품질 측정
CLIP Interrogator와의 CLIP score 비교
Results
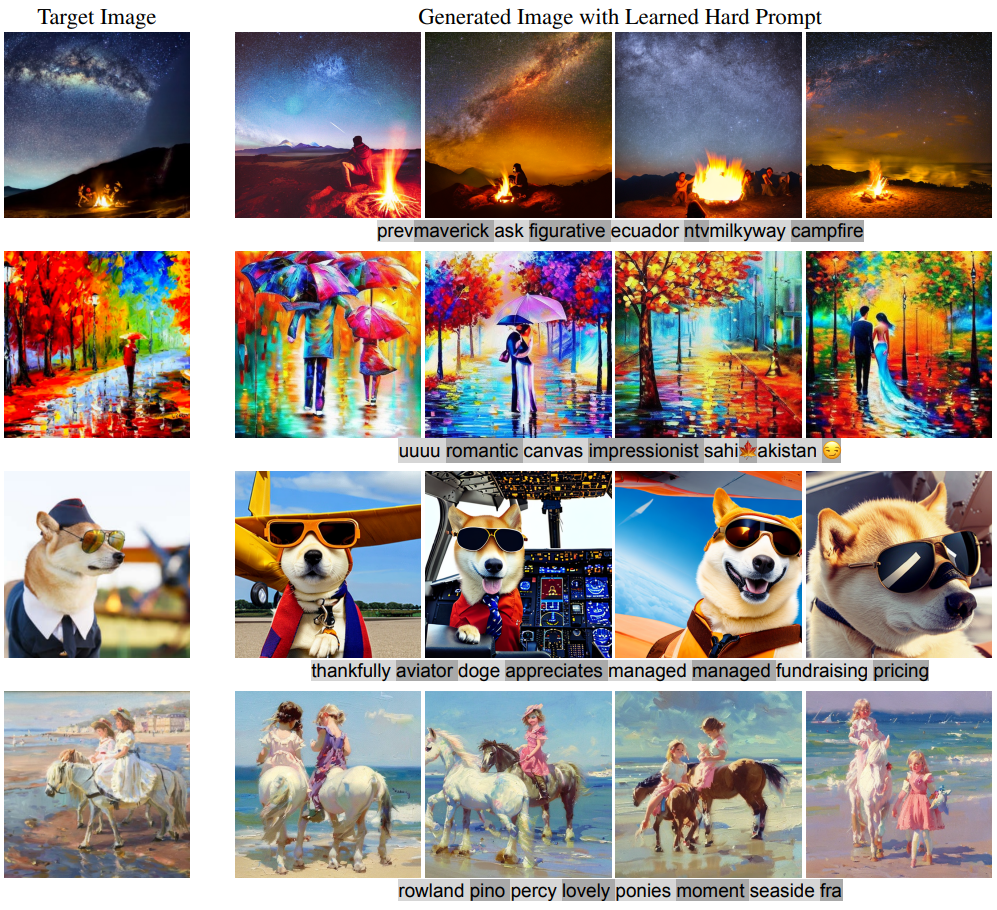
실제 존재하는 단어가 아닌 토큰 시퀀스도 있고 이모티콘도 사용하는 것을 볼 수 있다.
정량적 평가 : 이식성이 낮은 soft prompt는 잘 최적화되지 않음.

긴 prompt는 과적합됨.

Style Transfer
동일한 스타일 이미지 몇 장으로 hard prompt를 추출하고 새로운 개념에 적용 가능.

Prompt Concatenation

Prompt Distillation


Discrete Prompt Tuning with Language Models
NLP 모델끼리의 prompt 공유를 위한 text-to-text 상황에서의 실험.





