비디오를 이해하는 언어 모델

Abstract
Video Q-former, Audio Q-former를 통해 비디오의 시청각 콘텐츠를 이해하는 multi-modal framework인 Video-LLaMA 제안.
Related Works
Introduction
BLIP-2의 아이디어를 채택해 Video Q-former, Audio Q-former를 도입하고 multi-branch cross-model 고안.
Audio-text 데이터가 존재하지 않기 때문에 대응을 위해 ImageBind를 인코더로 활용.
Method
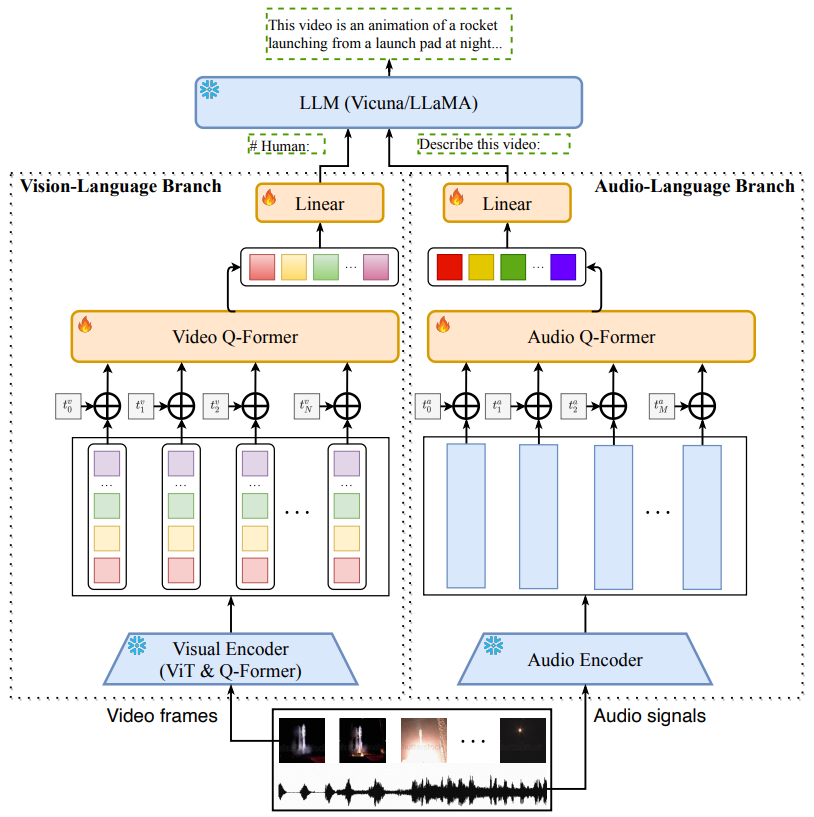
Architecture
Vision-Language Branch

이미지 인코더, 위치 임베딩 레이어, Q-Former, 최종 선형 레이어로 구성
각 프레임을 이미지 인코더로 인코딩하고 시간 정보를 위치 임베딩으로 주입한 뒤, BLIP-2와 동일한 아키텍처의 Q-Former에 입력하고 언어 모델과 같은 차원으로 맞추기 위해 최종 선형 레이어를 통과함.
Audio-Language Branch

오디오 인코더로 ImageBind 사용.
구체적으로 비디오를 M 구간으로 나눈 뒤에 spectrogram으로 변환하고 인코더를 통해 벡터로 임베딩하는 과정을 거침.
나머지는 video branch와 같음.
Multi-branch Cross-Modal Training
Training of Vision-Language Branch
노이즈가 많은 대규모 video-text 데이터에서 사전 훈련하고 고품질의 소규모 데이터셋에서 fine-tuning하는 방법으로 학습.
최근 언어 모델 훈련에서 매우 흔하게 쓰이는 방법.
Training of Audio-Language Branch
일단 audio-text 데이터 자체가 많이 존재하지 않음.
따라서 인코더로 ImageBind를 채택.
훈련은 visual-text 데이터로 진행되지만 ImageBind의 창발적인 특성 덕분에 오디오를 이해할 수 있게 된다고 한다.
(Visual data가 정확히 정의되어 있지 않은데, 스펙트로그램을 말하는 듯.
예시를 보면 음성 정보를 잘 이해하긴 하는 듯?)

Examples
사실 예시로 나와있는 정도로는 성능을 알 수 없어서 hugging face space에서 한 번 써볼려고 했는데 로딩이 너~무 오래 걸려서 포기함.





