Structure와 content를 조건으로 유연한 비디오 편집

Abstract
이미지 또는 텍스트 설명을 기반으로 비디오를 편집하는 structure and content-guided video diffusion model 제안.
Introduction
본 논문의 기여
- 미리 학습된 이미지 모델에 시간 계층을 도입하고 이미지와 비디오를 공동 학습 함으로써 비디오로 확장
- 예제 이미지나 텍스트로 비디오를 수정하는 모델
- 시간, content 및 structure 일관성에 대한 완전한 제어 가능
- 작은 이미지 세트에서 fine tuning하여 더 세부적인 사용자 정의 가능
Method
'Structure'는 피사체의 모양, 위치, 시간적 변화 등 기하학적, 역학적 특성으로 정의.
'Content'는 색상, 스타일 등 물체의 의미를 설명하는 feature로 정의.
우리의 목적은 structure를 유지하면서 content를 편집하는 것이며
비디오의 structure s와 프롬프트의 content c에 따라 비디오 x를 생성하는 모델 p(xㅣs,c)를 학습하는 것으로 정의한다.

Latent diffusion models
LDM (=Stable Diffusion)

Spatio-temporal Latent Diffusion
Temporal layer를 도입하여 아키텍처 확장.
다음과 같은 두 가지 형태의 residual, attention 블록이 있으며

Temporal transformer block에 프레임 인덱스의 학습 가능한 위치 인코딩 추가.
이미지는 단일 프레임 비디오로 간주.
프레임 수가 n일 때 b*n*c*h*w인 텐서는 spatial layers((b*n)*c*h*w), temporal convolutions((b*h*w)*c*n), temporal self-attention((b*h*w)*c*n)에서 각각 다르게 배열됨.
Representing Content and Structure
Conditional Diffusion Models
입력 비디오, 텍스트 프롬프트, 출력 비디오 세 쌍의 데이터셋이 없기 때문에 비디오 x에서 추출해야 하며,
따라서 s = s(x), c = c(x) 이고
예제 당 loss는
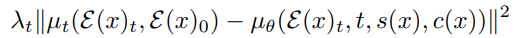
추론 중에는 비디오 y와 프롬프트 t가 입력되므로

Content Representation
Content 추출을 위해 비디오 입력의 경우 프레임 중 하나를 선택하고 CLIP 임베딩 사용.
CLIP은 기하학적 속성에 대해 둔감하고 의미론적 속성에 민감하기 때문에 적합하다.
Structure Representation
최대한 content를 배제하면서 structure를 추출하기 위한 도구로 depth estimate를 선택했다.

또한 보존할 structure의 양을 더 잘 제어하기 위해 blurring을 사용.
시간 단계 t와 같이 모델에 흐림 수준 ts를 제공하여 다양한 양의 정보에 적응하도록 함.
깊이 추정이 아니더라도 사람 얼굴 비디오 합성이 목적이라면 얼굴 랜드마크를 사용하는 등 다양한 도구를 사용할 수 있다.
Conditioning Mechanisms
Structure는 concatenation으로, content는 cross attention을 활용하여 조건화함.
Structure를 조건화하기 위해 MiDaS DPT-Large 모델로 깊이 맵을 추정하고 블러링, 다운샘플링, 인코딩을 거쳐 zt와 연결.

Sampling
DDIM 샘플링과 classifier-free guidance 사용.
Classifier-free guidance의 일반적인 식
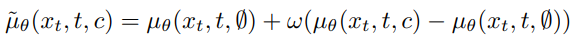
시간적 일관성을 제어하기 위해 수정된 식

같은 피라미터로 비디오와 이미지를 공동 학습한다.
µθπ는 각 프레임에 대해 개별적으로 이미지 예측한 결과, µθ는 비디오 예측의 결과이다.
셋째 줄이 일반적인 classifier-free guidance의 컨디셔닝 정도를 조절하는 항인 것을 고려하면, 두 번째 줄은 시간적 일관성의 정도를 조절하는 항인 것을 알 수 있다.
Optimization
12.5%로 이미지, 87.5%로 비디오를 학습한다.
모델 학습은 여러 단계로 이루어져 있는데,
- 사전 훈련된 text-to-image 모델의 가중치로 초기화
- 조건을 CLIP 텍스트 임베딩에서 CLIP 이미지 임베딩으로 변경하고 이미지에서만 학습
- 시간 계층을 추가한 후 이미지, 비디오에서 공동 학습
- Structure 조건을 추가하고 학습
- 0~7 사이의 ts 값으로 블러링하고 학습
Results
결과는 Project Page에서 보세용...
퀄리티는 현재까지의 비디오 편집 작업 중에서는 최고인 듯???

'논문 리뷰 > Diffusion Model' 카테고리의 다른 글
| Consistency Models (0) | 2023.04.14 |
|---|---|
| InstantBooth: Personalized Text-to-Image Generation without Test-Time Finetuning (0) | 2023.04.13 |
| One Transformer Fits All Distributions in Multi-Modal Diffusion at Scale (UniDiffuser) (0) | 2023.04.13 |
| Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators (0) | 2023.04.11 |
| Token Merging for Fast Stable Diffusion (0) | 2023.04.06 |
| Composer: Creative and Controllable Image Synthesis with Composable Conditions (0) | 2023.02.28 |



