Abstract
최적화 단위를 개별 답변에서 개별 추론 단계로 분해하여 긴 수학적 추론 능력 향상
[Github]
[arXiv](2024/06/26 version v1)
Step-DPO
Step-Wise Formulation

Our Solution

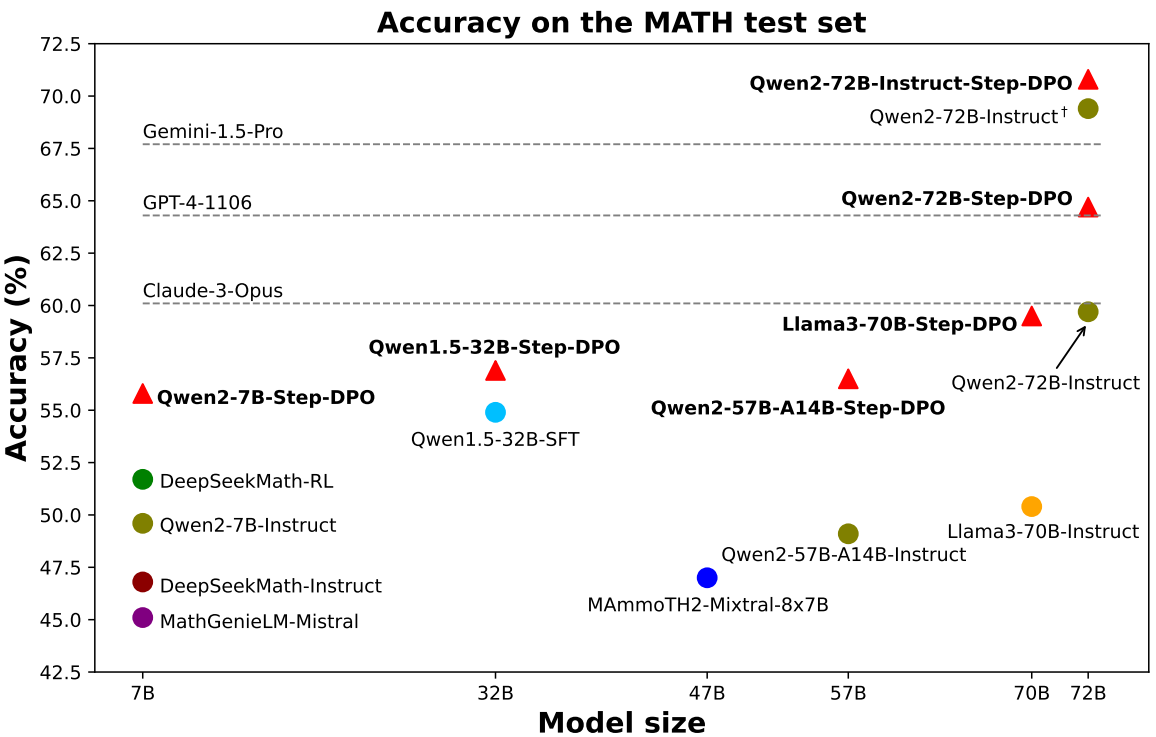
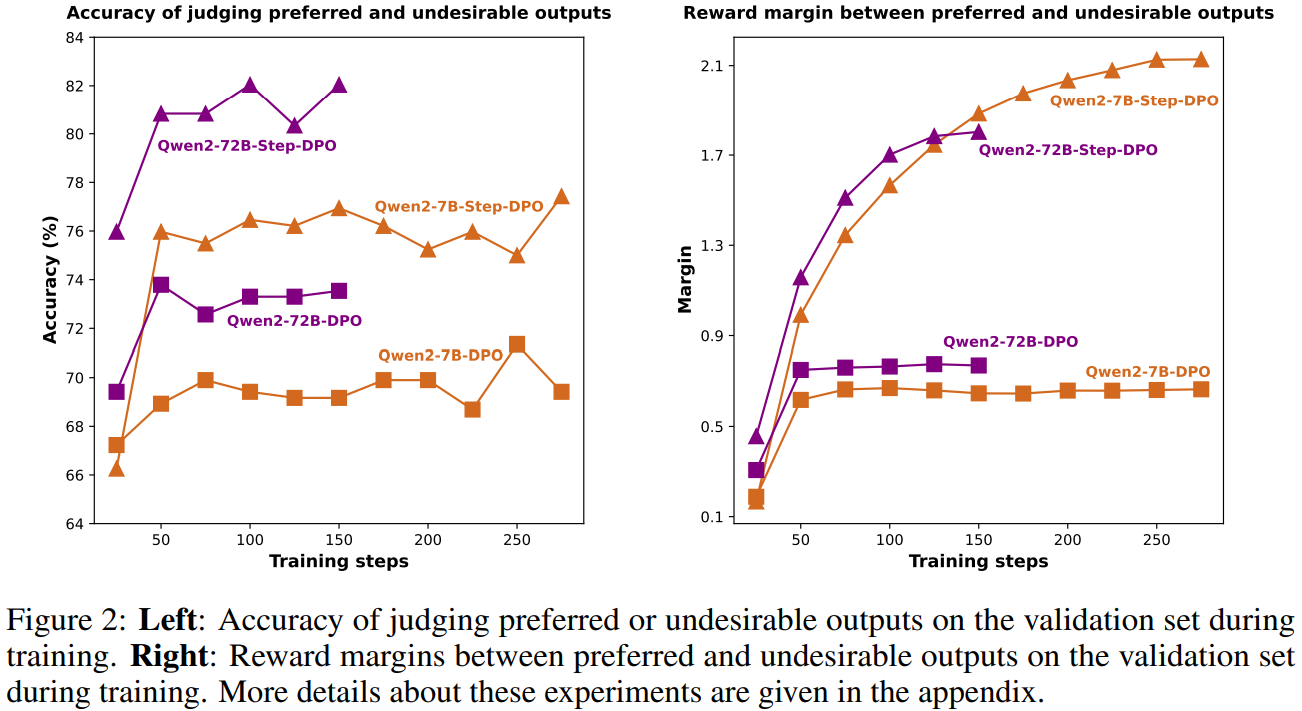
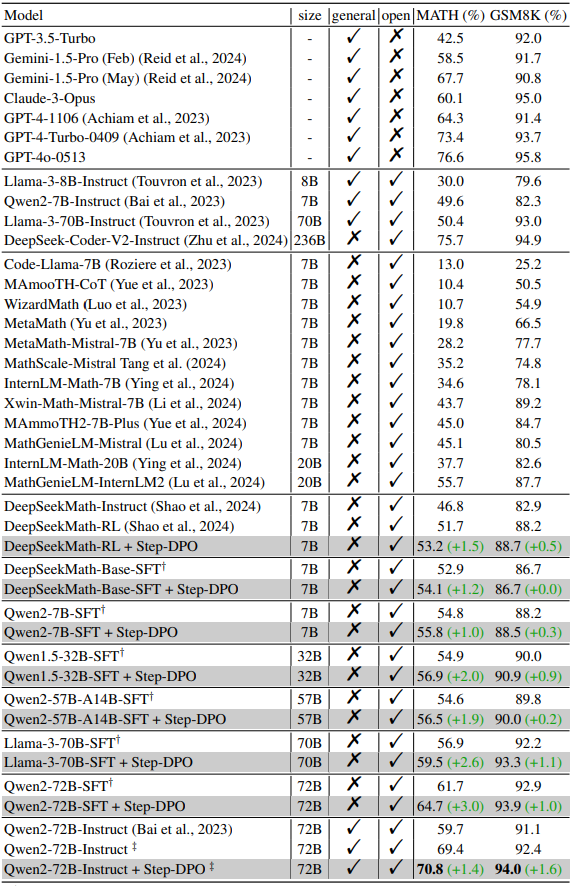
DPO는 수학 문제와 같은 긴 추론 작업에서는 미미한 개선만 제공하는데, 이는 첫 번째 오류가 긴 추론 과정의 중간에 나타나고 이를 거부하면 초반의 올바른 추론 단계도 무시되어 학습에 부정적인 영향을 끼치기 때문이다.
Step-DPO는 답변 y를 일련의 추론 단계로 분해하여

s를 기준으로 손실을 계산한다.
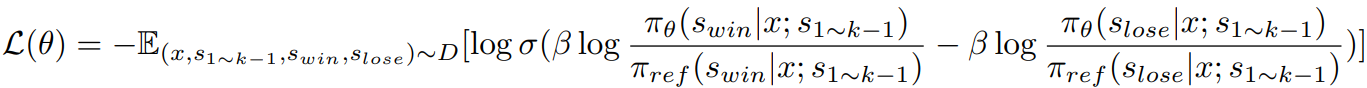
In-Distribution Data Construction

- 데이터셋 D0 = {(x, ŷ)}에 대해 CoT 추론( Let’s think step by step. Step 1: )을 사용하여 단계별 추론 궤적을 생성하고 잘못된 추론 데이터셋인 D1 = {(x, ŷ, y)}을 수집한다.
- GPT-4를 통해 첫 번째 오류가 등장한 추론 단계를 찾고 잘못된 추론 단계 slose를 포함하는 데이터셋을 수집한다. D2 = {(x, ŷ, s1 ~ k-1, slose)}
- s1 ~ k-1을 사용하여 정답과 일치하는 출력을 샘플링하고 swin으로 사용한다.
유의할 점은 정답은 맞지만 과정이 틀린 추론 궤적이 생성될 때가 있으므로 필터링이 필요할 수도 있다.
또한 외부 모델이나 인간이 틀린 답을 교정하면 OOD 이므로, gradient 감소 문제가 생긴다. 참조 모델을 통해 교정하는 것이 좋다.
Experiments