Abstract
LLM에서 값비싼 MatMul 작업을 완전히 제거
메모리 사용량을 최대 60%까지 줄임
[Github]
[arXiv](2024/06/18 version v5)
Method
MatMul-free Dense Layers with Ternary Weights
Dense layer를

3항 가중치 {-1, 0, +1}를 가진 BitLinear 모듈로 변환하여 MatMul 연산을 누적 덧셈 연산으로 변환할 수 있다.
Hardware-efficient Fused BitLinear Layer
BitNet은 BitLinear 입력 전 RMSNorm을 요구하며 HBM과 SRAM으로 구성된 현대 GPU의 구조를 고려할 때 기존 구현은 많은 I/O 작업을 도입하여 하드웨어 효율적이지 못하다. 하드웨어를 고려한 Fused RMSNorm 제안.
MatMul-free Language Model Architecture
MatMul-free Token Mixer
현대 LM에서 가장 일반적인 token mixer는 self-attention이다. 하지만 self-attention은 양자화 시 중요한 outlier를 잃어버리기 때문에 적합하지 않고, 대신 LSTM의 효율적인 버전인 GRU를 기반으로 MLGRU (MatMul-Free Linear GRU)를 구축한다.
MLGRU의 수정 사항은 GRU의 성질을 유지하면서 MatMul이 필요하지 않게 한다.
- tanh activation 제거
- 데이터 의존적 output gate 추가
- c의 계산을 단순화
- 가중치 행렬을 삼항 가중치로 변환
GRU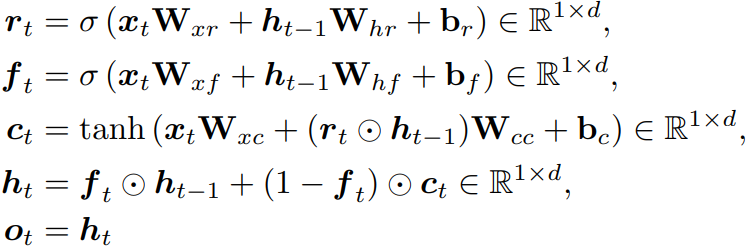 |
MLGRU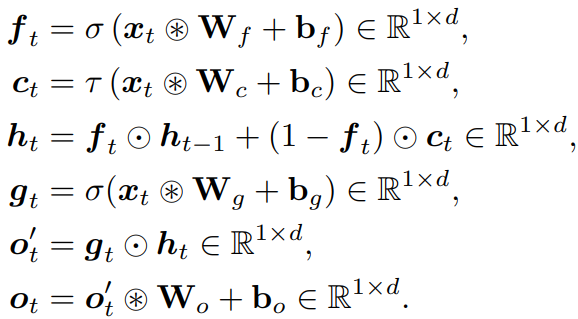 |
MatMul-free Channel Mixer
MatMul 없는 GLU: (⊛ = 삼항 누적 덧셈, ⊙ = 요소별 곱셈)
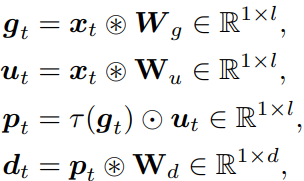
Training Details
- 미분 불가능한 연산 처리를 위해 STE 사용
- 삼항 가중치를 훈련하기 위해서는 기존보다 큰 학습률이 필요
- Transformer 훈련에서는 최소 학습률을 설정하는 것이 일반적이다. 하지만 여기서는 코사인 스케줄을 유지하다가 중간에 학습률을 절반으로 줄이고, 최종 훈련 단계에서 학습률이 0에 가깝도록 한다. 손실을 크게 감소시킨다고 함.
Experiments
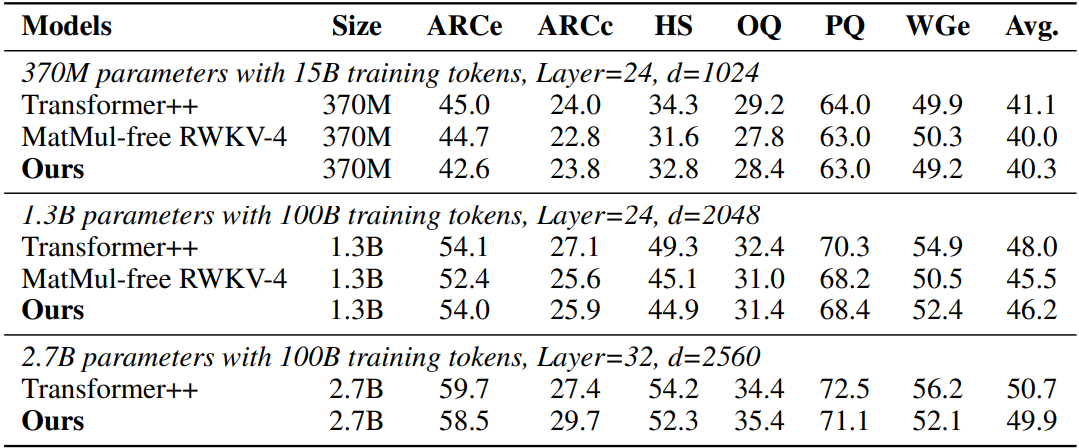
Downstream task
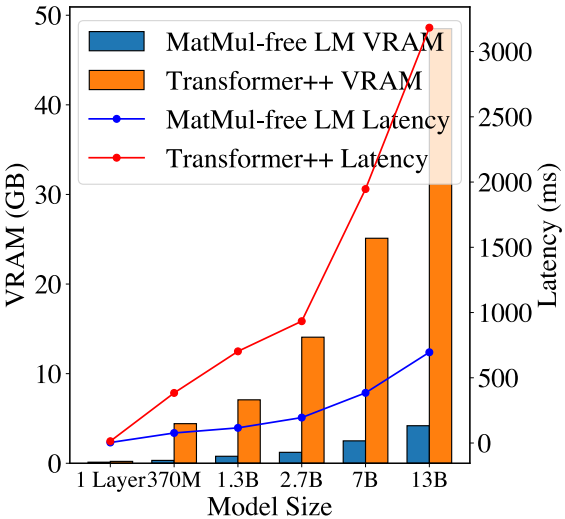
추론 시 메모리 소비 및 대기시간 비교