Abstract
훈련 목표의 간단한 수정을 통해 기억 능력을 감소시켜 정보 누출 위험을 피하는 Goldfish Loss 제안
[Github]
[arXiv](2024/06/14 version v1)
Goldfish Loss: Learning Without Memorizing
일반적인 causal language modeling:

Goldfish loss는 goldfish mask G ∈ {0, 1}를 통해 G = 0일 때 토큰의 손실을 무시하는 것이다.
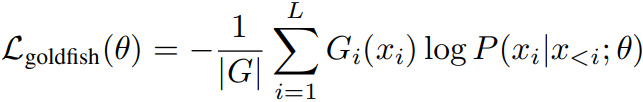
이는 모델이 테스트 시 훈련 샘플을 '재현'하려는 것을 막음으로써 정보 누출을 완화할 수 있다.
마스킹 방법으로는 k번째 토큰을 무시하거나 1/k 확률로 무시하는 방법들이 있다.
Robust Handling of Duplicate Passages with Hashing
특정 문서의 경우에는 (e.g. 일론 머스크에 대한 뉴스 기사의 경우 "Elon Musk"라는 단어가 여러 번 사용된다.) 같은 단어가 여러 번 사용될 수 있다. 이런 경우 그 단어를 몇 개만 무시하는 것은 암기를 막는 데 도움이 되지 않는다.
n-gram 해시 함수를 통해 중복 구절을 식별하고 일관성 있게 무시함으로써 특정 구절의 특정 단어를 해당 문서에서 지속적으로 무시할 수 있다.
Can Goldfish Loss Prevent Memorization?
실제로 goldfish loss는 암기 능력을 방해한다.

Can LLMs Swallow the Goldfish Loss? Testing Impacts on Model Performance
벤치마크 성능 차이 없음

한 가지 단점은 무시되는 토큰을 보상하기 위해 step이나 배치 크기를 늘리는 등의 추가 자원이 필요하다는 것이다.




