Abstract
범용 분할 모델을 visual encoder로 사용하여 pixel-level 능력을 향상하고 다양한 유형의 입력을 처리할 수 있는 단일 모델인 OMG-LLaVA 제안
[Github]
[arXiv](2024/06/27 version v1)
Methodology
Task Unification
3가지 유형의 토큰이 있다.
텍스트 토큰 Tt, 픽셀 중심 시각 토큰 Tpv, 객체 중심 시각 토큰 Tov.
OMG-LLaVA에서 LLM이 입출력 가능한 토큰 유형은 다음과 같다.
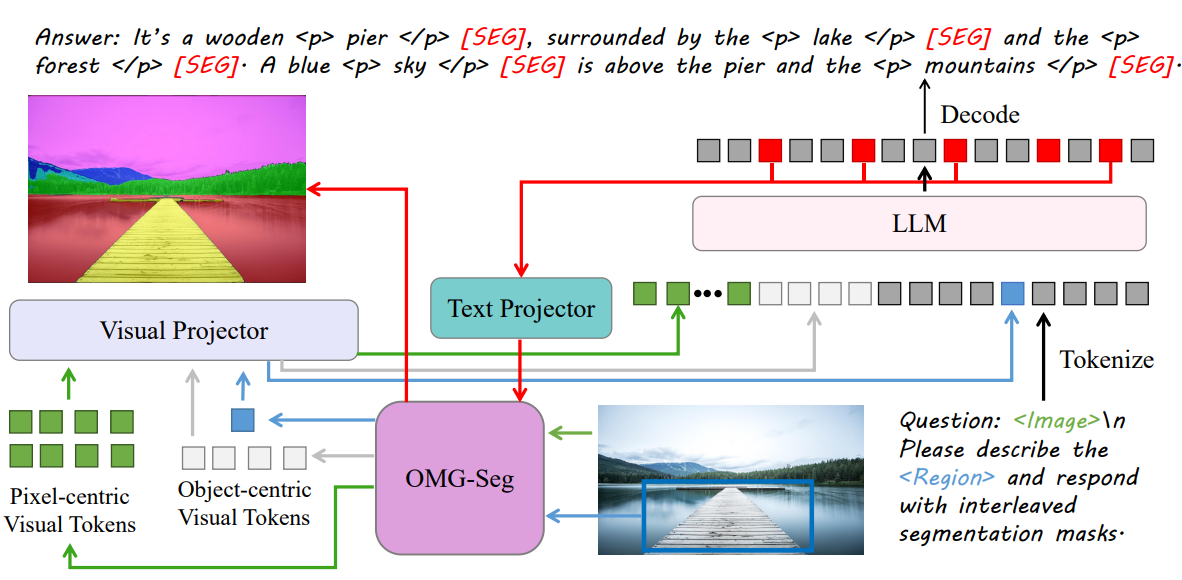
OMG-LLaVA Framework
Image Encoder
ConvNeXt-L 기반 CLIP 모델 사용.
OMG Decoder
학습 가능한 쿼리 세트가 입력에 포함되며 MCA, SA로 이루어져 있다.
오른쪽 그림은 입력 visual prompt에 따라 MCA layer의 attention mask를 수정하는 모습이다.
Perception Prior Embedding
사전 훈련된 OMG-Seg는 훈련 내내 고정된 상태로 유지되는데, 그러면 LLM과 잘 정렬되지 않기 때문에 object query를 image feature에 통합하는 perception prior embedding 과정을 추가한다.
Query로부터 얻은 마스크와 신뢰도를 바탕으로 각 픽셀의 마스크 점수를 얻고 Q를 곱하여 각 픽셀에 대한 가중 객체 쿼리를 얻는다. 여기에 F를 추가하여 Tpv를 얻고
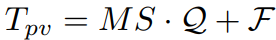
그리고 필터링된 foreground object query Tov와 연결하여 OMG-Seg의 출력을 형성한다.
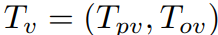
Visual Projector and Text Projector
Pixel-centric visual token, object-centric visual token을 LLM space에 매핑하고 [SEG] 토큰을 visual space에 매핑하는 데 3개의 MLP가 각각 사용된다.
Instruction Formulation
OMG-LLaVA는 여러 가지 작업을 처리할 수 있는데, 이들을 통합하기 위해 <Image>, <Region>, [SEG] 토큰을 사용하여 instruction을 공식화한다.
Training Setup
첫 번째 단계에서는 projectors만 훈련하고
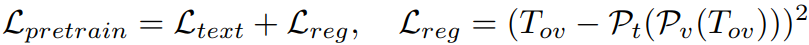
두 번째 단계에서는 LLM에 LoRA를 추가하여 같이 훈련한다. (OMG-Seg는 사전 훈련된 모델을 사용하고 훈련하지 않는다.)
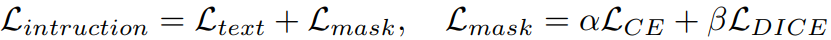
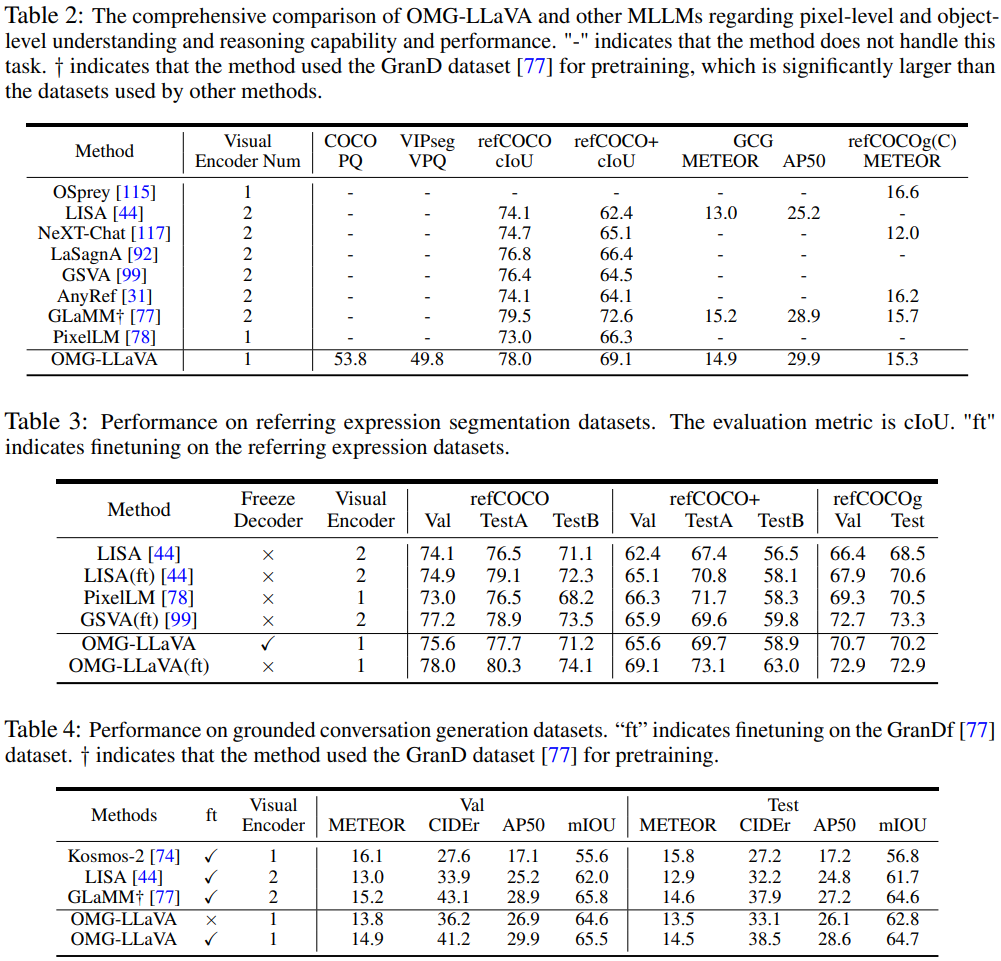
Experiment
OMG-Seg
We propose OMG-LLaVA, a new and elegant framework combining powerful pixel-level vision understanding with reasoning abilities. It can accept various visual and text prompts for flexible user interaction. Specifically, we use a universal segmentation metho
lxtgh.github.io