Abstract
Grounding DINO에서 탐지 성능, 추론 속도 개선
[Github]
[arXiv](2024/05/16 version v1)
Model Training
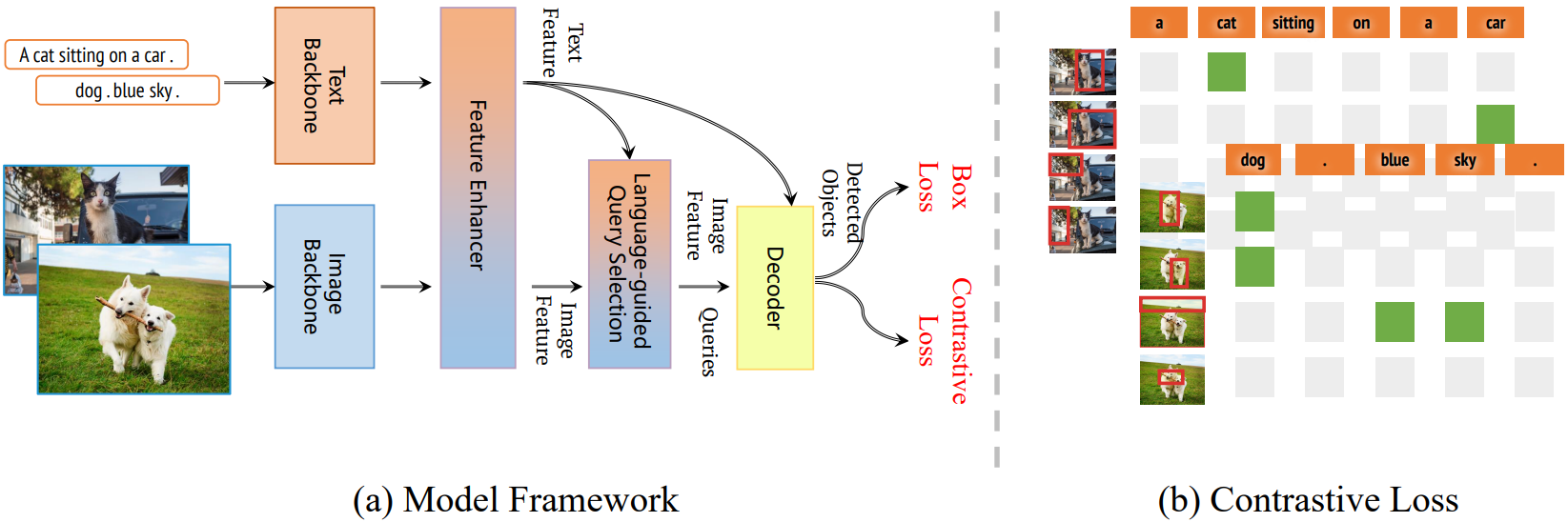
Grounding DINO 1.5 Pro
1. 더 큰 vision backbone 사용: ViT-L
2. 훈련 중 negative sample의 비율을 높임
3. Grounding-20M이라고 하는 고품질 grounding dataset을 제작하여 훈련함
Grounding DINO 1.5 Edge
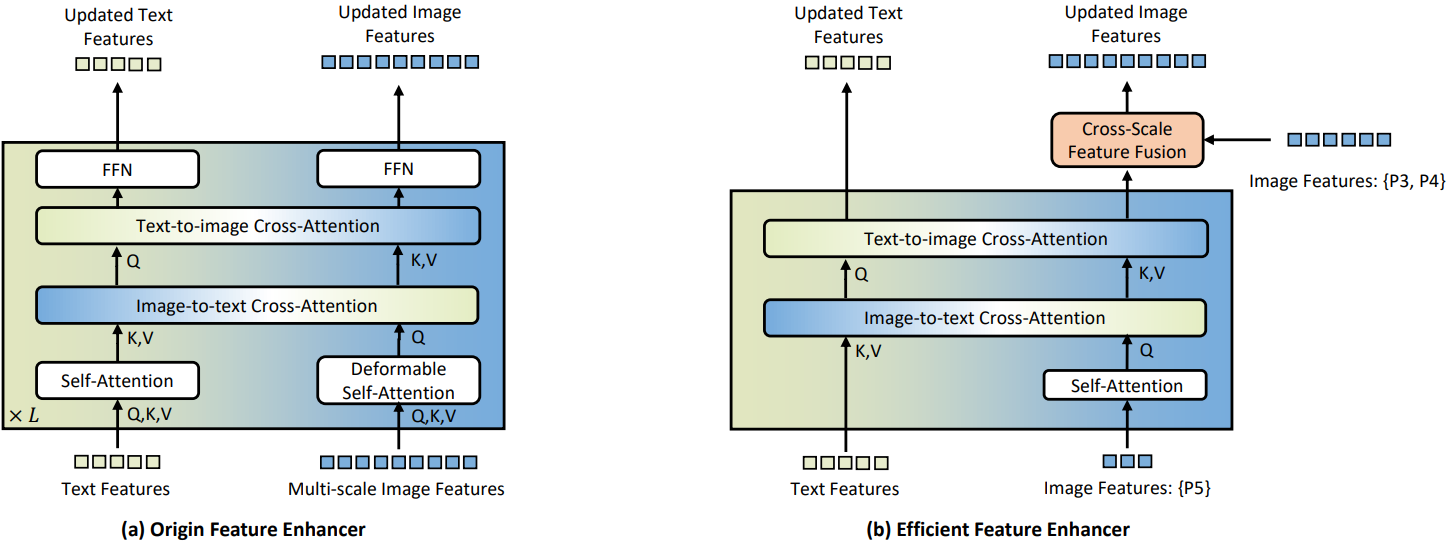
Image backbone은 feature enhancer에 multi-scale feature를 제공하는데, 저해상도 feature는 enhancer의 계산량만 가중시킬 뿐 많은 정보가 존재하지 않으므로 P5-level feature만 제공하고 P3, P4-level의 feature는 cross-scale feature fusion module을 이용해 통합한다. 추가로 각 feature의 self-attention 간소화.
Image backbone으로 효율적인 EfficientViT-L1 채택.
Model Evaluation





