
Abstract
Image-text pretraining을 분류 작업으로 재구성하여 성능을 유지하면서도 빠르게 훈련할 수 있는 CatLIP 제안
[Github]
[arXiv](2024/04/24 version v1)
CatLIP: Contrastive to Categorical Learning
대조 학습을 통한 image-text pretraining을 분류 작업으로 casting 한다.
Global pair와의 유사성을 계산해야 하는 대조 학습보다 훨씬 빠르다.
Caption-derived classification labels
아래와 같은 과정을 통해 웹에서 image-text 데이터를 수집하여 기존의 CC3M dataset을 증강한다.
이 과정에서 WordNet이 사용되므로 class 대신 synset이라는 단어를 쓴다.

다양성과 샘플 수가 크게 증가하였다.


CatLIP pre-training
샘플이 적은 synset을 제거하고 분류 작업으로 훈련한다.
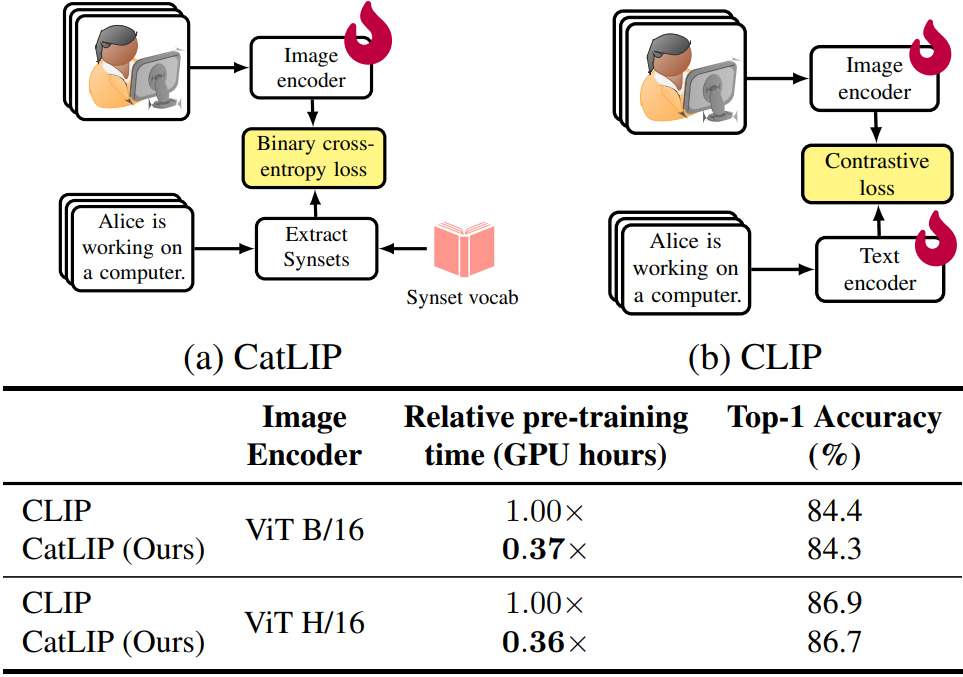
훨씬 빠르게 최적화되면서 성능 저하는 없는 수준이다.
Linear probing 결과: (Linear probing: 사전 훈련된 모델을 head만 바꿔서 downstream task에 사용함)




