
Abstract
Grid Attention, Fuzzy PE를 통해 낮은 비용으로 다양한 해상도의 이미지를 처리하는 Vision Transformer with Any Resolution (ViTAR) 제안
[arXiv](2024/03/28 version v2)
Methods
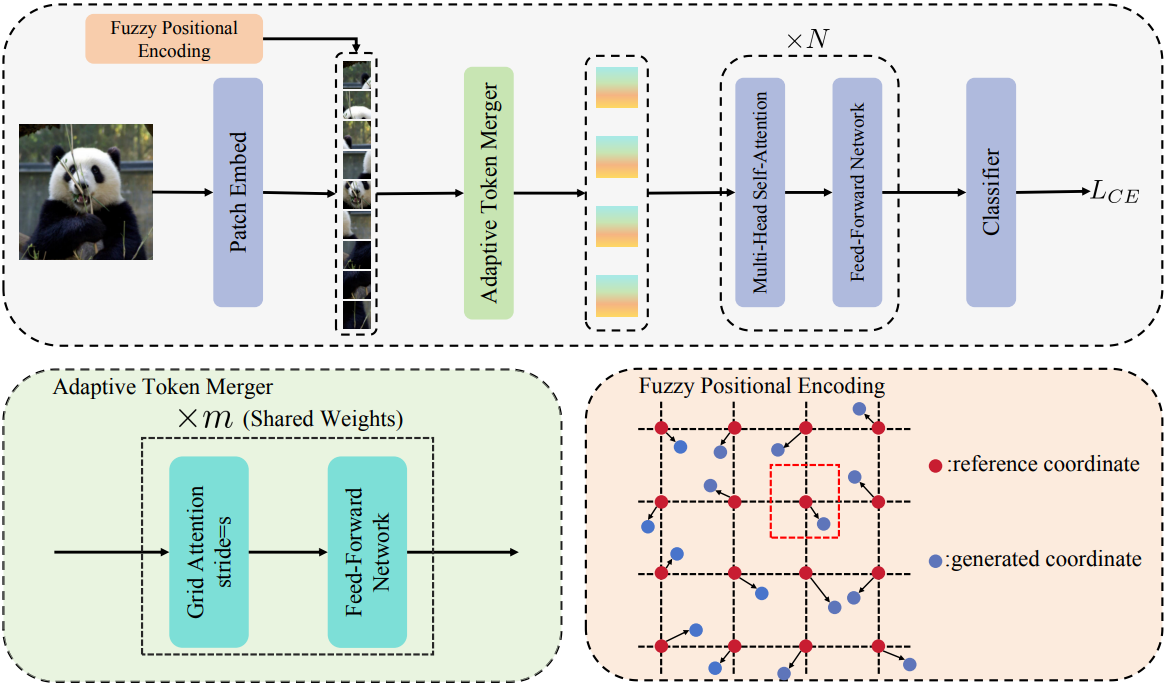
Adaptive Token Merger (ATM)

입력을 일정한 크기의 grid로 나누고 그리드 내 평균 토큰을 Q, 나머지를 K, V로 attention을 수행한 뒤 FFN을 통과한다.
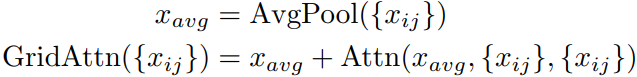
동일한 가중치를 가진 ATM block을 여러 번 반복하여 목표 해상도 Gh × Gw 까지 줄인다.
가장자리의 grid에 패딩 토큰만 존재하는 경우를 방지하기 위해 가장자리 근처의 각 grid에 패딩을 적절하게 배치하는 grid padding을 사용.

Fuzzy Positional Encoding
기존의 위치 인코딩 방법들은 입력 해상도의 변화에 취약하다.
Fuzzy PE는 훈련 시 토큰의 위치 정보에 무작위 offset을 추가한 임베딩을 사용.

Offset 크기가 0.5 이하라 Grid attention에 속하는 토큰의 수는 변하지 않을 듯?
추론 시에는 정확한 PE를 사용하며, 입력 해상도가 변경될 경우 PE에 대한 보간을 수행한다.
훈련에서 Fuzzy PE에 대해 적응했기 때문에 보간 된 위치에 대해서도 적응할 수 있다.
Multi-Resolution Training
다른 처리 없이 기본적인 cross-entropy loss에만 의존하여 다양한 해상도에서 훈련한다.
Experiments
Classification

Detection


Segmentation





