[arXiv](2024/02/02 version v1)
 |
 |
 |
Abstract
Bounding box, motion path를 통해 비디오를 제어할 수 있는 Boximator 제안
Boximator: Box-guided Motion Control
- Model architecture
- Data pipeline
- Self-tracking
- Multi-Stage training procedure
- Inference
Model Architecture
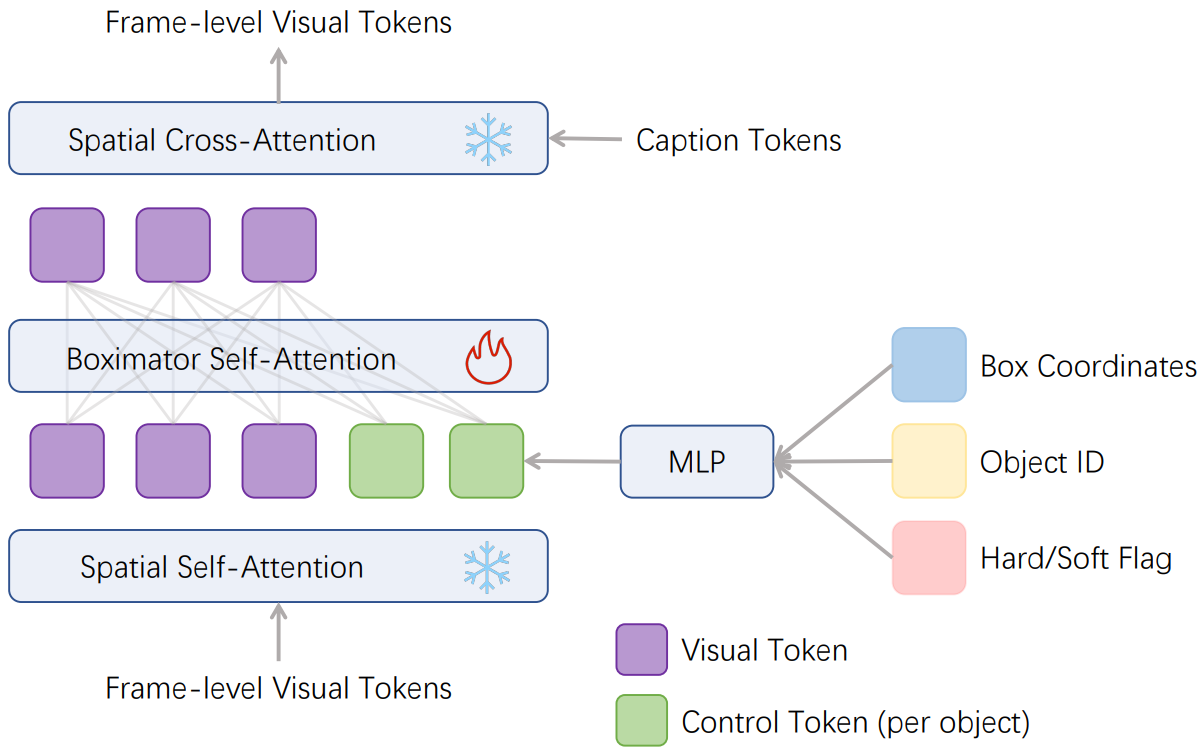
Spatial attention block의 self-attention과 cross-attention 사이에 새로운 attention block을 삽입한다.


bloc : box의 좌표
bid : 여러 개의 box가 있을 때 box의 id를 RGB color로 구분
bflag : Hard box의 경우 1, 나머지는 0인 boolean 값
Data Pipeline
WebVid에서 동적인 하위 집합만 선별하여 110만 개의 비디오 클립 생성.
MLLM을 사용하여 첫 번째 프레임에 대한 캡션을 생성하고 명사를 추출, 각 명사에 대한 bbox를 생성한다.
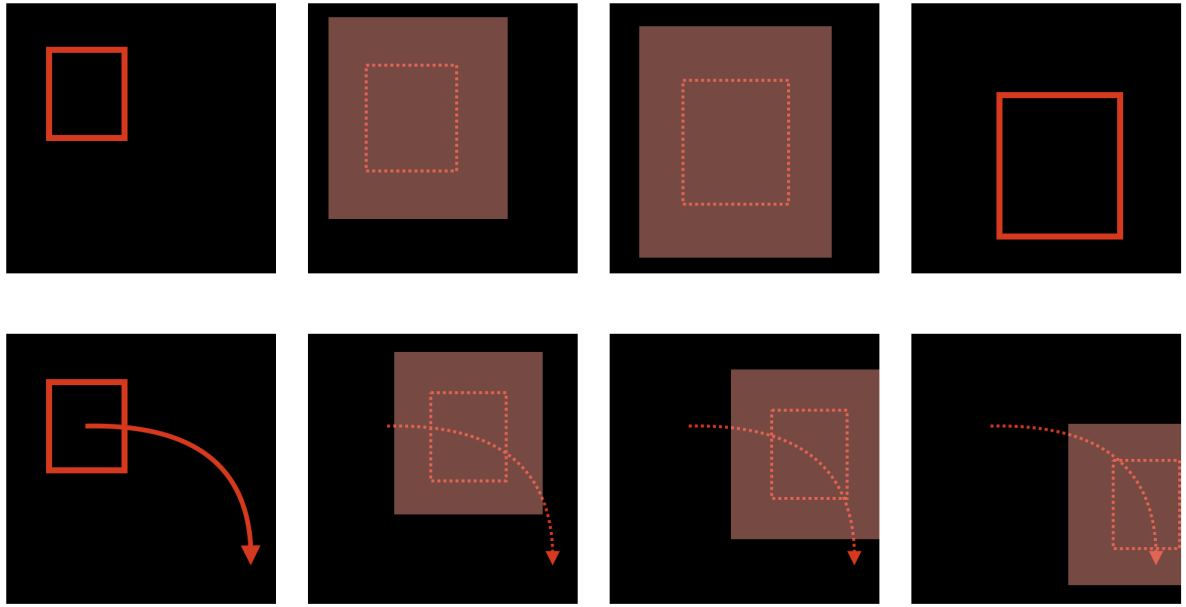
훈련 중에 비디오를 일정한 종횡비에 따라 무작위로 자른 다음(흰색 box) bbox를 이 영역에 투영해 개체 이동을 표현.

Self-Tracking
모델이 각 객체를 생성함과 동시에 색상이 지정된 bbox도 생성하도록 훈련하고, 모든 프레임에서 bbox를 Boximator 조건에 정렬한다.
Emu Edit에서 Diffusion Model이 이러한 computer vision 작업이 가능하다는 것을 보여주었다.
Self-Tracking training이 완료되면 동일한 데이터셋을 사용하여 bbox를 생성하지 않도록 추가로 훈련한다.
놀라운 점은 bbox를 생성하지 않도록 다시 훈련해도 조건에 대한 정렬 기능은 여전히 유지된다는 것이다.

Multi-Stage Training Procedure
1-stage : Ground truth를 hard box로 하여 훈련한다. Hard box가 soft box보다 배우기 쉽기 때문이다.
2-stage : Hard box의 80%를 soft box로 대체한다. Soft box는 hard box를 무작위로 확장하여 해당 영역 안에 bbox가 있기만 하면 된다.
3-stage : 1,2 stage는 self-tracking을 사용하며, 3-stage에서는 self-tracking을 사용하지 않고 2-stage 훈련을 계속한다.
Inference
사용자가 일부 프레임의 hard box 또는 motion path를 제공하면, 선형 보간을 통해 나머지 프레임에 soft box를 배치한다.
Experiments
Baseline: PixelDance or ModelScope
원래 모델 가중치를 고정하고 추가된 모듈만 훈련한다.
Boximator: Generating Rich and Controllable Motions for Video Synthesis
Our demo website is under development and will be available in the next 2-3 months. Before that, we have prepared an early experience channel for everyone. You can try Boximator by emailing wangjiawei.424@bytedance.com. We will reply to you with the genera
boximator.github.io



