LLM agent system을 통해 prompt에 적합한 확산 모델을 동적으로 선택하여 이미지 생성
[Github]
[arXiv](2024/01/18 version v1)

Abstract
LLM을 통해 prompt를 분석하고 도메인별 전문가 확산 모델을 통합할 수 있는 시스템인 DiffusionGPT 제안
여기서 전문가 확산 모델: Civitai와 같은 개인화 모델들을 말함
Methodology
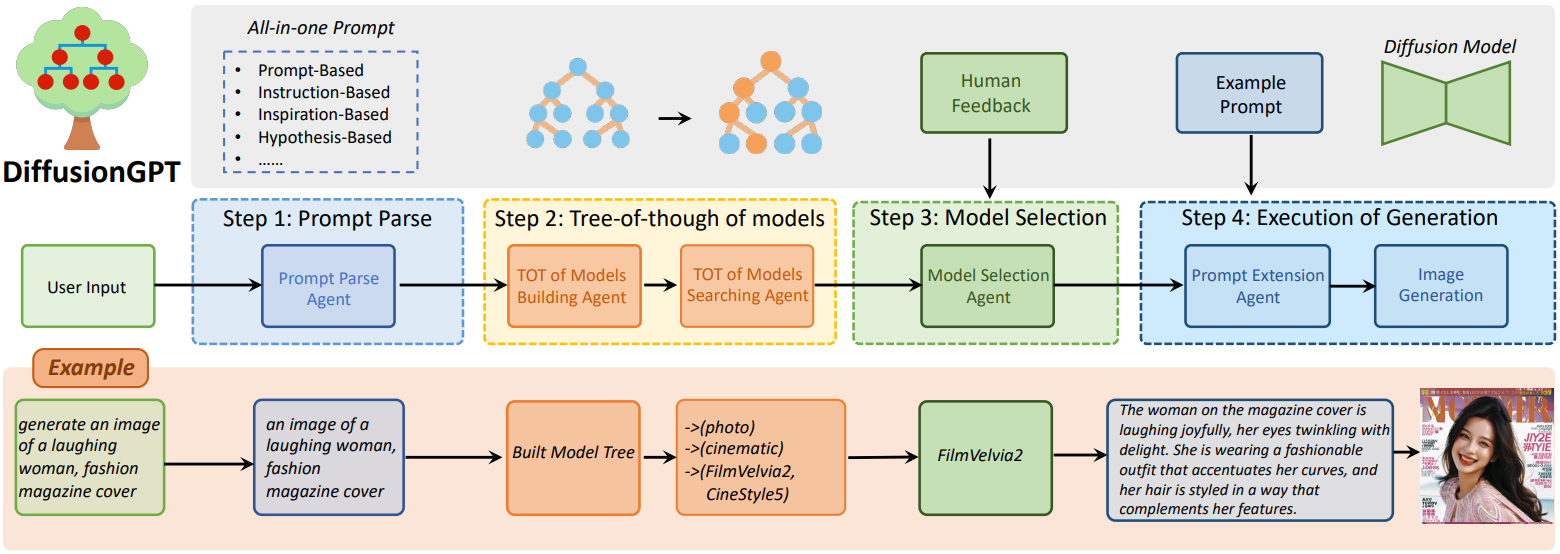
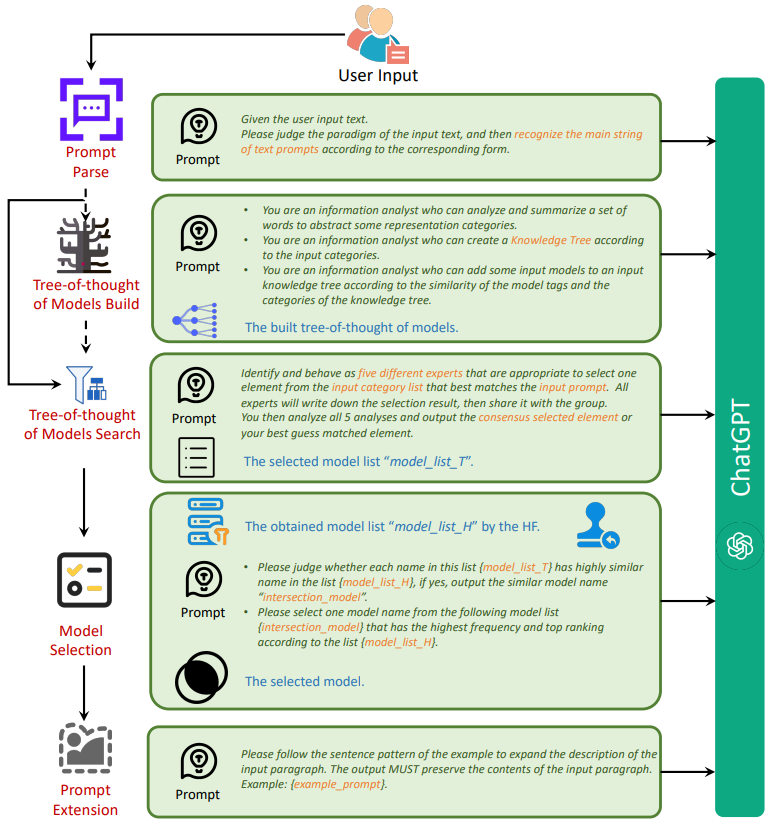
- Prompt Parse
- Tree-of-thought of Models
- Model Selection
- Execution of Generation
Prompt Parse
LLM이 prompt를 분석하여 확산 모델에 사용할 적절한 prompt를 생성한다.
- Prompt-based : "a dog" → a dog"
- Instruction-based : “generate an image of a dog” → “an image of a dog”
- Inspiration-based : “I want to see a beach” → “a beach”
- Hypothesis-based : “If you give me a toy, I will laugh very happily” → “a toy and a laugh face”
Tree-of-thought of Models
사용 가능한 개인화 확산 모델의 태그 속성을 입력하면 모델 구축 LLM agent가 잠재적 카테고리를 분석하여 트리 구조로 정리한다.
또한 모델 검색 agent는 입력 prompt에 가장 알맞은 모델 후보 집합을 검색할 수 있다.
Model Selection
LLM이 인간 선호도에 최적인 모델을 결정하는 데 어려움이 있기 때문에, human feedback을 사용한다.
보상 모델을 통해 10000개의 prompt에 대한 각 모델의 출력에 점수를 미리 매긴다.
입력 prompt를 받으면 10000개의 prompt 중 입력과 가장 유사한 5개의 prompt를 식별하고 각 prompt에서 점수가 가장 높은 5x5의 후보 세트를 생성한다. 모델 검색 agent의 후보 집합과 후보 세트의 점수를 고려해 최종 모델을 선택한다.
Execution of Generation
Prompt가 자세할수록 더 좋은 이미지가 생성되기 때문에 prompt 확장 agent를 통해 보강한다.
확장된 prompt와 최종 모델을 통해 최종 이미지를 생성.

Experiments


'논문 리뷰 > Language Model' 카테고리의 다른 글
| Fast Inference from Transformers via Speculative Decoding (0) | 2024.01.25 |
|---|---|
| Truncation Sampling as Language Model Desmoothing (η-sampling) (0) | 2024.01.25 |
| Self-Rewarding Language Models (0) | 2024.01.24 |
| Towards Conversational Diagnostic AI (AMIE) (0) | 2024.01.18 |
| Mixtral of Experts (Mixtral 8x7B) (0) | 2024.01.11 |
| Mistral 7B (0) | 2024.01.11 |



