다른 언어로의 전이 학습에 대한 조사
[arXiv](2024/01/02 version v1)
Abstract
Language generation, following instruction 능력을 비영어권 언어로 효과적으로 이전하는 방법에 초점을 맞추어 1440 이상의 GPU 시간이 축적될 동안 어휘 확장, 추가 사전 훈련, 명령어 튜닝과 같은 요인이 전이에 미치는 영향을 분석했다.
Background and Overview
Instruction-following LLM을 개발하기 위한 필수 단계 소개.
Step 1: Pretraining to acquire language capability and knowledge
Large corpus D가 주어지면 prefix sequence를 기반으로 다음 손실을 최소화:
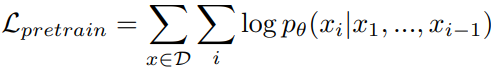
Step 2: Instruction tuning for aligning with human intent
Supervised Fine-Tuning(SFT): 작업 명령 I, 응답 Y에 대해 다음을 최소화하는 지도 학습.
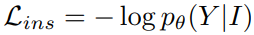
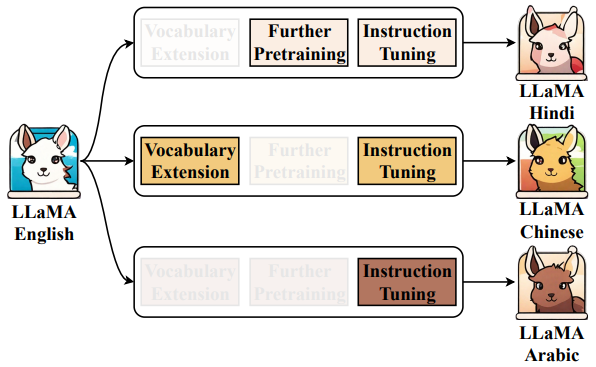
Extrapolating LLMs to non-English languages
LLM을 비영어권 언어로 외삽하는 것은 다음 세 단계로 구성된다.
- 어휘를 확장하여 대상 언어의 토큰 추가
- 목표 언어로 이전하기 위한 추가 사전 훈련
- 목표 언어로 SFT 수행
Experimental Setup
Models: LLaMA, LLaMA2, Chinese LLaMA, Chinese LLaMA2, Open Chinese LLaMA
Train Datasets:
- BELLE: large-scale Chinese instruction tuning dataset
- Bactrain-X: 52개 언어로 된 명령어와 응답 포함
Eval Datasets: LLM-Eval, C-Eval, MMLU, AGI-Eval, Gaokao-Bench
Main Results
The Impact of Vocabulary Extension on Transfer
왼쪽부터 정확성, 유창성, 논리적 일관성, 무해성, 정보성, 평균
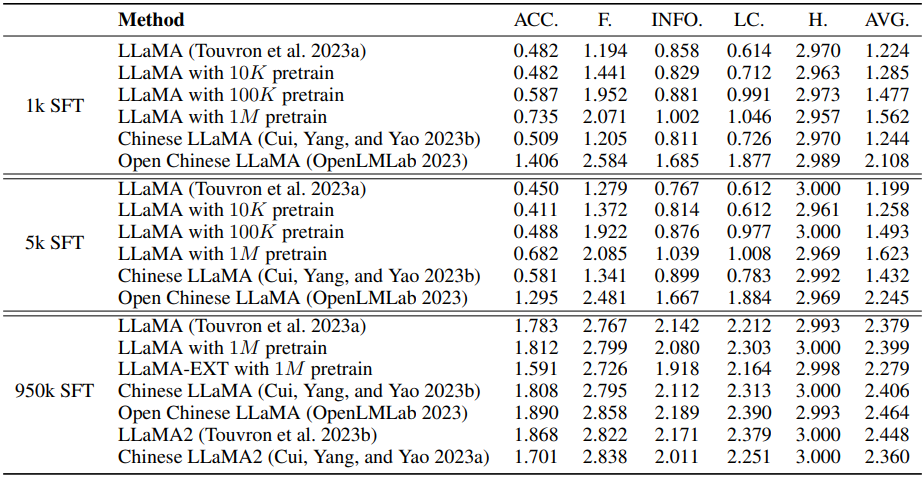
놀랍게도 어휘 확장 없이 1M 개의 중국어 문장에 대해 사전 훈련한 LLaMA는 어휘를 확장한 Chinese LLaMA의 성능을 크게 능가했으며, 어휘를 확장하고 사전 훈련한 LLaMA-EXT보다 성능이 좋았다.
이는 적은 수의 토큰에 대해서 훈련할 때 어휘 확장이 좋은 선택이 아님을 보여준다.
How about the Original English Capabilities

중국어로 사전 훈련하면 L(LaMA)의 원래의 영어 능력이 저하되어 english perplexity가 높아졌다.
Open Chinese LLaMA를 영어와 중국어에 대해 공동 훈련한 경우(맨 오른쪽)에 chinese perplexity는 감소하면서 english perplexity도 크게 증가하지 않았다. 공동 훈련을 통해 원래 언어 능력을 잃는 것을 완화할 수 있다.
Extending the Analysis to Multiple Languages
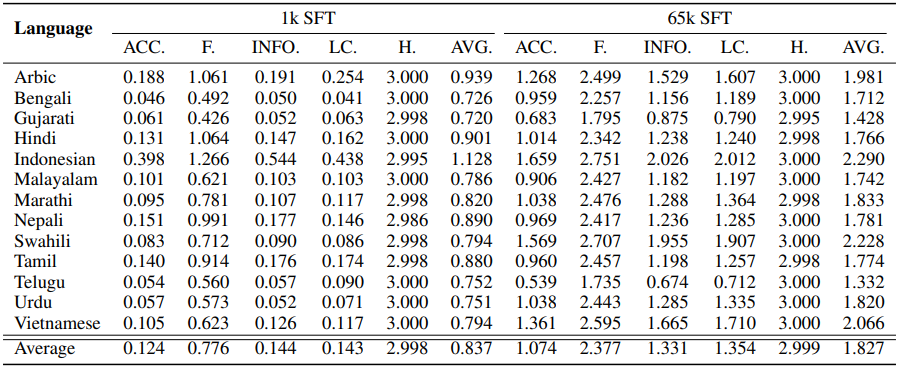
LLaMA를 어휘 확장 없이 다른 언어에 대해 훈련한 결과 중국어와 마찬가지로 목표 언어의 이해력이 빠르게 상승하였다.
이전 섹션에서 어휘 확장이 부정적인 영향을 미친다는 것을 관찰했다. 연구진은 LLM 내에 언어 간 의미 정렬이 존재하며, 어휘 확장이 이를 방해할 수 있다고 가정하고 fine-tuned LLaMA의 출력을 조사했다.

조사 결과 위와 같이 여러 언어 토큰으로 구성되어 있지만 의미론적으로 일관성이 있는 응답이 발생하는 code-switching이 관찰되었으며, 이는 연구진의 가설을 뒷받침해 준다.
Conclusions
1% 미만의 추가 사전 훈련 데이터만으로 최첨단 모델과 비슷한 수준의 전이 성능을 달성할 수 있었으며 어휘 확장은 불필요했다.
또한 모델이 자동적으로 언어 간 정렬을 내재화할 수 있다는 의혹이 생김.
'논문 리뷰 > Language Model' 카테고리의 다른 글
| Mistral 7B (0) | 2024.01.11 |
|---|---|
| TinyLlama: An Open-Source Small Language Model (0) | 2024.01.09 |
| DocLLM: A layout-aware generative language model for multimodal document understanding (0) | 2024.01.09 |
| Improving Text Embeddings with Large Language Models (0) | 2024.01.04 |
| LARP: Language-Agent Role Play for Open-World Games (0) | 2024.01.03 |
| TinyGPT-V: Efficient Multimodal Large Language Model via Small Backbones (1) | 2024.01.03 |



