사전 훈련된 LLM을 fine-tuning 하여 text embedding model 얻기
[arXiv](Current version v1)
Abstract
LLM 합성 데이터와 1천 개 미만의 훈련 단계만으로 고품질의 텍스트 임베딩 모델을 얻을 수 있는 방법 소개
Method
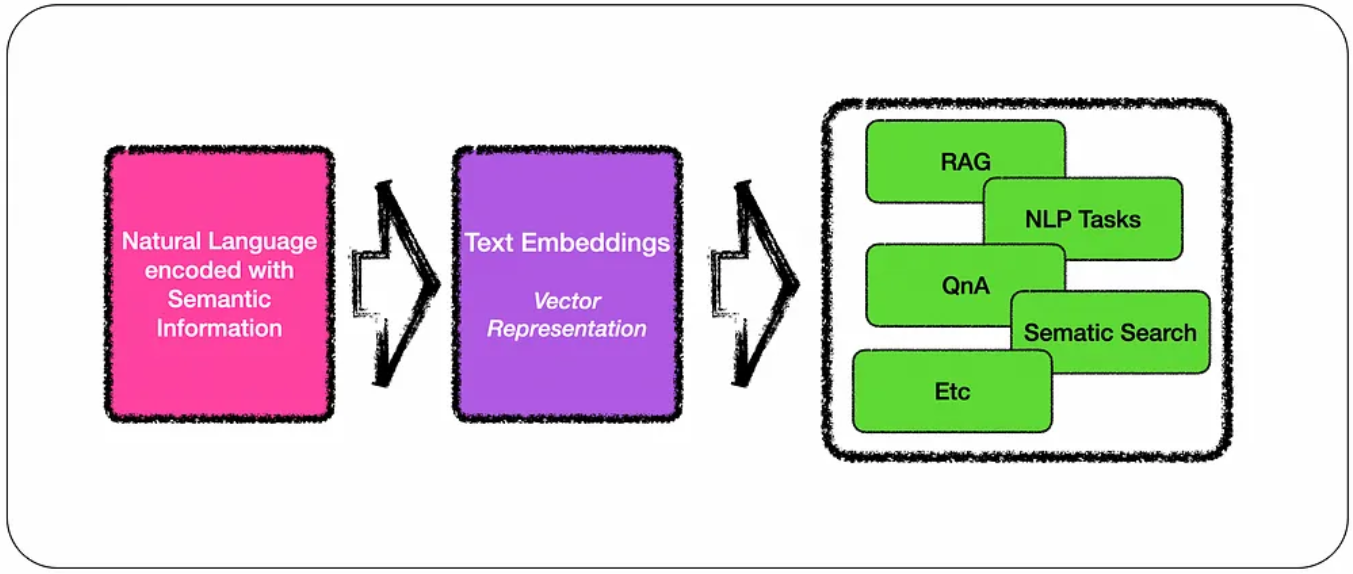
텍스트 임베딩은 다양한 작업에 사용된다.
Synthetic Data Generation
GPT-4와 같은 고급 LLM에서 합성 데이터를 생성하기 위해 임베딩 작업을 여러 그룹으로 분류하고 각 그룹에 서로 다른 프롬프트 템플릿을 적용하는 간단한 분류법 제안.
Asymmetric Tasks
비대칭 작업은 쿼리 검색에서 쿼리와 문서가 의미적으로는 연관이 있지만 동일한 표현을 사용하지 않는 경우를 말한다.
예를 들어, 비대칭 작업의 각 하위 그룹 중 short-long match는 상용 검색 엔진에서 볼 수 있는 시나리오다.
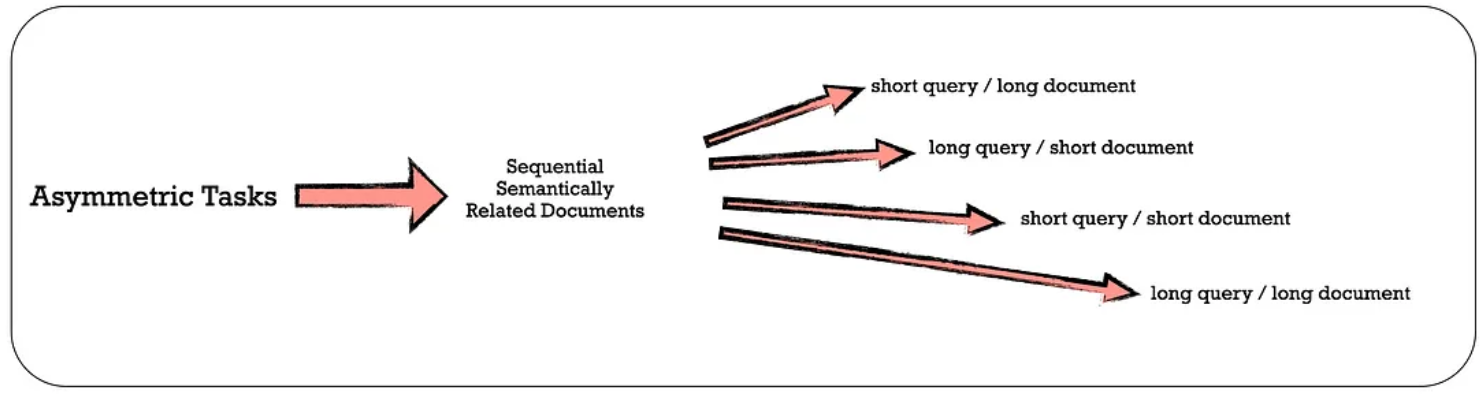
각 하위 그룹에 대해 LLM이 먼저 작업 목록을 브레인스토밍하도록 하고 작업 정의에 따라 구체적인 예제를 생성하는 2단계 프롬프트 템플릿을 설계했다.

Symmetric Tasks
대칭 작업의 경우 semantic textual similarity (STS), bitext retrieval 시나리오를 살펴본다.

작업 정의가 간단하기 때문에 브레인스토밍을 생략하고 각 시나리오에 맞는 프롬프트 템플릿을 설계해 사용한다.
합성 데이터의 다양성을 높이기 위해 위 대화에서 query_length, num_words, language와 같은 무작위 placeholder를 통합했다.
Training
Query-document pair (q+, d+)가 주어지면 명령 템플릿을 적용한다.
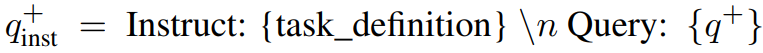
사전 훈련된 LLM이 주어지면 쿼리와 문서의 끝에 [EOS] 토큰을 추가하고 LLM에 공급한 후 마지막 레이어의 [EOS] 토큰을 취함으로써 임베딩 h를 얻는다.
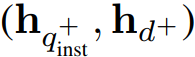
임베딩 모델(사전 훈련된 LLM)을 훈련하기 위해 배치 내의 negative에 대해 대조 학습에서 자주 사용되는 InfoNCE loss를 채택했다.
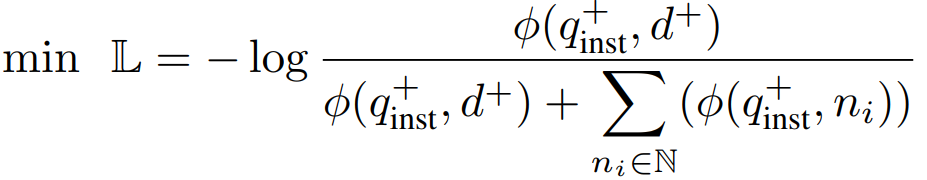
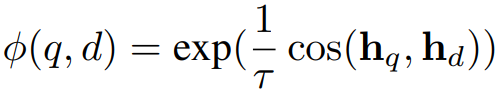
Experiments
Statistics of the Synthetic Data
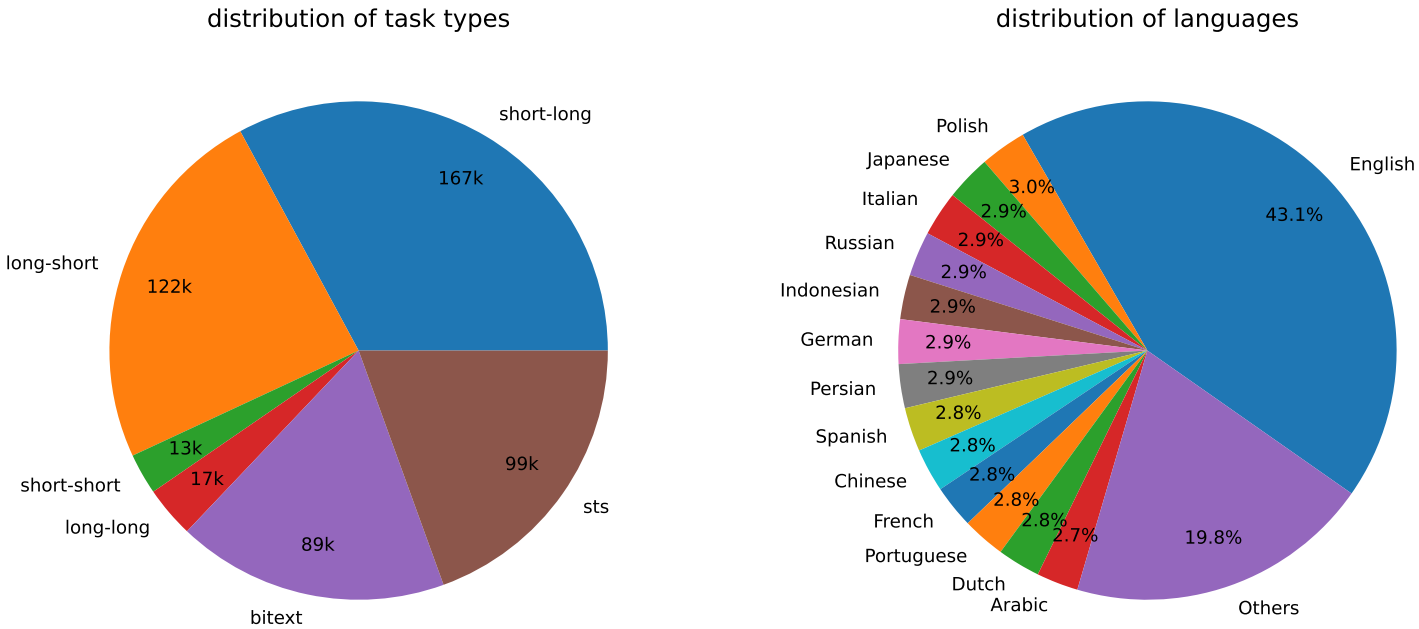
Model Fine-tuning and Evaluation
사전 훈련된 Mistral-7b에 rank 16 LoRA를 추가하여 1 epoch 동안 fine-tuning.
GPU 메모리 효율성: Gradient checkpointing, mixed precision, DeepSpeed ZeRO-3.
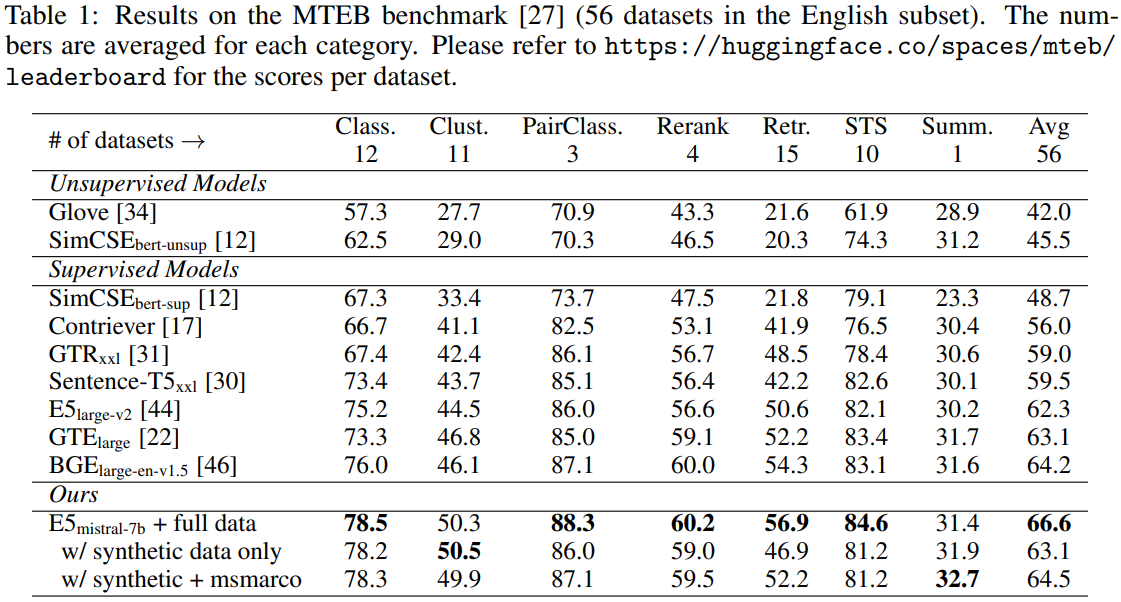
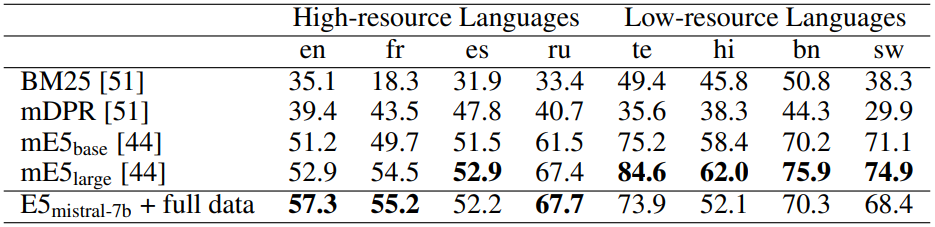
Results
합성 데이터와 기존 데이터를 혼합하여 fine-tuning 하면 더 좋은 성능이 나온다.