[Github]
[arXiv](Current version v6)
Abstract
Energy based models (EBMs)는 일반성과 단순성으로 인해 매력적이지만 훈련하기가 어려웠다. 본 논문에서는 MCMC based EBM training을 확장하는 기법을 소개한다.
Energy-Based Models and Sampling
데이터 포인트 x, 에너지 함수 E(x)는 볼츠만 분포를 통해 확률 분포를 정의한다.
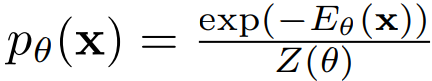

하지만 해당 분포에서는 샘플링이 어려워 MCMC 방법에 의존했다.
샘플링 절차의 혼합 시간을 개선하기 위해 에너지 함수의 gradient를 이용해 샘플링을 수행하는 Langevin dynamics를 사용한다.

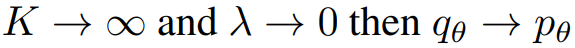
Maximum Likelihood Training
E로 정의된 분포가 데이터 분포 pD를 모델링하기를 원하며, 이는 negative log likelihood를 최소화하는 방식으로 이루어진다.
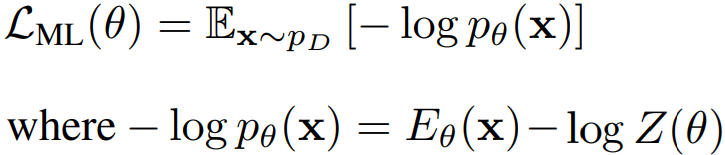
또한 pθ의 근사치인 qθ로부터 음의 샘플 최적화: E와 Langevin dynamics로부터 샘플링된 음의 샘플

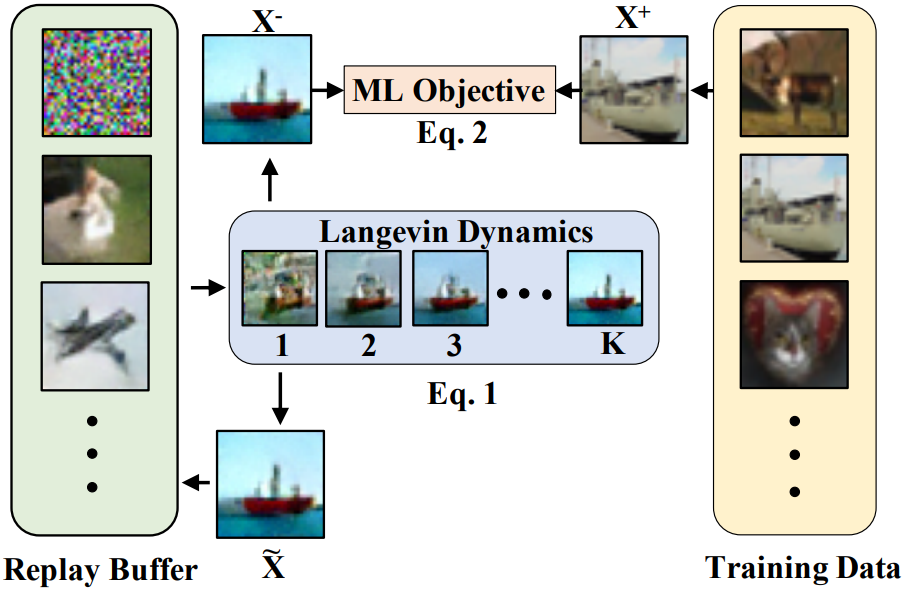
Sample Replay Buffer
Uniform noise 뿐만 아니라 과거에 생성된 샘플을 버퍼 B에 저장하여 초기화로 사용한다.
이렇게 하면 샘플 다양성뿐만 아니라 샘플링 단계 K를 더욱 늘릴 수 있다는 이점이 있다고 함.
Regularization and Algorithm
임의의 에너지 모델은 gradient가 급격히 변화하여 샘플링을 불안정하게 할 수 있다.
네트워크의 Lipschitz constant를 제한하기 위해 모든 레이어에 Spectral Normalization을 추가한다.
또한 양성, 음성 샘플 모두에 대해 에너지 크기를 약하게 L2 정규화한다.

'논문 리뷰 > etc.' 카테고리의 다른 글
| Zero Bubble Pipeline Parallelism (0) | 2024.01.26 |
|---|---|
| Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution (LP-FT) (0) | 2024.01.25 |
| Compositional Visual Generation and Inference with Energy Based Models (0) | 2024.01.02 |
| Coincidence, Categorization, and Consolidation: Learning to Recognize Sounds with Minimal Supervision (0) | 2023.12.15 |
| Look, Listen and Learn (0) | 2023.12.15 |
| Sketch Video Synthesis (0) | 2023.12.10 |



