[Github]
[arXiv](2023/11/30 version v1)
Abstract
역전파 분할, 자동 스케줄링, 동기화 우회를 통해 zero bubble 달성
Introduction
Data parallelism, Tensor parallelism, Pipeline parallelism
Data parallelism : 각 장치에서 각자의 데이터를 처리
Tensor parallelism : 한 레이어의 행렬 연산을 여러 장치로 나누어서 처리
Pipeline parallelism : 모델의 end-to-end를 일정한 stage로 나누고 하나의 stage를 하나의 장치가 처리
Pipeline parallelism(이하 PP)은 bubble이 적을수록 효율적이다.
Pipeline bubble에 대한 연구:
- Gpipe
- PipeDream (1F1B)
- PipeDream-2BW (안 봐도 됨)
역전파는 입력에 x에 대한 gradient B, 가중치 W에 대한 gradient W로 분리할 수 있다.

목차:
- 이상적인 가정에 기반한 handcrafted schedule
- Automatic pipeline scheduling
- Bypassing optimizer synchronizations
- Experiment
- Memory efficient zero bubble schedule
Handcrafted Pipeline Schedules
1F1B

W는 이후에 연관된 연산이 없으므로 같은 stage의 B 이후 언제든지 수행할 수 있다.
F, B, W의 연산 시간이 같다는 이상적인 가정 하의 handcrafted schedule:


각 micro batch 당 하나씩 각 버전의 가중치를 저장해야 하기 때문에 메모리의 제한이 발생한다.
ZB-H1은 1F1B의 메모리 사용량을 초과하지 않는 스케줄, ZB-H2는 메모리가 여유 있는 경우의 스케줄이다.
Automatic pipeline scheduling
하지만 실제로 F, B, W의 연산 시간 TF,B,W가 다르며 stage 간의 통신 시간 또한 발생해 위와 같은 스케줄을 사용할 수는 없다.
따라서 micro batch 수, 메모리 제한, 연산 시간 및 통신 시간을 고려하여 최적의 해결책을 생성하는 알고리즘을 제안한다.
The Heuristic algorithm (자세한 사항은 부록 참고)
- In the warm-up phase: 첫 번째 B 전에 메모리 제한 내에서 최대한 많은 F를 스케줄링
- After the warm-up phase: F와 B를 번갈아 스케줄링하는 패턴을 따르며, TW보다 큰 버블이 발생하거나 메모리 한계에 도달했을 때 W 삽입
- F가 소진되기 전에는 i stage가 항상 i+1 stage보다 많은 F를 스케줄링해야 함
- 남은 F, B가 없는 경우 모든 W를 차례대로 스케줄링
Bypassing optimizer synchronizations
Global gradient norm clipping, NAN 및 INF에 대한 global check 등을 위해 AllReduce global state를 계산해야 하며, PP에서 이는 보통 최적화 단계에서 동시에 수행된다.


하지만 연구진은 gradient clipping, NAN, INF 문제가 대부분의 경우에서 일어나지 않기 때문에 사전 동기화 대신 업데이트 후 검증으로 대체했다.

최적화 단계에서 local device i는 이전 i-1 stage로부터 수신한 부분적인 global state와 local state를 결합하여 최적화를 수행하며 문제가 발생할 경우 업데이트를 생략한다.
이후 다음 반복의 warm-up phase 동안에 global state에 대한 검증을 수행하고 생략되었거나 수정이 필요한 경우 롤백한 뒤 global state를 기반으로 최적화를 다시 수행한다.
Experiment
ZB-1p : 1F1B와 동일한 메모리 제한을 가진 automatic schedule
ZB-2p : 1F1B의 두 배의 메모리 제한
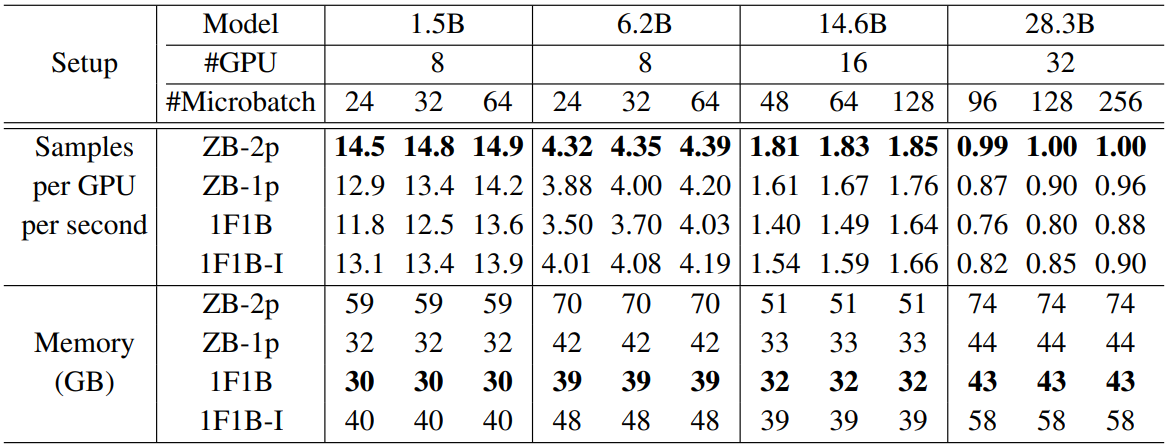

Memory efficient zero bubble schedule
1F1B와 동일한 메모리 제한을 가지면서 최소한의 bubble을 가지는 ZB-V 제안

16 layers transformer의 경우 1-stage(1~4 layers), 2-stage(5~8) 이런 형태였다면, stage를 2개의 청크로 나누어 1-stage(1~2, 15~16), 2-stage(3~4, 13~14) 형태로 바꾼다.
Micro batch 1이 device 1에서 출발하여 다시 device 1로 돌아올 때 한 번의 순전파가 끝나는 것이다.
- Device 1은 순전파가 돌아오자마자 바로 역전파를 수행할 수 있으므로(15~16 layer를 갖고 있기 때문에) 메모리를 빠르게 정리하여 낮은 메모리 제한에서 zero bubble을 달성할 수 있다.
- 모든 device의 메모리 사용량이 균형을 이룬다. 이전 방법은 낮은 레이어를 가진 device일수록 더 많은 메모리가 필요했다.
Evaluation
같은 메모리 제한에서 비교

ZB-2p*은 일관된 global batch 크기를 유지하도록 micro batch 크기 b/2, 수 2m으로 조정했다는 표시.
Micro batch 크기가 극단적으로 작을 때 ZB-V가 좋긴 한데 솔직히 큰 차이는 없어 보인다.
메모리 제한이 낮을수록 bubble 비율이 확실히 낮긴 함.

'논문 리뷰 > etc.' 카테고리의 다른 글
| Mixtures of Experts Unlock Parameter Scaling for Deep RL (0) | 2024.02.23 |
|---|---|
| YOLO-World: Real-Time Open-Vocabulary Object Detection (3) | 2024.02.07 |
| TOOD: Task-aligned One-stage Object Detection (0) | 2024.02.07 |
| Fine-Tuning can Distort Pretrained Features and Underperform Out-of-Distribution (LP-FT) (0) | 2024.01.25 |
| Compositional Visual Generation and Inference with Energy Based Models (0) | 2024.01.02 |
| Implicit Generation and Modeling with Energy-Based Models (0) | 2024.01.02 |



