[Github]
[arXiv](Current version v1)

Abstract
비디오에서 애니메이션 scalable vector graphics(SVG) 생성
Introduction
Neural Layered Atlas(NLA)와 미분 가능한 rasterizer 사용.
SVG 형식의 스케치 비디오 생성을 위해 새로운 control point 초기화 방법과 temporal consistency loss 제안.
Methods

Preliminary: Video Decomposition via Layer Atlas
Differentiable Optimization for Video Sketch
T frame의 실제 비디오 IT, N개의 stroke set SN으로 구성된 스케치 비디오 ST.
또한 하나의 stroke는 4개의 control point를 통해 구축된다.

미분 가능한 rasterizer R을 통해 스케치 비디오를 SVG로 변환하고 손실을 계산한다.
(X, Y는 control point의 좌표 집합)

Strokes Initialization
CLIPasso의 saliency 기반 초기화 방법으로 각 프레임에서 N개의 point를 샘플링하고 모든 프레임의 N*T point set에서 N개의 point를 다시 샘플링한다(pn = (xn, yn, tn)). 해당 points의 위치를 모든 프레임에 전파한다. (p̂nt = (xn, yn, t))

Position Warmup
Atlas UV map에서 전파된 point를 sampling point와 동일한 지점으로 매핑되도록 최적화하는 warmup 단계.
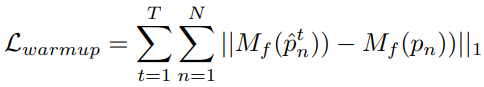
Curve Width Initialization
각 프레임에서 같은 point 쌍 간의 거리를 측정하여 물체가 가까울수록 선을 더 굵게 한다.

Curves Optimization
초기화 후 CLIPasso와 똑같이 CLIP의 중간 활성화들에서 차이를 측정하여 point의 위치를 최적화한다.

ResNet 기반 CLIP 모델을 기본으로 사용.

같은 sampling index n을 가지는 각 프레임의 points가 최적화 도중에도 계속 UV map의 같은 지점에 매핑되도록 하는 일관성 손실 추가:

Total loss:
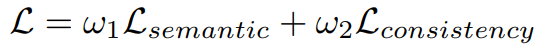
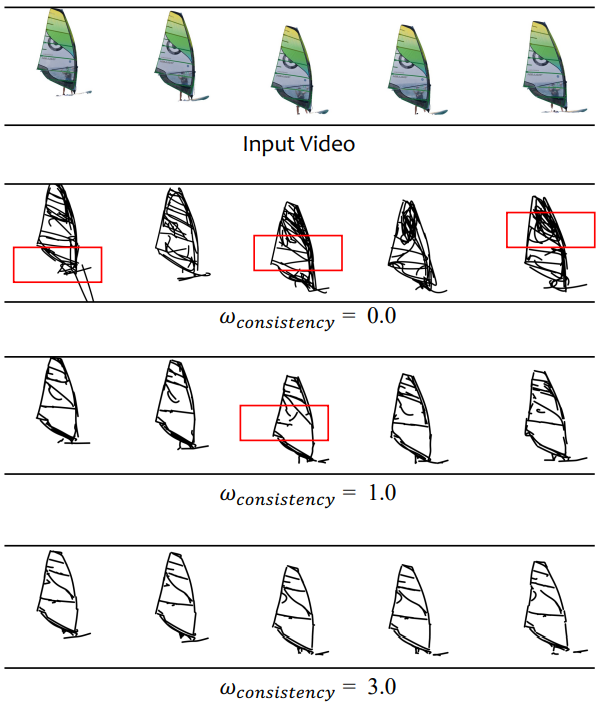
Experiments

'논문 리뷰 > etc.' 카테고리의 다른 글
| Implicit Generation and Modeling with Energy-Based Models (0) | 2024.01.02 |
|---|---|
| Coincidence, Categorization, and Consolidation: Learning to Recognize Sounds with Minimal Supervision (0) | 2023.12.15 |
| Look, Listen and Learn (0) | 2023.12.15 |
| Layered Neural Atlases for Consistent Video Editing (2) | 2023.12.07 |
| CLIPasso: Semantically-Aware Object Sketching (3) | 2023.12.05 |
| Fast Feedforward Networks (FFF) (2) | 2023.11.27 |



