[Github]
[arXiv](Current version v1)

Abstract
사용자가 원하는 level로 무엇이든 분할하고 인식할 수 있는 범용 이미지 분할 모델인 Semantic-SAM 소개.
이를 달성하기 위한 다중 선택 학습 방식은 다양한 segmentation dataset에 대해 공동으로 훈련하려는 최초의 시도이다.
Introduction
범용 이미지 분할 모델의 주요 장애물:
- Model Architecture: 단일 입력 - 단일 출력 파이프라인
- Training Data: 의미 인식, 세분성(granularity) 인식을 모두 갖춘 데이터셋이 없음
Semantic-SAM에서는 한 번의 클릭으로 여러 세분성을 예측.

이러한 기능은 다중 선택 학습 설계(multi-choice learning design)를 통해 달성됨.
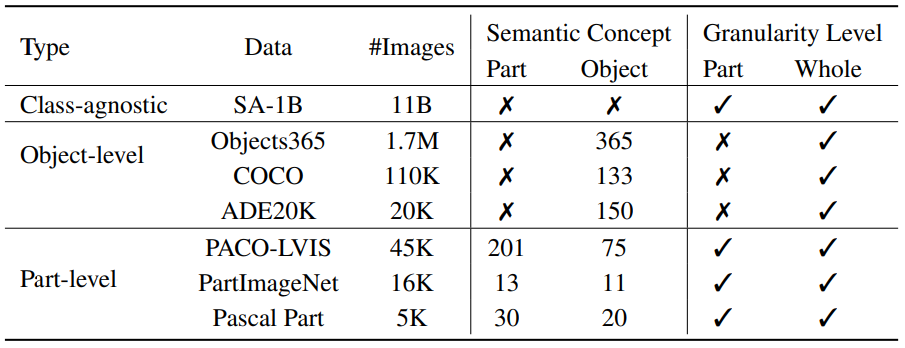
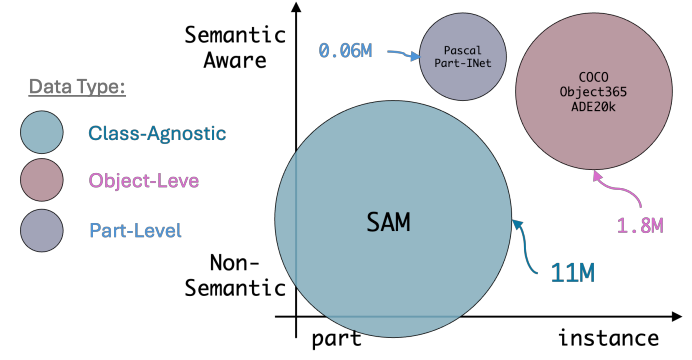
다양한 세분성에 대한 7개의 데이터셋 통합.
SAM보다 세분화 능력 우수.
Data Unification: Semantics and Granularity
Semantic-SAM
Model
Semantic-SAM은 Mask DINO의 쿼리 기반 마스크 디코더를 활용하고,
SAM과 유사하게 sparse(points, boxes, text), dense(mask) prompt를 지원한다.
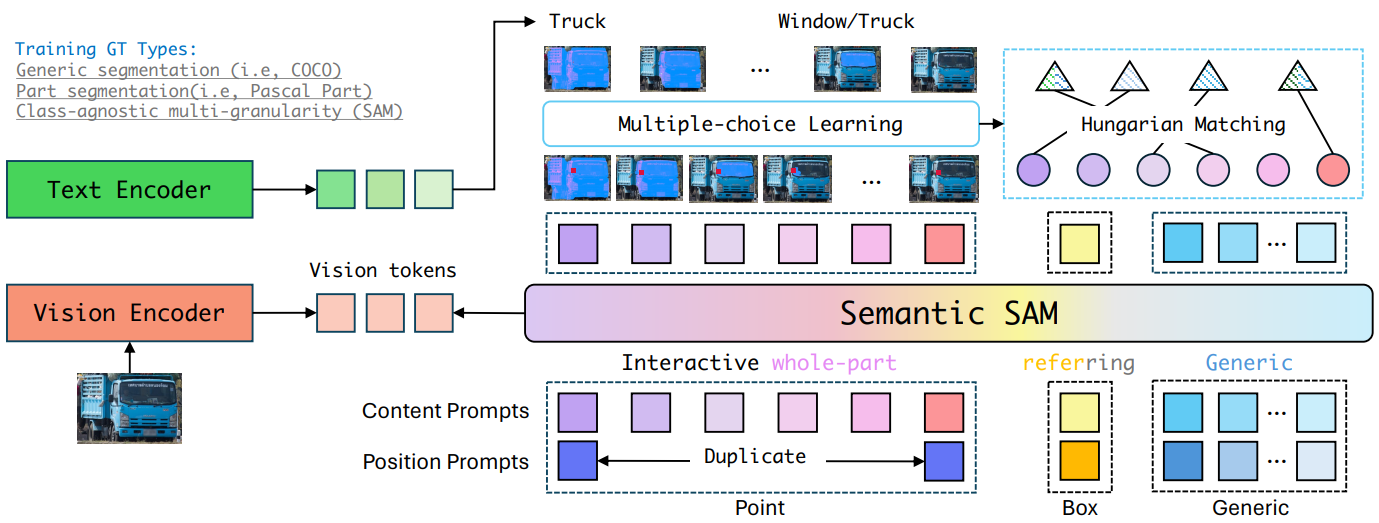
클릭을 매우 작은 앵커 상자(x,y,h,w)로 변환.
클릭&상자는 K 콘텐츠 임베딩과 위치 임베딩으로 인코딩 됨.
K는 각 segmentation level을 가리키며, 쿼리 벡터 세트를 다음과 같이 나타냄.

Deformable decoder에 쿼리, 참조 상자, 인코딩 된 feature를 입력하여 각 segment level에 대해 category, mask를 예측함.
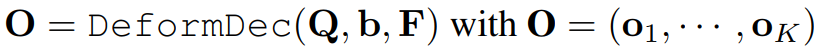
Training
Recognize Anything
의미론적 주석의 불일치와 서로 다른 세분성의 더 나은 의미 전달(e.g. 머리와 같은 부품 개념이 여러 개체에서 공유됨)을 위해 객체 인식과 부분 인식을 별도로 수행한다.
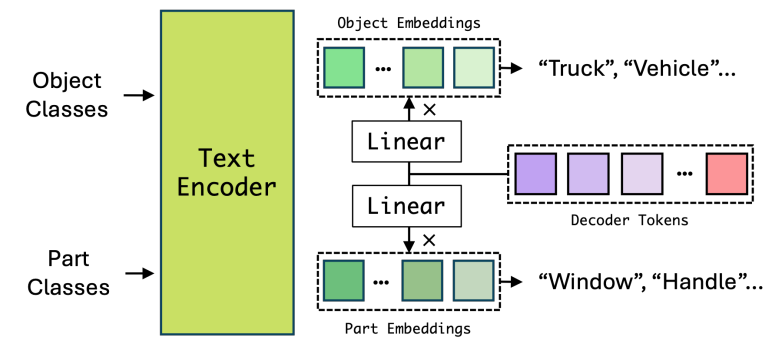
중요한 점은 모든 유형의 분할 데이터가 통합된 형식을 공유하지만 손실은 데이터 유형에 따라 다르다는 것이다.
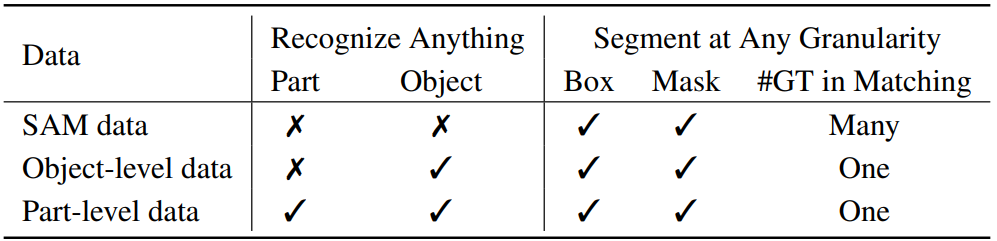
Segment at any granularity
SAM은 3개의 예측 마스크를 출력하지만 각 클릭에 대해 하나의 GT로만 훈련하는 다대일 매칭을 사용한다.
Semantic-SAM에서는 동일한 클릭을 공유하는 GT mask를 클러스터링 하여 각 클릭에 대해 여러 개의 GT mask로 훈련하는 다대다 매칭을 사용한다.
상자 예측 및 일반 분할(개체 수준)의 경우 Mask DINO의 파이프라인을 따르며 유일한 차이점은 denoising training에서 GT label 대신 학습 가능한 토큰을 사용한다는 것이다.
Experiments
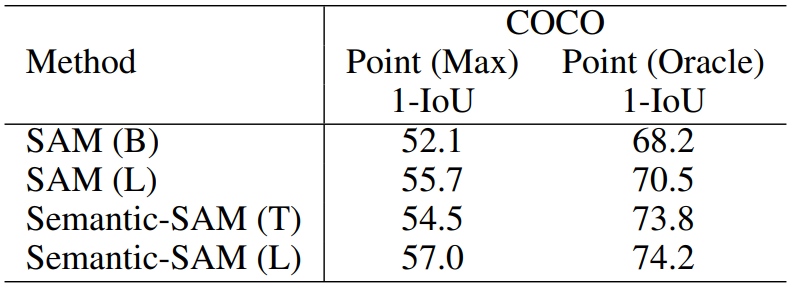
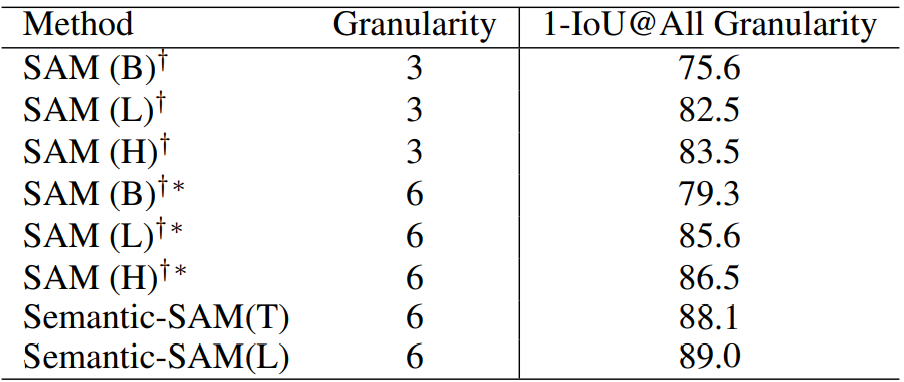
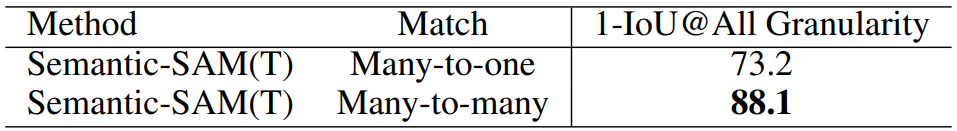



'논문 리뷰 > Vision Transformer' 카테고리의 다른 글
| EVA-CLIP: Improved Training Techniques for CLIP at Scale (0) | 2023.10.19 |
|---|---|
| EVA-02: A Visual Representation for Neon Genesis (1) | 2023.10.19 |
| EVA: Exploring the Limits of Masked Visual Representation Learning at Scale (1) | 2023.10.18 |
| ProPainter: Improving Propagation and Transformer for Video Inpainting (3) | 2023.10.12 |
| Flow-Guided Transformer for Video Inpainting (FGT) (0) | 2023.10.12 |
| FuseFormer: Fusing Fine-Grained Information in Transformers for Video Inpainting (0) | 2023.10.10 |



