Text2img 확산 모델에서 object 위치, 포즈 지정하기
GLIGEN:Open-Set Grounded Text-to-Image Generation.
Large-scale text-to-image diffusion models have made amazing advances. However, the status quo is to use text input alone, which can impede controllability. In this work, we propose GLIGEN, Grounded-Language-to-Image Generation, a novel approach that build
gligen.github.io

Abstract
Grounding input에도 조건화될 수 있도록 text-to-image 모델의 기능을 구축하고 확장하는 새로운 접근 방식인 GLIGEN( Ground-Language-to-Image Generation)을 제안.
기존 모델의 가중치를 동결하고 gate mechanism을 통해 새로운 학습 가능한 레이어에 grounding information을 주입함.
Introduction

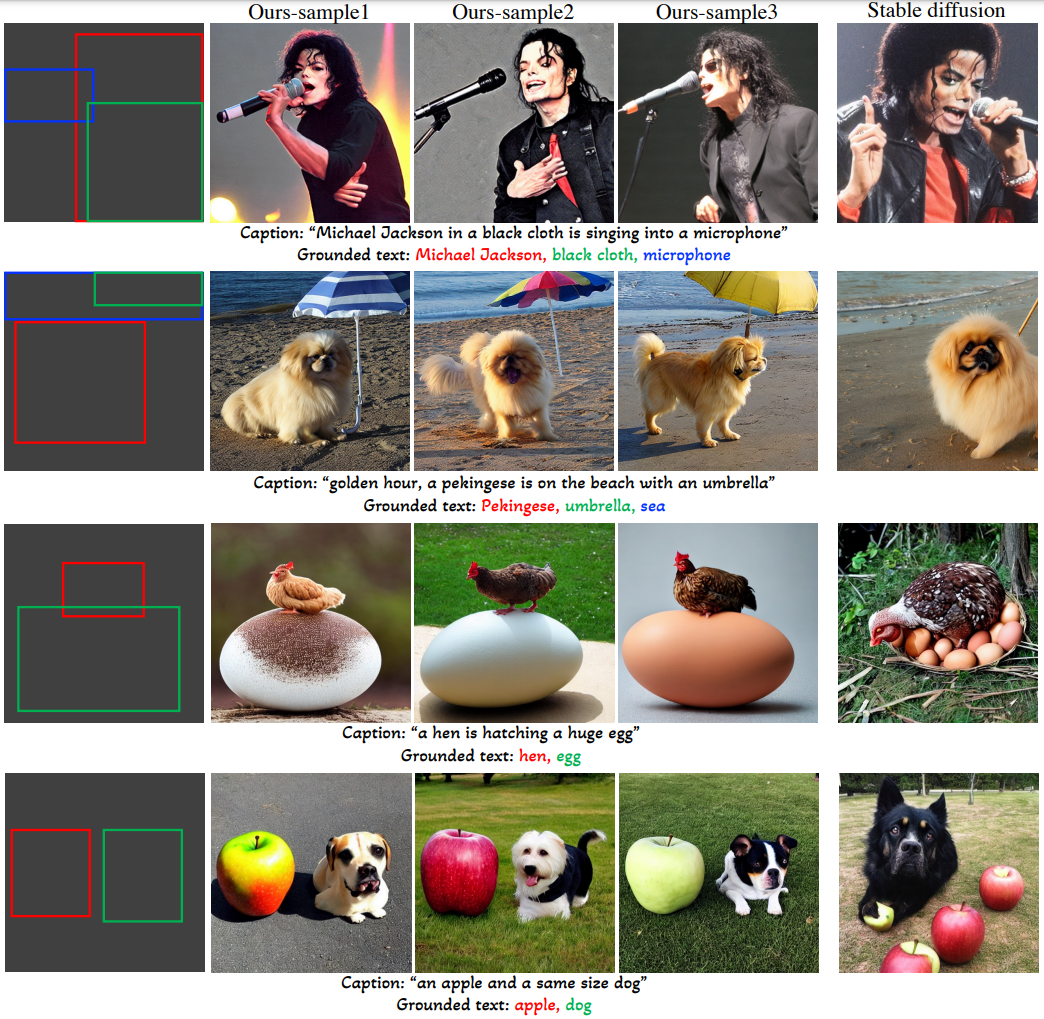
위 그림과 같이 텍스트만으로 물체의 위치를 설명하는 것은 어렵지만 bounding box, key point는 쉽게 할 수 있다.
원래 모델 가중치를 동결하고 grounding input을 받는 새로운 gate transformer layer를 추가한다.
또한 샘플링 과정에서 사전 훈련 모델과 새로운 tranformer 계층을 적절히 융합하여 품질과 제어성의 유연한 조절 가능.
Open-world 어휘 개념을 grounding 할 수 있도록 사전 훈련된 텍스트 인코더로 각 entity와 구문을 인코딩하고 위치 정보와 함께 transformer 계층에 공급한다.
GLIP에 따라 훈련에서 object detection과 grounding data format을 통합.
Contribution
- Grounded text-to-image 생성
- 기존 가중치를 보존하고 새로운 계층을 점진적으로 통합하는 방법을 학습함으로써, 훈련에서 관찰되지 않은 새로운 localized concept의 합성을 달성
- layout2img 작업에 대한 제로샷 성능은 이전의 SOTA를 크게 능가
Preliminaries on Latent Diffusion Models
Open-set Grounded Image Generation
Grounding Instruction Input
Grounding spatial : bounding box, key point
Grounding entity : image, text + grounding spatial
모델에 대한 guidance를 다음으로 정의 (grounding = 주로 text + bounding box 조합)
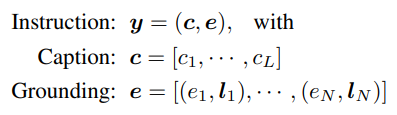

Caption Tokens
Text encoder로 caption feature sequence 얻음

Grounding Tokens
bbox embedding + text feature로 grounding token 얻음

From Closed-set to Open-set
기존 layout-to-image 작업은 entity의 vector embedding이나 codebook을 학습하는데 이런 closed-set은 두 가지 단점이 있다.
- 일반화 기능 부족
- 조건에 단어, 구절이 사용되지 않아 의미 구조가 누락되어 있음
반면에 GLIGEN은 open-world pretrained text encoder를 사용하여 일반화 성능 좋음.
Training Data
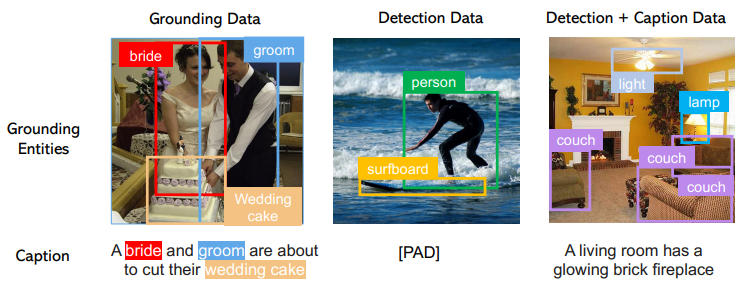
훈련에서는 세 가지 데이터를 유연하게 입력으로 받을 수 있다.
Detection data의 경우 caption을 null로 하여 사용한다. 탐지 데이터는 매우 많기 때문에(수백만) 크게 도움이 된다.
Extensions to Other Grounding Conditions
Text + bounding box 조합뿐만 아니라 다양한 조건을 연구한다.
- 예제 이미지의 경우 image encoder 사용
- Key point의 경우 각 키포인트를 fourier embedding

Continual Learning for Grounded Generation
Gated Self-Attention
원래 확산 모델의 visual feature token을 v라고 할 때 LDM의 attention :
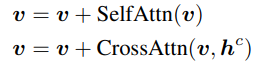
Gated self attention layer 추가 :


TS() = 다음 계층에 visual token만 넘기도록 하는 token selection
γ = a learnable scalar. 0으로 초기화.
β = 제어 가능성을 위해 추론 중에 스케줄에 따라 변경됨
Learning Procedure
모든 새로운 parameter θ', grounding input y에 대해 :

A Versatile User Interface
모델이 잘 학습된 뒤에는 사용자 마음대로 caption에 존재하는 단어를 grounding 하거나, caption에 언급하지 않고도 자유롭게 object를 추가할 수 있다.
Scheduled Sampling in Inference
가끔 text-to-image에 비해 낮은 품질의 이미지를 생성하는데, 생성과 grounding 사이의 균형을 위해 β값을 조절

후반 단계에만 grounding input이 반영되므로 시각적 품질이 향상되고 다른 도메인으로 쉽게 확장이 가능.

Experiments