
Abstract
실용적인 사용을 위해 더 나은 일반화, 제어 가능성 및 효율성에 초점을 맞춘 portrait animation framework인 LivePortrait 제안
[Github]
[arXiv](2024/07/03 version v1)
Methodology
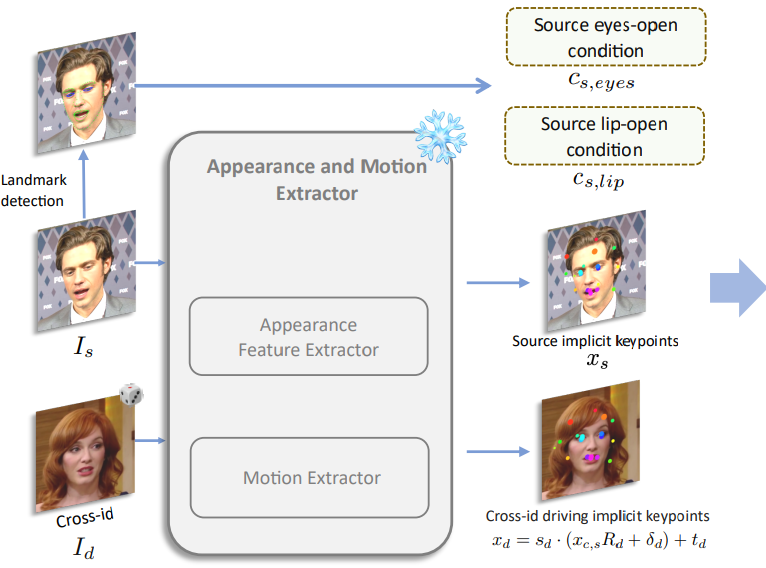
Preliminary of Face Vid2vid
Appearance feature extractor F,
canonical implicit keypoint detector L,
head pose estimation network H,
expression deformation estimation network ∆,
warping field estimator W, generator G로 구성되며, 추출된 정보들을 통해 각 이미지의 암시적 3D 키포인트를 생성한 다음
W로 warping field를 생성하고 이를 이용해 최종 이미지를 생성한다.
Stage I: Base Model Training
Face-vid2vid를 기반으로 기본 모델을 훈련하는 단계.
High quality data curation
얼굴 추적 및 인식, 필터링을 활용하여 19K ID와 60K 정적 스타일 초상화로부터 69M 비디오 프레임의 훈련 데이터셋 생성.
Mixed image and video training
현실적인 초상화 비디오로만 훈련된 모델은 애니메이션 같은 스타일 초상화에는 성능이 떨어진다. 스타일 초상화 비디오는 드물어서 100개 미만의 ID로부터 1300개 정도의 클립만 수집할 수 있었다. 반면에 스타일 초상화 이미지는 많기 때문에 60K 개를 수집했으며, 단일 이미지를 1 프레임 비디오로 간주하여 이미지와 비디오를 공동훈련함으로써 일반화 능력을 향상시켰다.
Upgraded network architecture
- L, H, ∆를 ConvNeXt-V2-Tiny를 백본으로 하는 단일 모델 M으로 통합
- Face-vid2vid의 원래 디코더보다 강력한 SPADE 디코더를 생성기 G로 채택
- 효율성을 위해 G의 마지막 레이어로 PixelShuffle 레이어를 삽입하여 512×512로 업샘플링
Scalable motion transformation
Face-vid2vid의 3D 키포인트 변환은 스케일 요소를 무시하며, 결국 스케일링이 표정 변형에 포함되어 훈련 난이도가 올라간다.
따라서 키포인트 변환에 스케일 요소를 추가. (오른쪽)
|
|
Landmark-guided implicit keypoints optimization
Face-vid2vid는 눈 움직임 같은 미세한 표정을 포착하기 어렵다. 따라서 얼굴 랜드마크를 도입하고 눈과 입에서 N개의 랜드마크를 가져와 랜드마크 기반 손실을 최적화한다.
Cascaded loss terms
전체 모델 훈련.
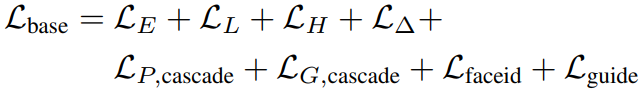
Cascade는 지각 손실, GAN 손실에만 적용되며 global과 local에서 각각 손실을 계산하는 것을 의미한다.
Lcascade는 Lglobal, Lface, Llip으로 구성된다.
Stage II: Stitching and Retargeting
MLP를 통해 다른 ID의 driving keypoint를 source ID의 driving keypoint로 변환하는 작업이다.
Stitching module은 몸과 얼굴이 연결되는 '어깨 영역'의 불일치를 해소하고 eyes retargeting module은 눈 크기 차이가 클 때 눈 감김 문제를 해결한다. Lip retargeting module도 비슷한 역할을 한다.
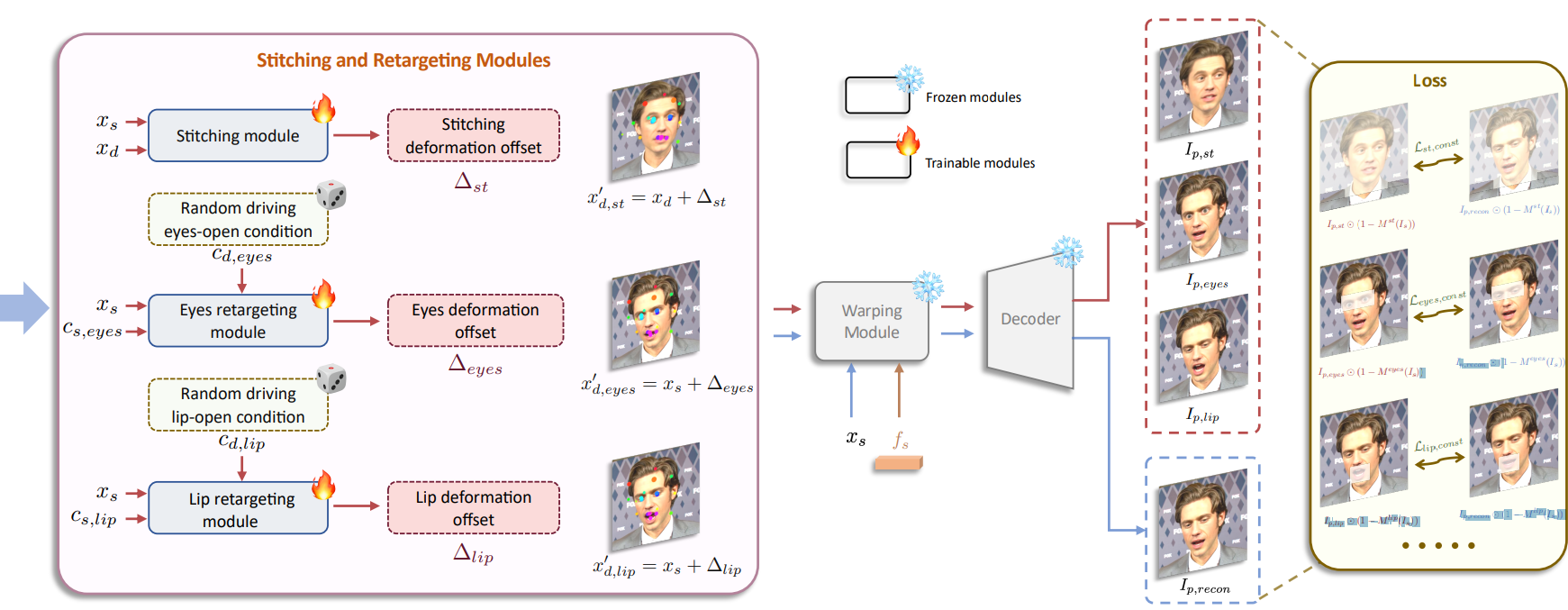
Stitching module
S는 driving keypoint를 업데이트한다.
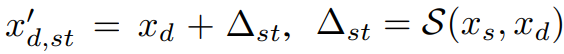
손실 계산:
마스크 M으로 어깨 영역을 제외한 나머지 부분을 마스킹하고 예측 이미지 Ip,st = D(W(fs; xs, x'd,st))와 자기 재구성 이미지 Ip,recon = D(W(fs; xs, xs)) 간의 차이를 최소화하도록 한다. 뒷항은 정규화항.
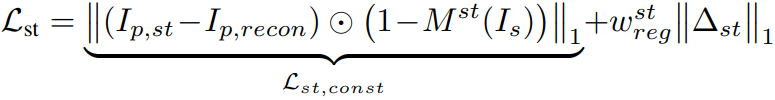
Eyes and lip retargeting module
Stitching module과 비슷하게 작동하며 눈과 입의 열린 정도 c를 추가로 입력받는다.

Inference
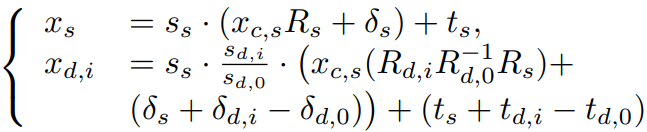

Experiments
Efficient Portrait Animation with Stitching and Retargeting Control
Comparisons with existing methods Self-reenactment The results of our first-stage base model, without applying the stitching and retargeting modules, are presented here. Cross-reenactment The results of our first-stage base model are presented in Ours w/o
liveportrait.github.io
'논문 리뷰 > etc.' 카테고리의 다른 글
| End-to-end Algorithm Synthesis with Recurrent Networks: Logical Extrapolation Without Overthinking (DeepThinking Systems) (0) | 2024.05.29 |
|---|---|
| Diffusion for World Modeling: Visual Details Matter in Atari (DIAMOND) (0) | 2024.05.28 |
| Your Transformer is Secretly Linear (1) | 2024.05.26 |
| The Platonic Representation Hypothesis (1) | 2024.05.22 |
| Is Flash Attention Stable? (0) | 2024.05.13 |
| Dynamic Typography: Bringing Text to Life via Video Diffusion Prior (0) | 2024.04.22 |



