[Github]
[arXiv](2024/01/17 version v1)
Abstract
최근 몇몇 상업용 비디오 모델은 대규모의 잘 필터링된 고품질 비디오에 의존한다. 또한 저품질 WebVid-10M에서 모델을 훈련하는 많은 연구들은 고품질 비디오를 생성하기 어렵다. 본문에서는 저화질 비디오와 합성된 고품질 이미지를 활용하여 고품질 비디오를 생성할 수 있는 방법을 모색한다.
논문 한 줄 요약 : 고품질 비디오 데이터가 없을 때 저품질 비디오로 훈련된 T2V 모델에서 고품질 이미지를 통해 공간 모듈만 fine-tuning 하는 것이 가장 성능이 좋다.
Method
- Spatial-temporal Connection Analyses
- Data-level Disentanglement of Appearance and Motion
Spatial-temporal Connection Analyses
Base T2V model
VideoCrafter1 + ModelScopeT2V의 temporal convolution 추가

Parameter Perturbation for Full and Partial Training
동일한 아키텍처에 두 가지 훈련 전략을 사용한다.
400만 개의 Midjornery 이미지와 LoRA를 통해 완전히 훈련된 모델 MF, 부분 훈련된 모델 MP를 섭동한다.


결과:
- 모션 품질은 F-Spa-LoRA가 더 좋았다.
- 화질이나 심미적 점수는 P-Spa-LoRA가 더 좋았으며 워터마크도 제거되었다.

시간 섭동에서도 같은 결과가 나왔다. 품질은 P-Temp-LoRA가 더 좋았으며 모션은 F-Temp-LoRA가 더 좋았다.

결과를 종합하면 완전히 훈련된 모델의 시공간 결합이 모션을 유지하는 데에 도움이 되었지만, 공간적으로 더 좋게 fine-tuning 되는 것을 저해한다.
Data-level Disentanglement of Appearance and Motion
다음 4가지 비교군이 있다.
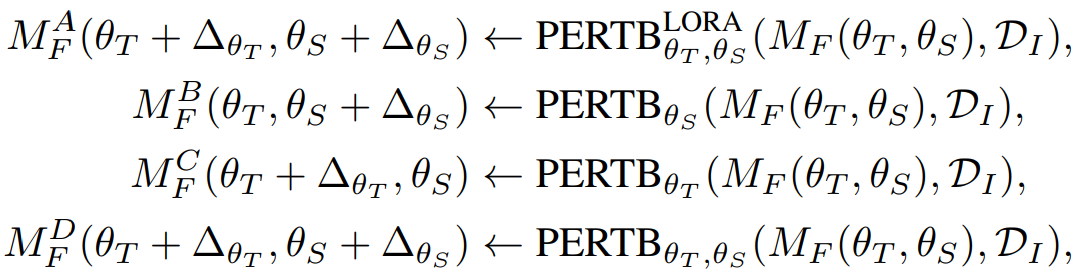
시공간 품질을 고려했을 때 MFB와 MFD가 품질이 가장 좋았으며 모션은 둘 중에 MFB가 더 좋았다.

저화질 비디오로 훈련된 모델의 공간 레이어를 고품질 이미지로 fine-tuning 하는 것이 가장 좋은 해결책임을 도출할 수 있다.
Experiments
VideoCrafter2
VideoCrafter2: Overcoming Data Limitations for High-Quality Video Diffusion Models.
ailab-cvc.github.io



