Prompt tuning과 증류를 통해 핸드폰에서도 빠르게 실행할 수 있는 SAM의 가속 변형.
[Github]
[arXiv](Current version v1)

Abstract
Edge device에서의 효율적인 실행을 위한 SAM의 가속 변형인 EdgeSAM 제안.
SAM에 비해 40배 빠르고 iPhone 14에서 30 FPS로 실행될 수 있다.
EdgeSAM
- Segment Anything (SAM)
- Encoder distillation
- Prompt-in-theloop distillation
- Lightweight module that embeds the granularity preferences

Encoder-Only Knowledge Distillation
SAM 인코더 T와 효율적인 인코더 S와의 픽셀 증류 손실:

하지만 증류 손실은 뚜렷한 개선을 보여주지 못했고 증류 중 prompt를 고려할 것을 추가로 제안한다.
Prompt-In-the-Loop Knowledge Distillation
디코더는 전체 피라미터의 0.6%만 차지할 정도로 가볍기 때문에 아키텍처는 유지하고 feature map, prompt, mask token, IoU token에 대해 다음과 같은 손실을 계산한다.

ϕ는 일정 confident 이상의 마스크만 유지하는 임계값이고 다양한 손실 구성을 비교한 결과 Dice loss와 BCE loss로 구성된 마스크 손실만 쓰는 것이 가장 좋았다.

훈련에서 사용되는 프롬프트는 신중하게 설계되어야 한다.
- 디코더의 fine-tuning이 일반화 능력에 위협이 된다. (Point로 fine-tuning 시 box 성능이 저하됨.)
- LoRA는 성능 상한을 제한한다.
- 원래 SAM에서도 모호한 prompt에 대해 부정확한 마스크를 생성한다.

증류의 효율을 높이기 위해서 dynamic prompt sampling 도입.
- 초기 prompt에서 다양한 prompt 조합을 동적으로 생성
- 학생 모델이 부정확성을 보이는 영역을 식별하고 학생 모델의 초점을 그러한 segment로 향하게 함
- 교사 모델이 보다 고품질의 마스크를 생성하도록 강요
Interactive segmentation의 최근 발전에서 영감을 얻어 Prompt-In-the-Loop Knowledge Distillation 제안
 |
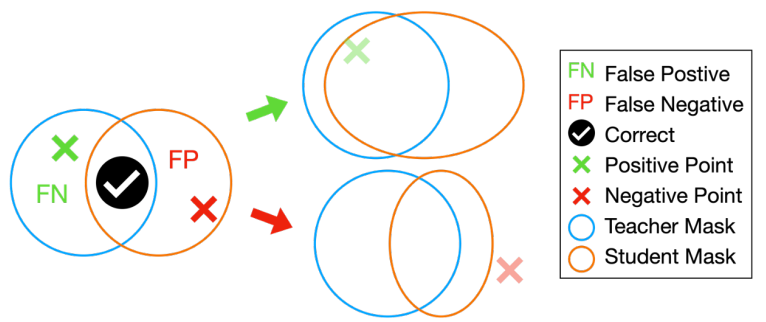 |
알고리즘을 간단하다. 우선 교사 모델과 학생 모델에서 마스크를 생성한 뒤, false positive 또는 false negative에 해당하는 prompt를 샘플링하고 기존 prompt에 추가하여 학생 모델이 해당 영역에 집중하도록 한다.
각 prompt에 대해 여러 세분성의 4개의 마스크가 예측된다는 점 유의.
Granularity Priors
SAM 논문에서 제안된 SA-1B 데이터셋은 자동으로 수집된 데이터이기 때문에 인간 주석과 다를 수 있으며 모호한 prompt에서 세분성을 결정하기가 어렵다.
한편 SAM은 box prompt에서 대상 세분성을 훨씬 쉽게 파악할 수 있다.
이미지 인코더 위에 feature pyramid network와 공유 탐지 헤드로 구성된 lightweight region proposal network를 구축하여 추론 중에 부여된 point prompt에 대해 가까운 K-box를 제안하고 prompt에 결합한다.

Training and Application
Training Pipeline
- Encoder-Only Knowledge Distillation
- Prompt-In-the-Loop Knowledge Distillation
- Lightweight region proposal network-Only
Experiments

Ablation




