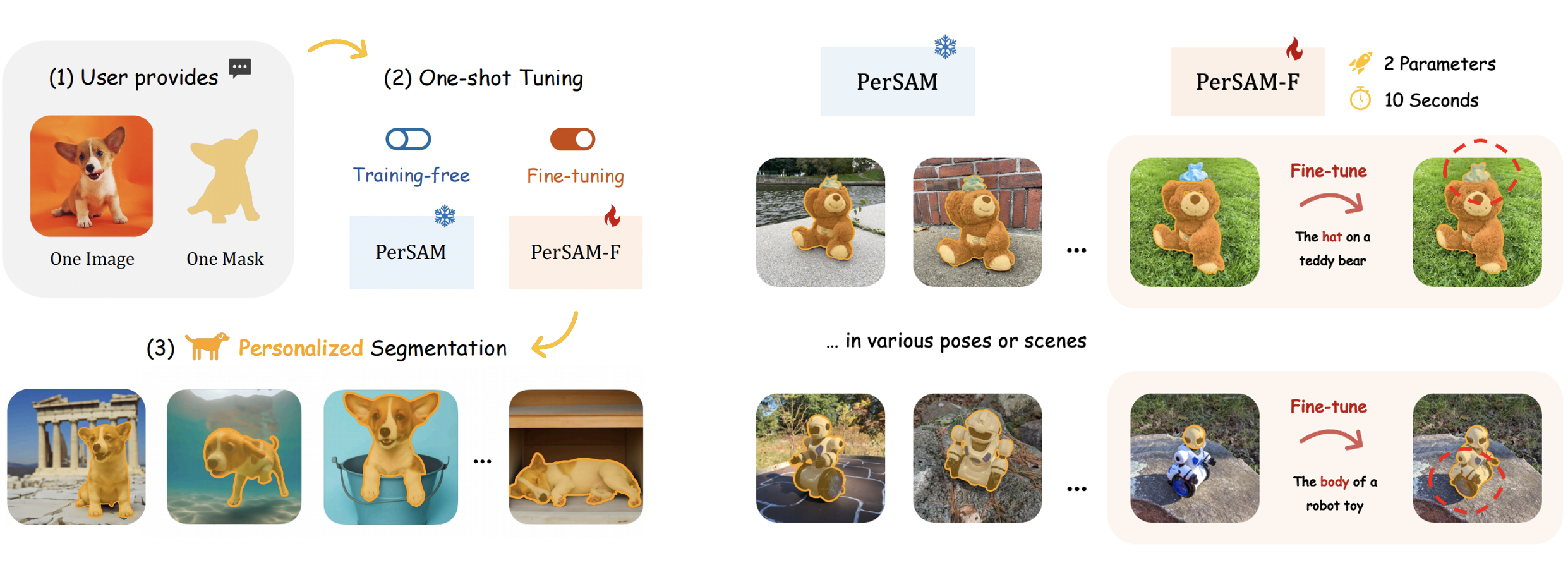
SAM(Segment Anything Model) 개인화&자동화
Abstract
SAM(Segment Anything Model)을 위한 개인화 접근 방식인 PerSAM 제안.
또한 학습 가능한 가중치를 도입하여 더욱 효율적인 변형인 PerSAM-F 제안.
제안한 방법으로 Stable Diffusion 또한 개인화 가능.
Introduction
SAM은 클릭과 같은 사용자 입력이 있어야 한다.
PerSAM은 내 앨범에서 강아지 사진을 찾는 작업과 같이 자동으로 특정 개체를 탐지하고 분할할 수 있을까? 에서 시작한다.
원샷 데이터만을 사용하여 SAM을 효율적으로 사용자 정의
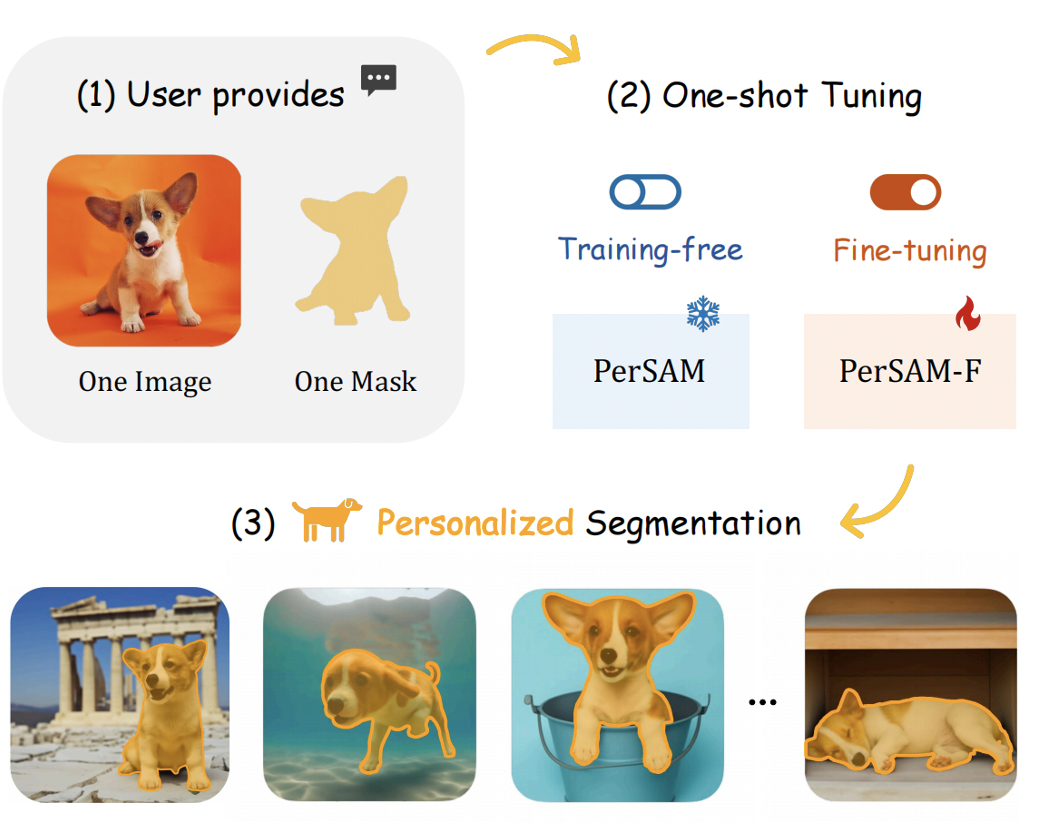
먼저 SAM을 통해 참조 이미지의 대상 개체의 임베딩을 인코딩한 뒤 테스트 이미지에서 개체와 모든 픽셀 간의 feature 유사성을 계산하여 SAM의 긍정-부정 point를 선택한다.
- Target-guided Attention : 계산된 feature 유사성으로 SAM 디코더의 cross attention 계층 안내
- Target-semantic Prompting : low-level prompt token을 대상 개체에 융합하여 디코더에 충분한 시각 정보 전달
- Cascaded Post-refinement : 보다 미세한 segmentation를 위해 two-step post-refinement strategy 채택
또한 다음과 같이 곰의 모자, 캔 윗부분과 같은 모호한 문제는 PerSAM-F에서 오직 2개의 피라미터만 finetuning하여 적절한 segmentation 결과를 생성 가능

본 논문의 기여:
- Personalized Segmentation Task
- Efficient Adaption of SAM
- Personalization Evaluation : 새로운 segmentation dataset인 PerSeg
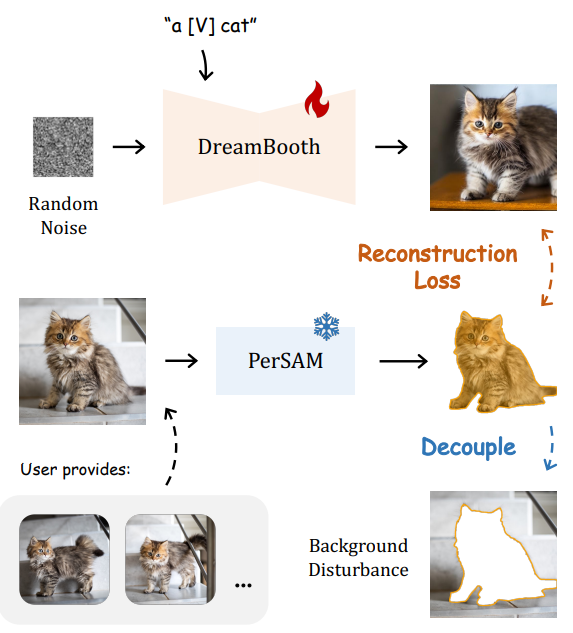
- Better Personalization of Stable Diffusion : DreamBooth와 같은 확산 finetuning 작업을 개선할 수 있음

Method
A Revisit of Segment Anything
SAM의 프롬프트 인코더 EncP
이미지 인코더 EncI
디코더 DecM
입력 이미지 I, 프롬프트 P


TM은 output token으로 DETR에서의 object query와 같은 역할.
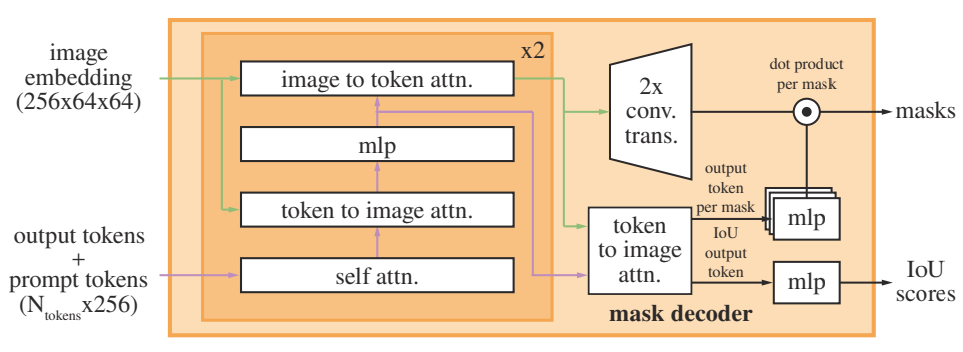
Training-free PerSAM
Positive-negative Location Prior
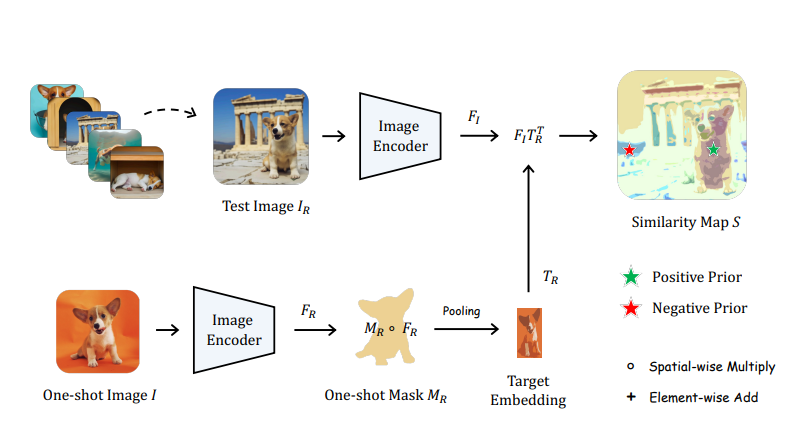
사용자 제공 이미지와 마스크를 이용하여 target embedding을 도출,
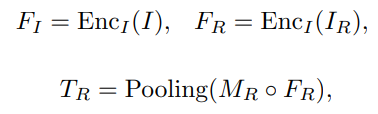
코사인 유사성을 이용하여 신뢰도 맵을 얻고
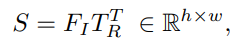
가장 신뢰도가 높은 점과 낮은 점을 각각 positive, negative point로 간주하여 SAM에 전달

Target-guided Attention
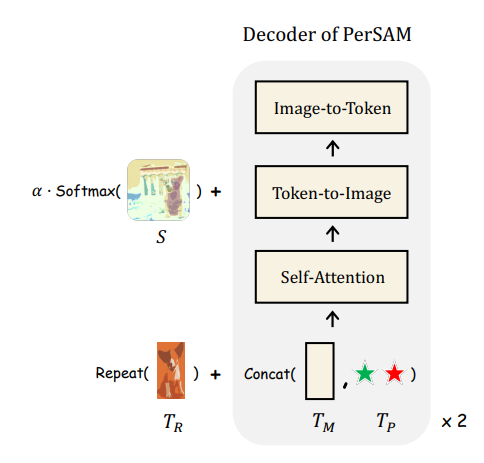
Cross attention 계층의 softmax 함수 이후의 attention map을 A라고 할 때, 신뢰도 맵 S로 A를 변조
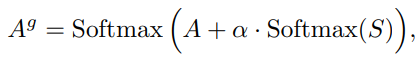
Target-semantic Prompting
SAM 디코더의 모든 비 이미지 입력 토큰에 시각적 임베딩 추가

Cascaded Post-refinement
SAM 디코더의 출력을 다시 프롬프트로 사용하여 반복적으로 정제
Fine-tuning of PerSAM-F
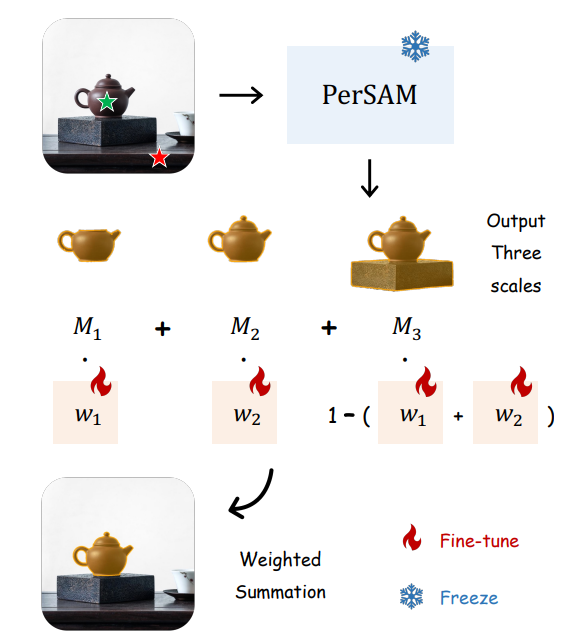
다음과 같이 '주전자'의 범위를 어디까지 인정해야 하냐는 모호성 문제가 있다. 이건 SAM 논문에서도 논의되었던 주제인데, SAM에서는 최대 3개의 마스크를 같이 생성하는 것으로 해결하였지만, 그러면 3개 중 최종 마스크를 고르는 추가 인력이 필요하다.
또한 PerSAM은 자동화가 목적이기 때문에, 2개의 추가 피라미터를 도입하여 해결한다.

먼저 3개의 마스크를 출력하고,
각 w를 1/3로 초기화 한 뒤,
참조 이미지에 대해 10초 이내의 one-shot fine tuning을 하고 해당 결과를 ground truth로 간주함.
2개라는 매우 적은 피라미터를 선택한 것은 과적합을 방지하기 위함이다.
Better Personalization of Stable Diffusion
DreamBooth 및 Textual Inversion과 같은 모델 개인화 작업에서 PerSAM을 통해 background 정보를 버리고 foreground 정보만을 역전파 함으로써 더 나은 시각적 합성을 할 수 있음.
Experiment



'논문 리뷰 > Vision Transformer' 카테고리의 다른 글
| Matting Anything (MAM) (0) | 2023.06.15 |
|---|---|
| Matte Anything: Interactive Natural Image Matting with Segment Anything Models (MatAny) (1) | 2023.06.15 |
| Segment Anything in High Quality (HQ-SAM) (0) | 2023.06.10 |
| Inpaint Anything: Segment Anything Meets Image Inpainting (0) | 2023.04.19 |
| Segment Anything (SAM) (0) | 2023.04.09 |
| Token Merging: Your ViT But Faster (0) | 2023.04.06 |



