GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
High-Resolution Image Synthesis with Latent Diffusion Models - GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
github.com
High-Resolution Image Synthesis with Latent Diffusion Models (LDM)
Diffusion Model + Autoencoder + Cross Attention Github GitHub - CompVis/latent-diffusion: High-Resolution Image Synthesis with Latent Diffusion Models High-Resolution Image Synthesis with Latent Diffusion Models - GitHub - CompVis/latent-diffusion: High-Re
ostin.tistory.com
논문 부록 : AutoEncoder Details
AutoEncoder를 적대적 방식으로 훈련하여 패치 기반 판별기가 재구성 이미지 D(E(x))와 원본 이미지를 구별하도록 최적화.
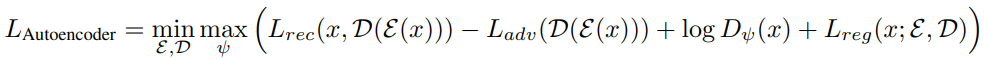
Discriminator와 loss function의 구현은 contperceptual.py에서 볼 수 있음.
정규화 방식은 두 가지가 있는데 VQ 방식의 경우
양자화 과정에서 발생하는 loss를 줄여 정규화,
class VQModel(pl.LightningModule):
def encode(self, x):
h = self.encoder(x)
h = self.quant_conv(h)
quant, emb_loss, info = self.quantize(h)
return quant, emb_loss, info
def decode(self, quant):
quant = self.post_quant_conv(quant)
dec = self.decoder(quant)
return dec
def forward(self, input, return_pred_indices=False):
quant, diff, (_,_,ind) = self.encode(input)
dec = self.decode(quant)
if return_pred_indices:
return dec, diff, ind
return dec, diff
def training_step(self, batch, batch_idx, optimizer_idx):
x = self.get_input(batch, self.image_key)
xrec, qloss, ind = self(x, return_pred_indices=True)
if optimizer_idx == 1:
# discriminator
discloss, log_dict_disc = self.loss(qloss, x, xrec, optimizer_idx, self.global_step,
last_layer=self.get_last_layer(), split="train")
self.log_dict(log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=True)
return discloss
KL 방식의 경우
정규 분포와의 Kullback-Leibler-term을 이용하여 정규화.
class DiagonalGaussianDistribution
class AutoencoderKL(pl.LightningModule):
def encode(self, x):
h = self.encoder(x)
moments = self.quant_conv(h)
posterior = DiagonalGaussianDistribution(moments)
return posterior
def decode(self, z):
z = self.post_quant_conv(z)
dec = self.decoder(z)
return dec
def forward(self, input, sample_posterior=True):
posterior = self.encode(input)
if sample_posterior:
z = posterior.sample()
else:
z = posterior.mode()
dec = self.decode(z)
return dec, posterior
def training_step(self, batch, batch_idx, optimizer_idx):
inputs = self.get_input(batch, self.image_key)
reconstructions, posterior = self(inputs)
if optimizer_idx == 1:
# train the discriminator
discloss, log_dict_disc = self.loss(inputs, reconstructions, posterior, optimizer_idx, self.global_step,
last_layer=self.get_last_layer(), split="train")
self.log("discloss", discloss, prog_bar=True, logger=True, on_step=True, on_epoch=True)
self.log_dict(log_dict_disc, prog_bar=False, logger=True, on_step=True, on_epoch=False)
return discloss
논문 부록 : Implementations of τθ
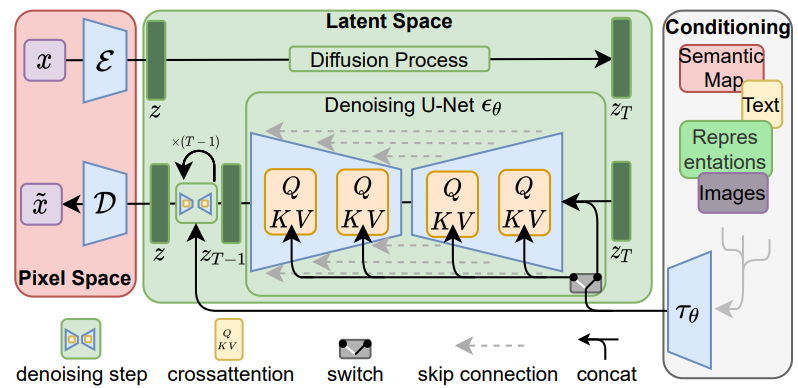
BERT tokenizer, CLIP embedder 등등 각종 전처리 모듈
τθ는 트랜스포머로 구현.

class TransformerWrapper(nn.Module):
def __init__(
self,
*,
num_tokens,
max_seq_len,
attn_layers,
emb_dim=None,
max_mem_len=0.,
emb_dropout=0.,
num_memory_tokens=None,
tie_embedding=False,
use_pos_emb=True
):
super().__init__()
assert isinstance(attn_layers, AttentionLayers), 'attention layers must be one of Encoder or Decoder'
dim = attn_layers.dim
emb_dim = default(emb_dim, dim)
self.max_seq_len = max_seq_len
self.max_mem_len = max_mem_len
self.num_tokens = num_tokens
self.token_emb = nn.Embedding(num_tokens, emb_dim)
self.pos_emb = AbsolutePositionalEmbedding(emb_dim, max_seq_len) if (
use_pos_emb and not attn_layers.has_pos_emb) else always(0)
self.emb_dropout = nn.Dropout(emb_dropout)
self.project_emb = nn.Linear(emb_dim, dim) if emb_dim != dim else nn.Identity()
self.attn_layers = attn_layers
self.norm = nn.LayerNorm(dim)
self.init_()
self.to_logits = nn.Linear(dim, num_tokens) if not tie_embedding else lambda t: t @ self.token_emb.weight.t()
def init_(self):
nn.init.normal_(self.token_emb.weight, std=0.02)
def forward(
self,
x,
return_embeddings=False,
mask=None,
return_mems=False,
return_attn=False,
mems=None,
**kwargs
):
b, n, device, num_mem = *x.shape, x.device, self.num_memory_tokens
x = self.token_emb(x)
x += self.pos_emb(x)
x = self.emb_dropout(x)
x = self.project_emb(x)
x, intermediates = self.attn_layers(x, mask=mask, mems=mems, return_hiddens=True, **kwargs)
x = self.norm(x)
mem, x = x[:, :num_mem], x[:, num_mem:]
out = self.to_logits(x) if not return_embeddings else x
return out
Cross attention
조건을 ablated U-Net에 주입하기 위해 U-Net의 self attention 계층을 T Block으로 구성된 트랜스포머로 교체한다.

#T Block
class BasicTransformerBlock(nn.Module):
def __init__(self, dim, n_heads, d_head, dropout=0., context_dim=None, gated_ff=True, checkpoint=True):
super().__init__()
self.attn1 = CrossAttention(query_dim=dim, heads=n_heads, dim_head=d_head, dropout=dropout) # is a self-attention
self.ff = FeedForward(dim, dropout=dropout, glu=gated_ff)
self.attn2 = CrossAttention(query_dim=dim, context_dim=context_dim,
heads=n_heads, dim_head=d_head, dropout=dropout) # is self-attn if context is none
self.norm1 = nn.LayerNorm(dim)
self.norm2 = nn.LayerNorm(dim)
self.norm3 = nn.LayerNorm(dim)
self.checkpoint = checkpoint
def forward(self, x, context=None):
return checkpoint(self._forward, (x, context), self.parameters(), self.checkpoint)
def _forward(self, x, context=None):
x = self.attn1(self.norm1(x)) + x
x = self.attn2(self.norm2(x), context=context) + x
x = self.ff(self.norm3(x)) + x
return x
class SpatialTransformer(nn.Module):
"""
Transformer block for image-like data.
First, project the input (aka embedding)
and reshape to b, t, d.
Then apply standard transformer action.
Finally, reshape to image
"""
def __init__(self, in_channels, n_heads, d_head,
depth=1, dropout=0., context_dim=None):
super().__init__()
self.in_channels = in_channels
inner_dim = n_heads * d_head
self.norm = Normalize(in_channels)
self.proj_in = nn.Conv2d(in_channels,
inner_dim,
kernel_size=1,
stride=1,
padding=0)
self.transformer_blocks = nn.ModuleList(
[BasicTransformerBlock(inner_dim, n_heads, d_head, dropout=dropout, context_dim=context_dim)
for d in range(depth)]
)
self.proj_out = zero_module(nn.Conv2d(inner_dim,
in_channels,
kernel_size=1,
stride=1,
padding=0))
def forward(self, x, context=None):
# note: if no context is given, cross-attention defaults to self-attention
b, c, h, w = x.shape
x_in = x
x = self.norm(x)
x = self.proj_in(x)
x = rearrange(x, 'b c h w -> b (h w) c')
for block in self.transformer_blocks:
x = block(x, context=context)
x = rearrange(x, 'b (h w) c -> b c h w', h=h, w=w)
x = self.proj_out(x)
return x + x_in'코드 리뷰 > Diffusion' 카테고리의 다른 글
| DiffStyler 코드 리뷰 (0) | 2023.01.16 |
|---|---|
| Paint by Example 코드 리뷰 (1) | 2023.01.15 |
| DAAM 코드 리뷰 (1) | 2023.01.12 |
| Classifier-Guidance Diffusion (1) | 2022.12.07 |
| Improved DDPM (0) | 2022.09.28 |
| Denoising Diffusion Pytorch (1) | 2022.09.25 |


