확산 모델에 트랜스포머 백본. JAX로 구현됨.

Abstract
확산 모델에서 일반적으로 사용되는 U-Net 백본을 잠재 패치에서 작동하는 트랜스포머로 대체한다.
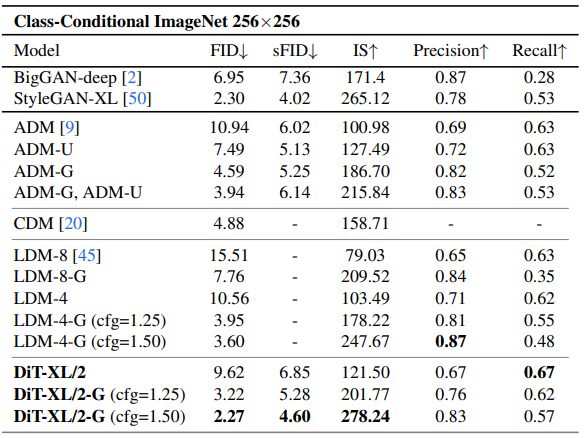
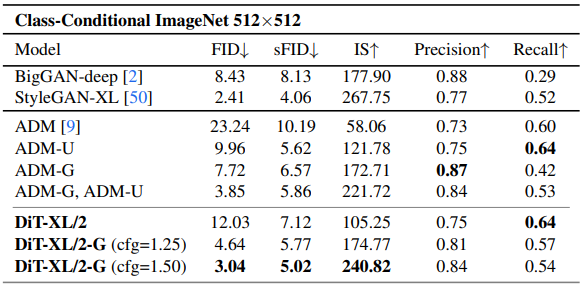
트랜스포머의 깊이/폭 증가 또는 입력 토큰의 증가가 더 낮은 FID를 갖는다는 것을 발견하였으며 class-conditional ImageNet 512, 256에서 이전의 모든 확산 모델을 능가한 2.27 FID를 달성하였다.
Introduction
본 연구에서는 U-Net의 유도 편향이 확산 모델의 성능에 중요하지 않으며, 트랜스포머와 같은 표준 설계로 쉽게 대체될 수 있음을 보여준다. 또한 트랜스포머를 기반으로 한 새로운 확산 모델인 Diffusion Transformer(DiT)를 소개한다.
LDM(=stable diffusion) 프레임워크 하에서 DiT 설계 공간을 구성하고 벤치마킹함으로써 U-Net을 성공적으로 대체할 수 있다는 것을 보여준다.
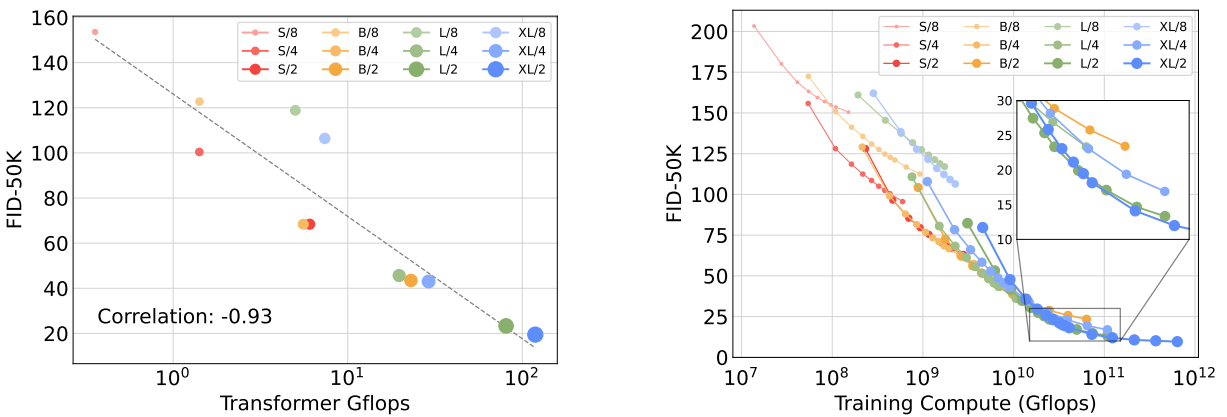
네트워크 복잡성과 샘플 품질 사이에는 강한 상관관계가 있다.
Diffusion Transformers
Preliminaries
Latent Diffusion Model(LDM, Stable Diffusion)
Diffusion Transformer Design Space

Patchify
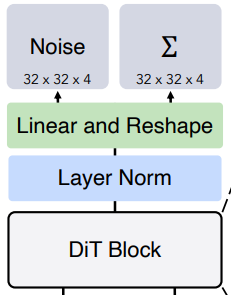
오토인코더의 출력인 z(32x32x4)를 d차원 토큰으로 변환하고 위치임베딩
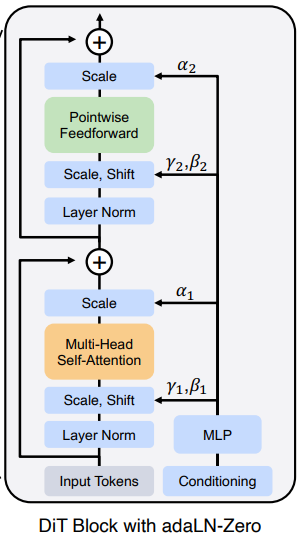
DiT block design
In-context conditioning : t와 c의 벡터 임베딩을 일반 토큰으로 추가 (맨 오른쪽)
Cross-attention block : LDM을 포함해 조건 입력을 위해 범용적으로 사용되는 cross attention. 15% 오버헤드. (중간)
Adaptive layer norm (adaLN) block : 적응형 정규화. 가장 적은 오버헤드 추가.
AdaLN-Zero block:
확산 모델의 U-Net에서 잔차 연결 직전 각 블록의 최종 컨볼루션 레이어를 0으로 초기화한다. 이는 잔차 블록을 ID로 만들고 훈련을 가속화하는 데 효과가 있다. DiT 블록에서 똑같이 함. 또한 잔차 연결 직전 적응형 스케일링 매개변수 α 추가.
모든 α에 대해 영벡터를 출력하도록 MLP 초기화. 이는 DiT 블록이 ID로 초기화되도록 함.
Transformer decoder
각 토큰을 p x p x 2C 형태로 디코딩하고 최종 예측 노이즈와 공분산을 얻기 위해 재배열.
Experimental Setup
p = 2,4,8
Adam W
학습 속도 0.0001 고정
0.9999의 감쇠로 EMA유지
배치 256
증강은 hflip만
학습 속도 워밍업이나 특별한 트릭 없이도 안정적으로 훈련됐다고 함
ADM의 확산 하이퍼 피라미터 유지
JAX로 구현
Experiments