[arXiv](2024/03/11 version v1)
Abstract
단일 GPU 상용 서버에서 대규모 모델을 fine-tuning 할 수 있도록 ZeRO-Infinity를 개선한 Fuyou 제안
Background
Memory Footprint
Gradient는 역전파 단계에서 활성화와 오류 값에 대해 계산되며 최적화 단계에서 소비된다. 따라서 활성화는 역전파 단계에서 소비되며 parameter, optimizer state는 훈련 과정 전반에 걸쳐 유지된다.
Activation Checkpointing

또한 메모리를 절약하기 위해 활성화를 heterogeneous storage에 offload 하고 역전파 시 가져올 수 있다.
ZeRO (Zero Redundancy Optimizer)
최적화 단계는 CPU에서 수행된다.
Motivation
ZeRO-Infinity는 고급 서버용으로 설계되어 단일 GPU의 상용 서버에서는 비효율적이다.
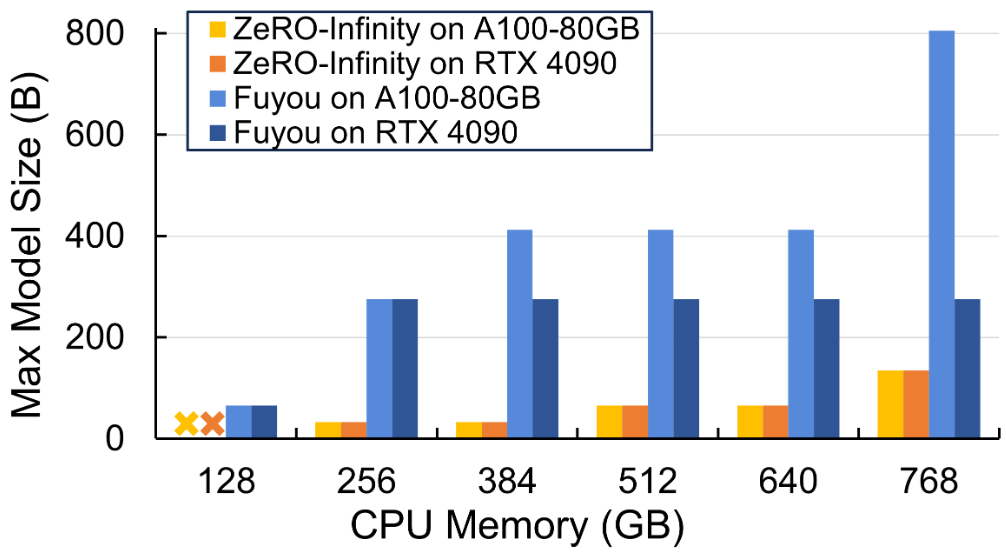
Supporting Limited Trainable Model Size under Limited CPU Memory Capacity
ZeRO-Infinity는 활성화를 CPU로 offload 하기 때문에 CPU 메모리 용량에 따라 학습 가능한 모델 크기가 제한된다.
Low GPU Utilization when Fine-tuning a Small Model on a Single GPU
소형 모델을 fine-tuning 할 때 GPU 활용도가 낮다.

Design of Fuyou
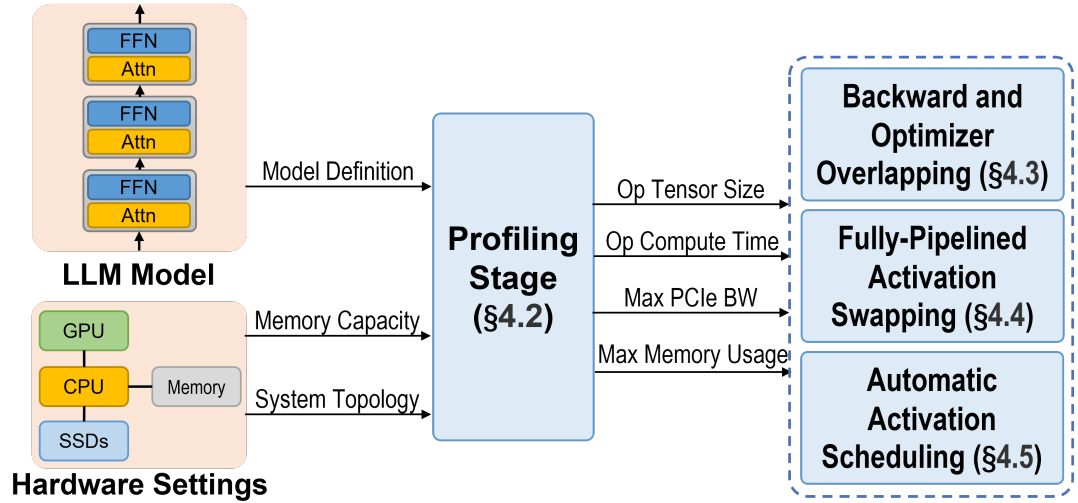
Profiling Stage
Pytorch hooks를 통해 각 연산자에 대한 활성화 및 피라미터의 크기, 계산 시간을 기록한다. 또한 각 하드웨어의 메모리 용량을 가져오고 CPU, GPU 메모리 사용량을 모니터링한다.
Fully Pipelined Activation Swapping
계산과 통신을 최대한 중첩시킨다. (b)
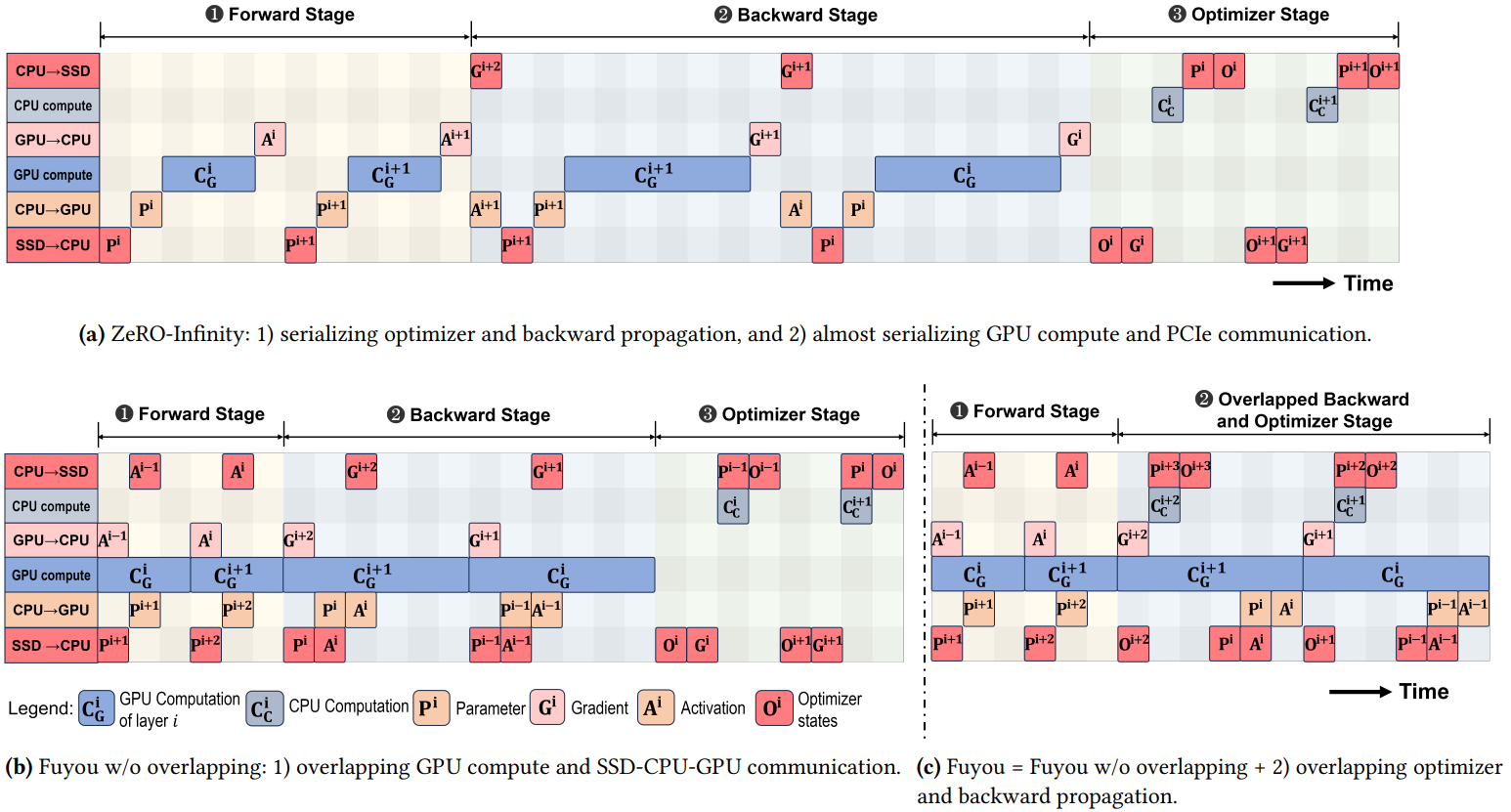
훈련 가능한 모델 크기를 손상시키지 않고 실행 전략을 효율적으로 구현하기 위해 프로파일링 단계에서 얻은 최고 GPU 메모리 활용률을 이용하여 나머지 메모리 공간을 FIFO 버퍼로 활용하는 FIFO prefetching mechanism을 제안한다.
- 버퍼가 비어있을 때마다 GPU 활용도를 극대화하기 위해 활성화, 피라미터를 미리 가져온다.
- 현재 모듈에 필요한 데이터를 prefetch 대기열에서 간단히 검색할 수 있다.
Backward Propagation and Optimizer Overlapping
SSD I/O를 제외하면 역전파와 최적화는 완전히 다른 리소스를 사용한다. 따라서 두 단계를 최대한 중첩한다. (c)
중첩 시 전체 SSD I/O 횟수 또한 줄일 수 있어 더욱 효율적인 훈련이 가능하다.
Automatic Activation Scheduling
활성화를 SSD에 저장하며 CPU 메모리가 충분한 경우 연산 복잡도와 활성화 크기를 고려하여 CPU 또는 SSD에 저장한다.
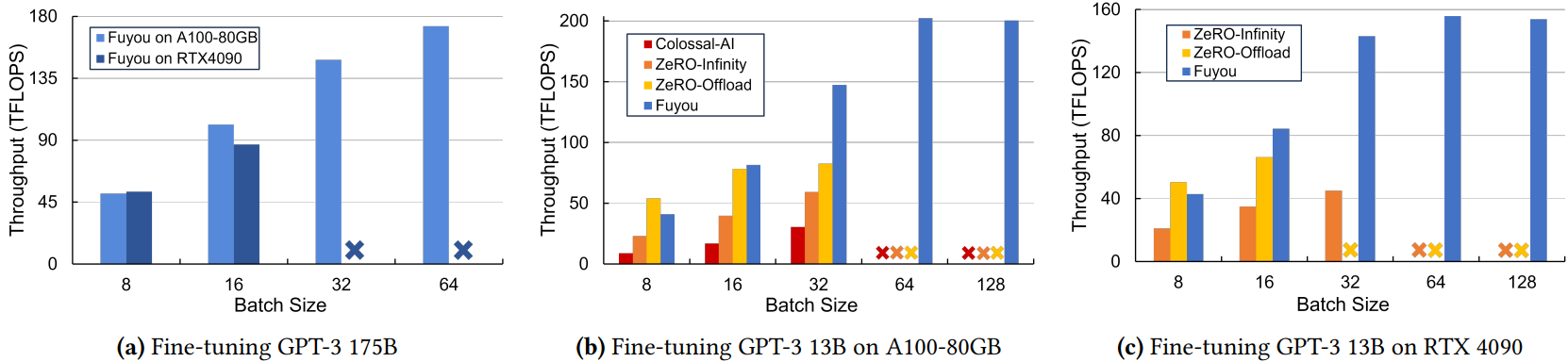
Evaluation
훈련 가능한 최대 모델 크기
End-to-End GPU 처리량