Constitutional DPO in Weaver: Foundation Models for Creative Writing
Instruction Backtranslation
사람이 쓴 고품질의 stylish한 text에 weaver를 조정하기 위해 self-instruction 대신 instruction backtranslation을 수행.

각 subdomain-task 쌍에 대해 instruction-response 쌍을 작성하는 방법에 대한 5가지 사례에 주석을 단다. (다듬기의 경우 범위를 선택하고 문구나 구조를 수정하여 나쁘게 만들기)
GPT-4에 few-shot으로 각 사례와 주석, 주석 처리의 근거를 제공하고 Chain-of-thought (CoT) 추론을 통해 주석 프로세스와 instruction-response 쌍을 생성하도록 요청.
50만 개의 instruction-response 쌍을 생성하고 GPT-3.5-Turbo로 점수를 매긴 다음, 최고 순위의 데이터를 통해 SFT를 수행한다.
Constitutional DPO: Learning From Principled Negative Examples
실제로 전문가가 다양한 원칙을 작성하고 각 원칙에 대한 준수 사례와 위반 사례 수집, 위반 이유까지 수집한다.
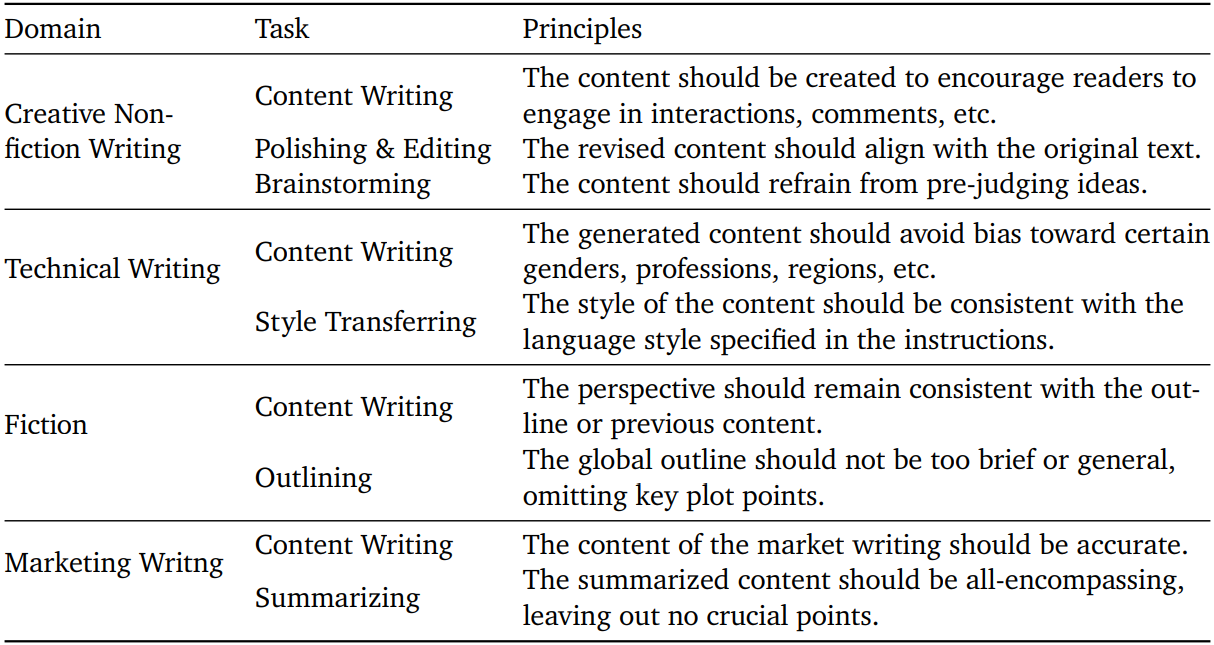
Backtranslation 단계에서 가장 높은 점수를 받은 instruction data를 샘플링한 뒤, task에 대한 원칙을 제시하고 어떤 원칙이 품질이 좋은 이유를 가장 잘 설명할 수 있는지 GPT에 분석을 요청한다. 또한 최소한의 수정을 추가하여 원칙을 위반하는 응답을 생성하도록 한다.
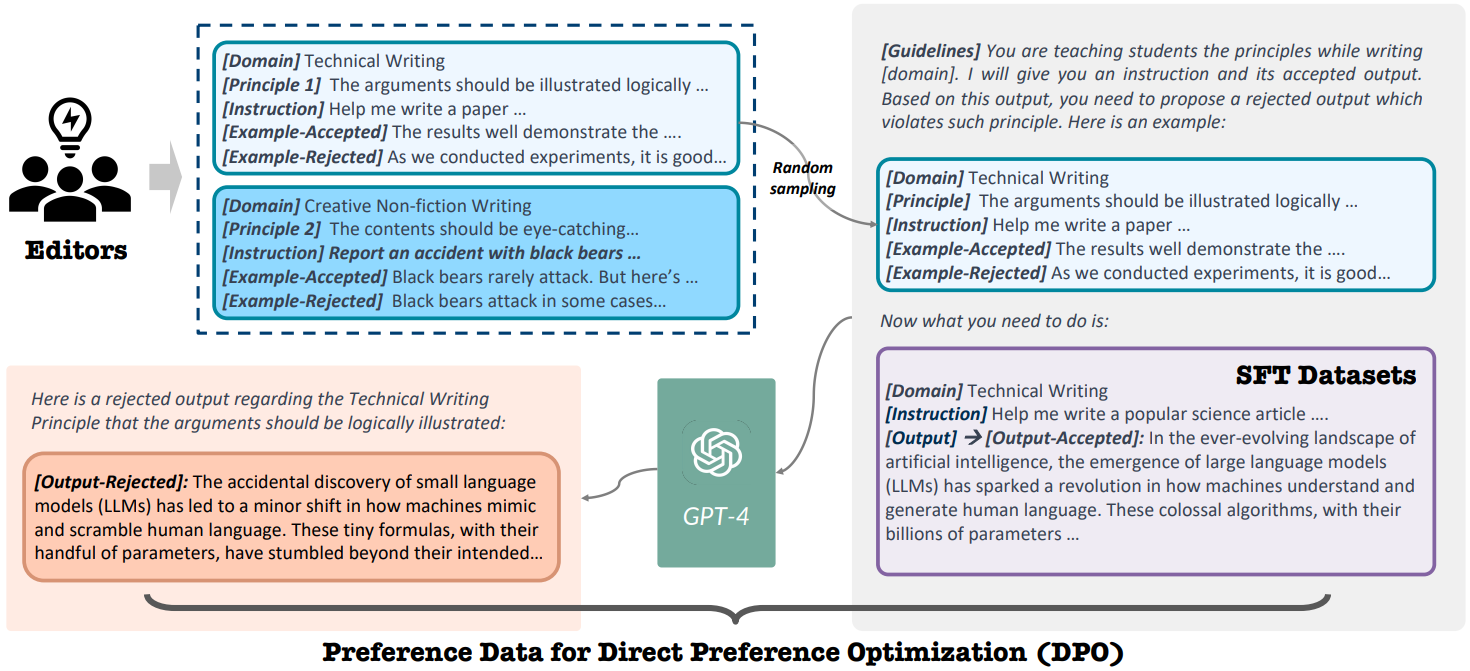
해당 응답 쌍을 통해 DPO 학습을 진행한다.
'논문 리뷰 > Concept' 카테고리의 다른 글
| Rotary Position Embedding (RoPE) (0) | 2024.03.04 |
|---|---|
| Self-Conditioning (1) | 2023.12.17 |
| R1 Gradient Penalty (1) | 2023.12.01 |
| Score Distillation Sampling (1) | 2023.11.30 |



