Multi-reward 간에 Pareto 최적인 샘플만 훈련에 사용
[arXiv](2024/01/11 version v1)

Abstract
Text-to-Image generation을 위한 multi-reward Reinforcement Learning framework인 Parrot 소개.
Pareto optimal selection을 사용하여 reward 간의 균형을 맞추기 때문에 Parrot이라는 이름을 붙였다.
Preliminary
보상 모델 r의 목적 함수 J:

사전 훈련된 확산 모델 pθ에 대해 표기:

Method
Parrot Overview
Parrot은 Prompt Expansion Network(PEN)와 T2I model로 구성된다.
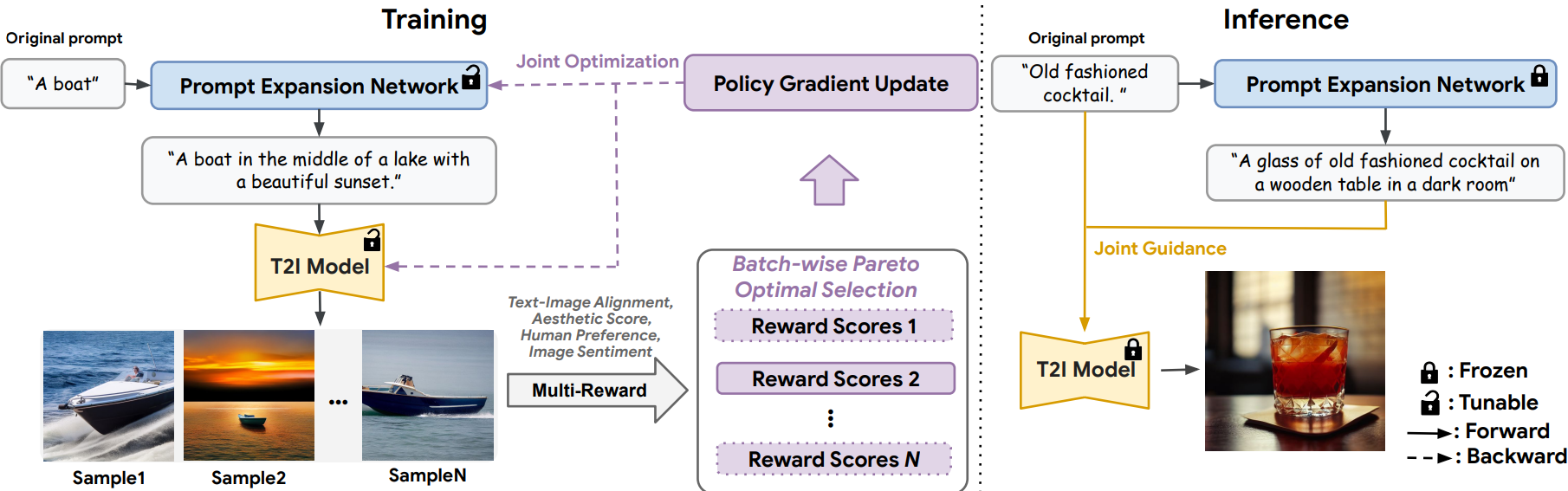
Batch-wise Pareto-optimal Selection
전체 알고리즘:

Reward-specific Preference
단순한 prompt는 상세한 이미지를 생성하지 못하기 때문에 prompt를 확장하고, 확장된 prompt ĉ 앞에 보상 식별자 "<reward k>"를 붙인 다음 이 prompt를 기반으로 N개의 이미지를 생성한다.
추론 시에는 모든 보상 식별자를 사용한다. "<reward 1>,... , <reward k>"
Non-dominated Sorting
N개의 이미지에 대해 multiple reward models로 평가하고 파레토 최적인 non-dominated set을 찾는다.

Policy Gradient Update
모든 reward models K, 모든 timesteps T에 대해 non-dominated set의 샘플의 gradient만 업데이트한다.
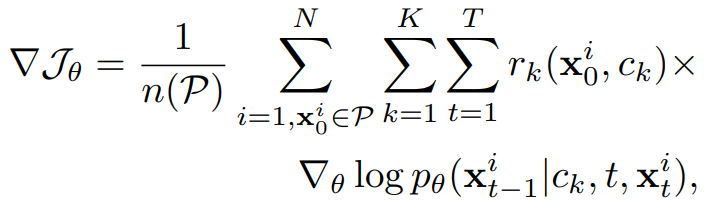
Original Prompt Centered Guidance
Prompt 확장에 의해 원래 prompt의 의미가 희석될 수 있다. 따라서 두 prompt의 선형 조합을 통해 노이즈를 예측한다.

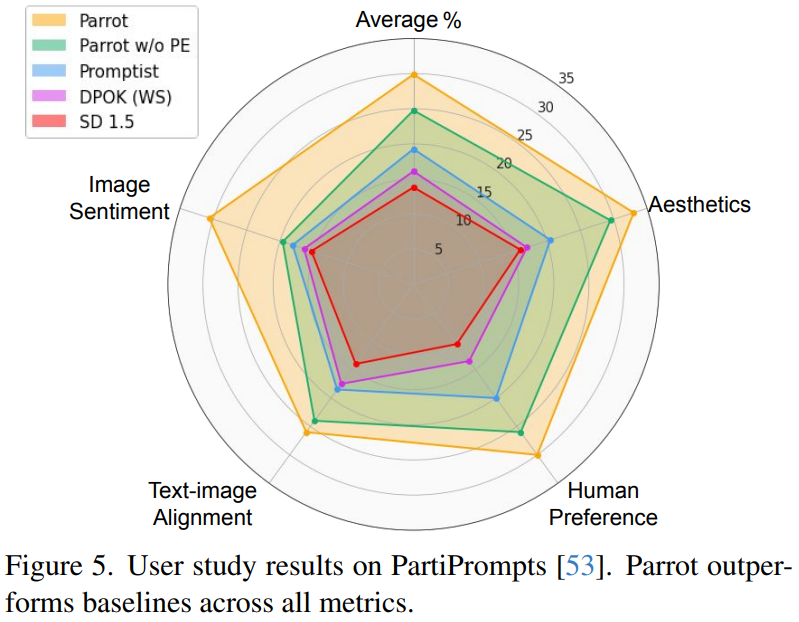
Experiments



'논문 리뷰 > Diffusion Model' 카테고리의 다른 글
| Delta Denoising Score (DDS) (1) | 2024.01.19 |
|---|---|
| Object-Centric Diffusion for Efficient Video Editing (1) | 2024.01.18 |
| FateZero: Fusing Attentions for Zero-shot Text-based Video Editing (0) | 2024.01.18 |
| Score Distillation Sampling with Learned Manifold Corrective (LMC-SDS) (0) | 2024.01.16 |
| Progressive Knowledge Distillation Of Stable Diffusion XL Using Layer Level Loss (1) | 2024.01.10 |
| BK-SDM: A Lightweight, Fast, and Cheap Version of Stable Diffusion (0) | 2024.01.10 |



