+ Mamba에 대해 매우 잘 설명되어 있는 글 ← 그냥 이거 보세요
SSM에 선택성을 부여하고 하드웨어 최적화
[Github]
[arXiv](2023/12/01 version v1)
Abstract
Transformer 기반 모델들이 긴 시퀀스 처리에서 보여주는 계산 비효율성을 해결하기 위해 Mamba라는 새로운 신경망 구조를 제안
State Space Models
Efficiently Modeling Long Sequences with Structured State Spaces (S4)
[arXiv](2022/08/05 version v3) 영어 잘하시면 이거 보세요. https://srush.github.io/annotated-s4/ 근데 솔직히 원어민도 이거 보고 이해 못 할 듯; The Annotated S4 srush.github.io 시작하기 전에 말하자면 이 논문에 관
ostin.tistory.com
표기가 살짝 다르고(state h(t), input x) 피라미터가 4개입니다. (∆, A, B, C)

Discretization
이산 시간 피라미터는 연속 시간 피라미터 A, B로 나타낼 수 있다.
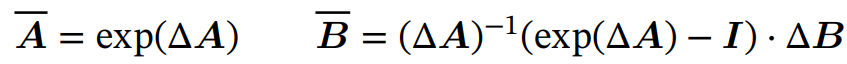
Computation
전체 입력 시퀀스를 미리 볼 수 있는 경우 convolution mode(3a, 3b)를 사용하고 한 번에 한 timestep만 볼 수 있는 경우 recurrent mode(2a, 2b)로 전환한다.
Linear Time Invariance (LTI)
방정식 (1~3)의 중요한 특성은 모델의 dynamics가 시간에 따라 일정하다는 것이다.
이를 Linear Time-Invariant(LTI, 시불변성)이라고 한다.

지금까지 모든 structured SSM은 LTI였다.
그러나 본 논문의 핵심 통찰은 LTI 제약을 제거하는 것과 관련이 있다.
Structure and Dimensions
Structured SSM이라는 이름이 붙여진 이유는 SSM을 효율적으로 계산하기 위해 A에 구조를 부여해야 했기 때문이다. 가장 널리 사용되는 구조는 대각선이며, 본문에서도 이를 사용한다.
그럴 경우 A ∈ ℝN×N, B ∈ ℝN×1, C ∈ ℝ1×N이고 batch size B, length L, channels D인 시퀀스 x에 대해 작동하려면 SSM이 각 채널에 독립적으로 적용되어야 하며 hidden state가 DN이 되고, 이는 병목 현상의 근원이다. 요컨대 차원이 부족해서.
Selective State Space Models
- Motivation: Selection as a Means of Compression
- Improving SSMs with Selection
- Efficient Implementation of Selective SSMs
- A Simplified SSM Architecture
- Properties of Selection Mechanisms
Motivation: Selection as a Means of Compression
시퀀스 모델은 efficiency vs effectiveness의 trade-off가 중요하다.
Attention은 context를 전혀 압축하지 않기 때문에 효과적이지만 비효율적이다.
LTI 모델은 효율적이지만 내용 인식이 부족하여 아래 그림의 오른쪽과 같이 입력과 출력 사이의 간격이 다양하고 정보를 선택적으로 취합해야 하는 경우를 모델링할 수 없다.

Improving SSMs with Selection
추가 차원을 받아들이고 시가변성, 선택성을 부여하기 위해 linear projection을 도입하였다. 이전까지의 피라미터는 단순 행렬.


Efficient Implementation of Selective SSMs
Motivation of Prior Models
Hidden state dimension이 큰 모델은 효과적이지만 비효율적이다. 효율성을 저하시키지 않고 hidden state dimension을 최대화하고자 한다.
Recurrent mode는 convolution mode보다 유연하지만 hidden state를 계산해야 하므로 이를 우회할 수 있는 convolution mode는 일반적으로 더 효율적이다.
Overview of Selective Scan: Hardware-Aware State Expansion
Recurrent는 O(BLDN) FLOPs를 사용하고 convolution은 O(BLDlog(L)) FLOPs를 사용하기 때문에 L이 충분히 크고 N이 크지 않은 경우, recurrent가 실제로 더 적은 FLOPs를 사용할 수도 있다.
한 가지 문제는, recurrent의 hidden state 계산으로 인해 메모리 사용이 많다는 점이다.
- Kernel Fusion: 스캔 입력 (Ā, B̄)를 느린 GPU HBM에서 준비하는 대신 SRAM으로 피라미터 (∆, A, B, C)를 직접 로드하고 이산화, 스캔, C와의 곱셈을 하나의 커널로 융합하여 모두 SRAM에서 수행한 뒤 출력을 HBM에 기록하는 방식으로 memory I/O를 크게 줄인다.
- Recomputation: 순전파 시 역전파에 필요한 intermediate state를 저장하지 않고 역전파 시 재계산함으로써 메모리 사용량을 줄인다.

A Simplified SSM Architecture
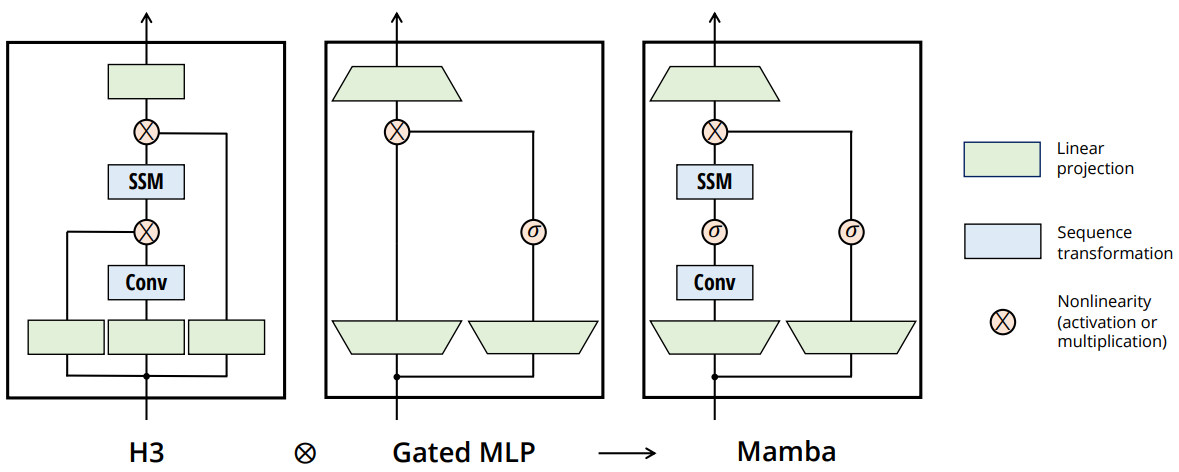
입력 projection에서 모델 차원을 확장한 두 개의 mamba block stack이 MHA과 MLP가 있는 transformer block 하나의 피라미터 수와 맞먹는다. transformer처럼 원하는 만큼 쌓으면 되는 것으로 보인다.
대부분의 피라미터는 projection에 존재하고 SSM의 피라미터의 비중은 훨씬 적으며, SiLU 활성화 사용.
실험 및 잡다한 이야기들 생략~



