초저비용 환경에서 최대의 학습 효율 내기
인용 논문을 그냥 지나칠 수 없는 성격 때문에 리뷰했지만 사실 별로 중요한 논문은 아닌...
[Github]
[arXiv](Current version v1)
[BERT]
Abstract
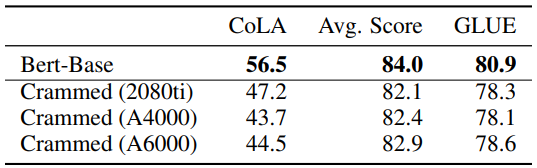
최근에 언어 모델링 추세는 성능 향상에 집중하고 있으며, 이는 실무자가 언어 모델을 훈련하기 불가능한 환경을 초래했다. 본문에서는 단일 GPU에서 하루 동안 masked language modeling으로 처음부터 훈련된 BERT류 모델로 달성할 수 있는 downstream performance를 조사한다.
Tying Our Hands Behind Our Back: A Setup with Limited Compute
- Masked language modeling으로 처음부터 훈련되는 transformer 기반 모델
- 어떤 방식으로든 사전 훈련 모델은 사용할 수 없음
- 다운스트림 데이터를 제외한 모든 텍스트를 훈련에 포함 가능 (데이터 품질을 통한 개선 가능)
- 원시 데이터의 다운로드 및 전처리는 총예산에 미포함 (단어 임베딩 사전 훈련 등의 표현 학습은 포함)
- 24시간 동안 단일 GPU에서 진행
- 5 epochs 이하의 간략한 fine-tuning(예산 미포함) 후 GLUE에서 평가됨
Investigations
Implementation details
대부분 pytorch로 구현.
English tokenizer(WordPiece) 처음부터 만듦.
단일 epochs 훈련.
Modifying the architecture
Scaling laws hold in the low-resource regime
Scaling Laws for Neural Language Models에서도 언급했듯이, 모델의 구조적 하이퍼 피라미터의 변화는 성능에 크게 기여하지 못했다.

Exploiting the scaling law
Scaling law를 통해 모델의 경량화가 저비용 환경에 대한 주요 해결책이 아니라는 것을 알 수 있다.
따라서 크기 조정 대신 동일한 모델 크기에 대해 계산 속도를 높이기 위한 조정을 탐색한다.
Attention Block
Q, K, V의 bias를 비활성화하여 gradient 계산 가속화.
Feedforward Block
Linear layer의 bias 비활성화. Gated Linear Unit을 사용하여 약간의 개선.
다른 논문에서 GLU를 사용한 그림. 대충 이렇게 사용된다는 느낌?
Embedding
Scaled sinusoidal positional embedding, 임베딩 끝에 레이어 정규화.
Layer Structure
Post-Layer Normalization 대신 Pre-LN 사용
Head Block
최종 layer norm을 추가하고 non-linear head 제거. 일부 토큰만 예측하는 sparse token prediction을 통해 메모리 절약. (다음 문장 예측 안 하고 MIM만 쓴다는 걸 이렇게 표현한 듯? 인용되어 있는 RoBERTa 논문에는 sparse token prediction이라는 단어가 없음;)
Modifying the training setup
원래 BERT의 설정은 cramming 환경에서 당연히 적절하지 않으므로 하이퍼 피라미터 변경.
근데 하이퍼 피라미터 변경 사항은 스킵할게요. 이건 언제든지 다를 수 있는 거라.
Optimizing the dataset
아까 언급한 대로 더 나은 데이터로 WordPiece tokenizer를 다시 구축, 데이터 필터링.
Fine-Tuning Performance on GLUE