인간의 학습 커리큘럼을 언어 모델에 적용
[Github]
[arXiv](Current version v1)
Chatbot UI
openchat.team
Abstract
인간 교육의 점진적이고 조직적인 특성을 모방하는 고도로 구조화된 합성 데이터 세트와 이를 이용한 교육 프레임워크인 CORGI(Cognitively hardest instructions) 제안
Introduction
언어 모델을 다양한 교육 기관으로부터 지식을 점진적으로 습득하려는 고등학생으로 개념화한다.
- Educational Stage: 초등 개념에서부터 복잡한 개념을 순차적으로 마스터
- Cognitive Hierarchy: 각 개념에 대한 이해를 점진적으로 심화
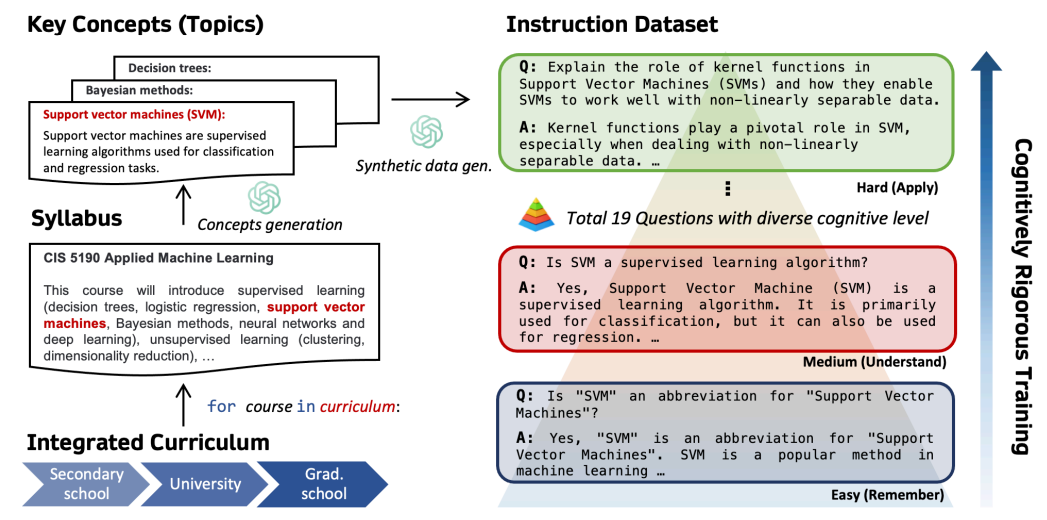
CORGI(Cognitively hardest instructions) 라는 instruction dataset training method를 선별.
국제 중등 교육 커리큘럼(i.e. Cambridge IGCSE curriculum)에서 제공하는 구체적인 교육 프레임워크와 여러 대학 카탈로그를 통합하여 교육 단계에서 지속적인 발전을 구축하고 chatGPT와 같은 교사 모델을 통해 다양한 주제를 추출하여 포괄적인 질문 세트를 만들었다.
CORGI
Dataset Construction
실제 교육 커리큘럼을 기본 소스로 교사 언어 모델을 활용하여 합성 데이터를 생성하는 방식 사용.
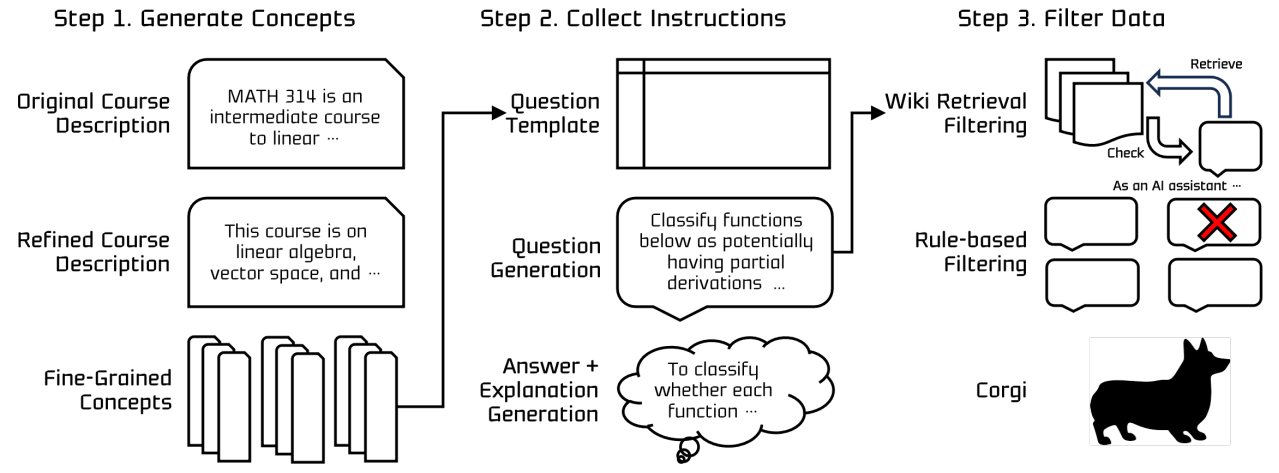
Step 1. Generate Concepts
강의 계획서를 기반으로 각 과정에 필요한 여러 학문적 개념을 추출하는 것이 목표이다. 그러나 초기 강의 계획서에는 종종 행정 용어 및 스케줄링과 같은 불필요한 세부 사항이 포함되어 있다.
학문적으로 의미 있는 세부 개념만을 추출하기 위해 전문화된 개선 프롬프트를 사용하여 5.6k 세부 개념 수집.
문장 변환기 라이브러리의 모델 all-MiniLM-L12-v2를 사용하여 의미론적 중복 제거.




Step 2. Collecting Instructions
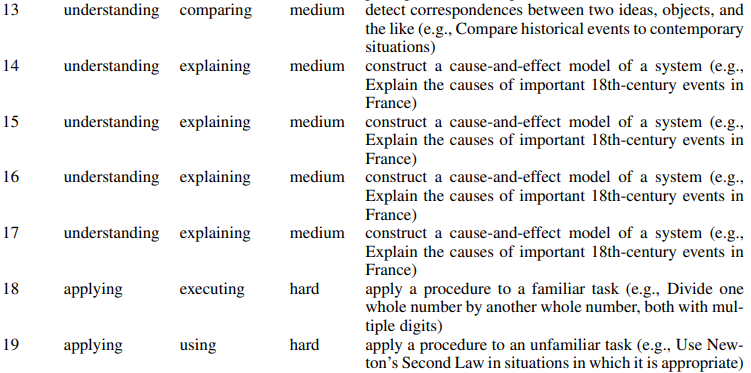
Bloom의 교육 목표 분류 체계에 따라 기억, 이해, 적용에 대한 교육 템플릿을 통해 교사 모델로 데이터 생성.
더 높은 인지 계층에 대해서는 주관적인 내용을 포함하거나 명확한 답이 없는 질문을 생성하기 때문에 사용하지 않음.
5.6k의 개념에 대해 107K 인지 계층 데이터셋 생성.









Step 3. Filter Data
중요한 것은 데이터셋이 교사 모델에 크게 의존한다는 것이다.
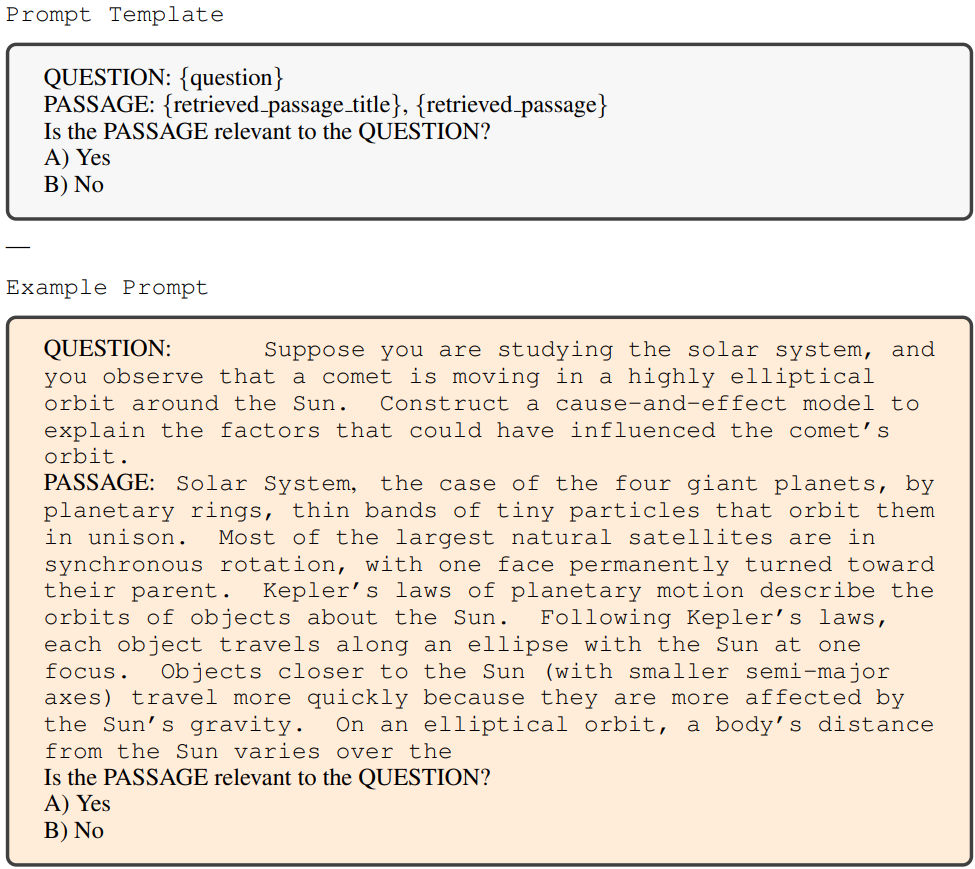
데이터의 품질을 보장하기 위해 Contriever를 사용하여 저품질 데이터를 필터링한다.
각 data instance에 대해 위키피디아에서 256개 단어의 개별 구절을 수집한 후 검색 확인 프롬프트를 사용하여 발췌문과 질문 간의 관련성을 평가하고 기준을 충족하는 데이터만 최종 데이터셋에 포함한다.

Curriculum Instruction Tuning
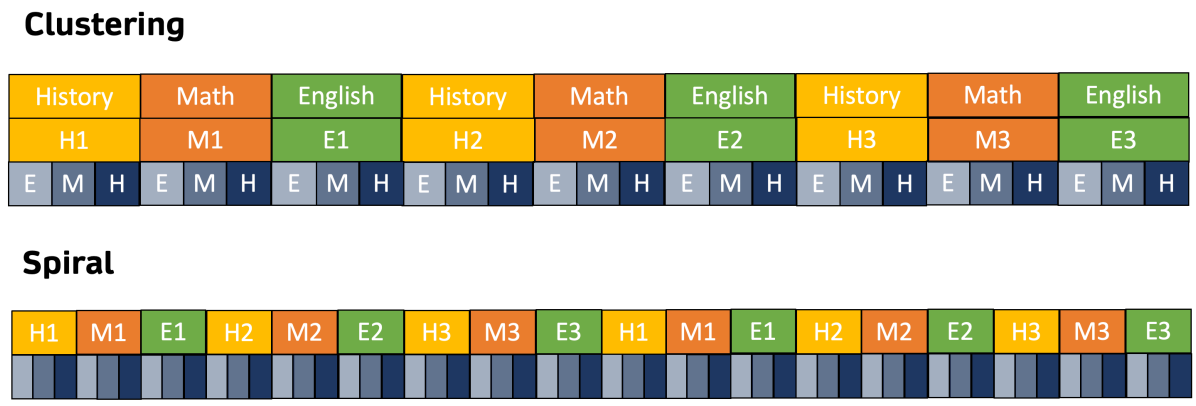
지식을 효율적으로 주입하기 위한 인지 훈련 방법.
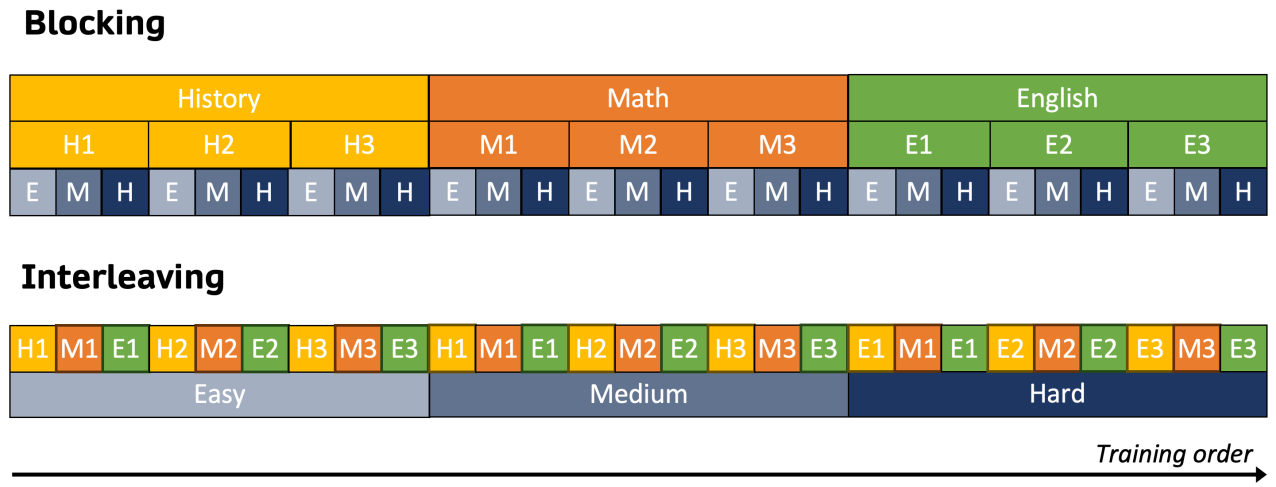
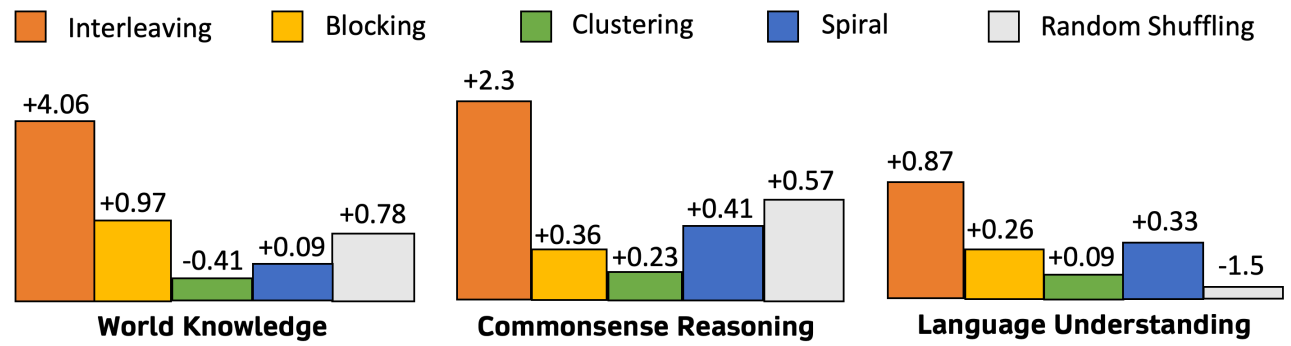
Blocking은 이전에 학습한 개념을 잊어버리는 인지 붕괴의 위험이 있어 interleaving 방법을 사용하여 훈련한다.
Experiments
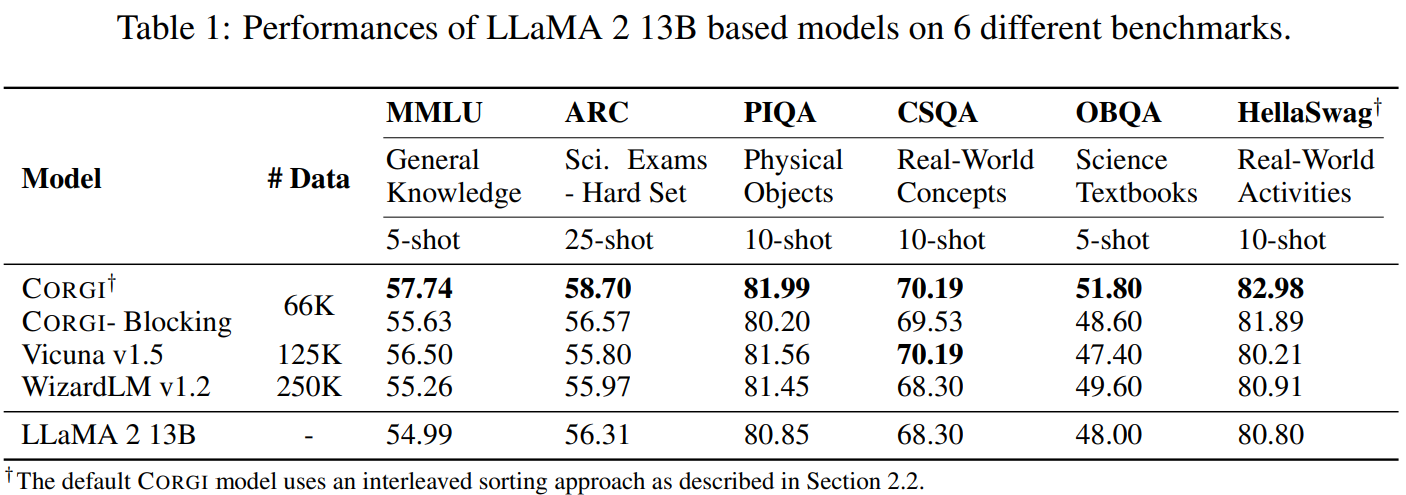
다른 훈련 방법과 비교